Откакто ClusterControl 1.2.11 беше пуснат през 2015 г., MariaDB MaxScale се поддържа като балансьор на натоварване на базата данни. През годините MaxScale се разраства и съзрява, добавяйки няколко богати функции. Наскоро беше пусната MariaDB MaxScale 2.2 и въвежда няколко нови функции, включително управление на отказ от клъстер за репликация.
MariaDB MaxScale позволява главен/подчинен разгръщане с висока наличност, автоматично превключване при отказ, ръчно превключване и автоматично повторно присъединяване. Ако главният не успее, MariaDB MaxScale може автоматично да промотира най-актуалния подчинен към главен. Ако неуспешният главен обект бъде възстановен, MariaDB MaxScale може автоматично да го преконфигурира като подчинен на новия главен. Освен това администраторите могат да извършват ръчно превключване, за да сменят главния при поискване.
В предишните ни блогове обсъдихме как да разположим MaxScale с помощта на ClusterControl, както и да разположим MariaDB MaxScale в Docker. За тези, които все още не са запознати с MariaDB MaxScale, това е усъвършенствано, добавка, прокси база данни за сървъри на бази данни на MariaDB. Maxscale седи между клиентски приложения и сървърите на базата данни, насочвайки клиентски заявки и отговори на сървъра. Той също така наблюдава сървърите, като бързо забелязва всякакви промени в състоянието на сървъра или топологията на репликация.
Въпреки че Maxscale споделя някои от характеристиките на други технологии за балансиране на натоварването като ProxySQL, тази нова функция за отказ (която е част от механизма за наблюдение и автоматично откриване) се откроява. В този блог ще обсъдим тази вълнуваща нова функция на Maxscale.
Общ преглед на механизма за отказване на MariaDB MaxScale
Основно разпознаване
Сега е по-малко вероятно мониторът да промени внезапно главния сървър, дори ако друг сървър има повече подчинени от текущия главен сървър. DBA може да принуди повторно избиране на главен, като настрои текущия главен само за четене или като премахне всички негови подчинени, ако главният не работи.
Само един сървър може да има флаг за състояние на главен в даден момент, дори и при настройка на мултимайстор. На други сървъри в групата на мултимайсторите се дават флаговете за статус на Relay Master и Slave.
Превключване на нов главен автоматичен избор
Командата за превключване вече може да се извиква само с името на екземпляра на монитора като параметър. В този случай мониторът автоматично ще избере сървър за промоция.
Откриване на забавяне на репликацията
Измерването на забавянето на репликацията сега просто отчита Seconds_Behind_Master -поле на изходния статус на подчинените устройства. Подчиненото устройство изчислява тази стойност, като сравнява времевата марка в събитието binlog, което ведомото в момента обработва, със собствения часовник на подчинения. Ако подчинен има няколко подчинени връзки, се използва най-малкото изоставане.
Автоматично превключване след откриване на ниско дисково пространство
С последните версии на MariaDB Server, мониторът вече може да провери дисковото пространство в бекенда и да открие дали сървърът е на изчерпване. Когато това се случи, мониторът може да се настрои да превключва автоматично от главен с малко дисково пространство. Подчинените могат също да бъдат настроени в режим на поддръжка. Дисковото пространство също е фактор, който се взема предвид при избора на кой нов главен файл да се популяризира.
Вижте switchover_on_low_disk_space и maintenance_on_low_disk_space за повече информация.
Функция за нулиране на репликация
Възстановяване-репликация командата monitor изтрива всички подчинени връзки и двоични регистрационни файлове и след това настройва репликация. Полезно, когато данните са синхронизирани, но gtid не са.
Обработка на планирани събития при отказ/превключване/повторно присъединяване
Събитията на сървъра, стартирани от нишката на планировчика на събития, вече се обработват по време на операции за промяна на клъстера. Вижте handle_server_events за повече информация.
Външна главна поддръжка
Мониторът може да открие дали сървър в клъстера се репликира от външен главен (сървър, който не се наблюдава от монитора на MaxScale). Ако репликиращият сървър е главният сървър на клъстера, тогава се счита, че самият клъстер има външен главен.
Ако се случи отказ/превключване, новият главен сървър е настроен да се репликира от външния главен сървър на клъстера. Потребителското име и паролата за репликацията са дефинирани в replication_user и replication_password. Използваните адрес и порт са тези, които се показват от ПОКАЖЕТЕ СТАТУСА НА ВСИЧКИ СЛАВЕ на стария главен сървър на клъстера. В случай на превключване, старият главен източник също спира да се репликира от външния сървър, за да запази топологията.
След преодоляване на отказ новият главен обект се репликира от външния главен. Ако неуспешният стар мастер се върне онлайн, той също се репликира от външния сървър. За да нормализирате ситуацията, или включете auto_rejoin, или изпълнете ръчно повторно присъединяване. Това ще пренасочи стария главен код към текущия главен елемент на клъстера.
Как е полезен и приложим отказът?
Отказът ви помага да сведете до минимум времето на престой, да извършвате ежедневна поддръжка или да се справите с катастрофална и нежелана поддръжка, която понякога може да възникне в неблагоприятни моменти. Със способността на MaxScale да изолира клиентски приложения от сървъри на бази данни, той добавя ценна функционалност, която помага за минимизиране на престоя.
Плъгинът за наблюдение MaxScale непрекъснато следи състоянието на сървърите за бази данни. След това плъгинът за маршрутизиране на MaxScale използва тази информация за състоянието, за да насочва винаги заявки към сървъри на бази данни, които са в експлоатация. След това той може да изпраща заявки към клъстерите на базата данни, дори ако някои от сървърите на клъстер преминават през поддръжка или имат повреда.
Високата конфигурируемост на MaxScale позволява промените в конфигурацията на клъстера да останат прозрачни за клиентските приложения. Например, ако нов сървър трябва да бъде административно добавен към или премахнат от главен-подчинен клъстер, можете просто да добавите конфигурацията на MaxScale към сървърния списък с плъгини за монитор и рутер чрез maxadmin CLI конзолата. Клиентското приложение няма да бъде напълно наясно с тази промяна и ще продължи да изпраща заявки към базата данни към порта за слушане на MaxScale.
Настройката на сървър на база данни в поддръжка е проста и лесна. Просто направете следната команда, като използвате maxctrl и MaxScale ще спре да изпраща всякакви заявки към този сървър. Например,
maxctrl: set server DB_785 maintenance
OKСлед това проверка на състоянието на сървърите, както следва,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬──────────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-70 │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-70 │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Maintenance, Running │ 0-43001-70 │
└────────┴───────────────┴──────┴─────────────┴──────────────────────┴────────────┘Веднъж в режим на поддръжка, MaxScale ще спре да насочва всички нови заявки към сървъра. За текущи заявки MaxScale няма да убие тези сесии, а по-скоро ще му позволи да завърши изпълнението си и няма да прекъсва изпълняваните заявки, докато е в режим на поддръжка. Също така имайте предвид, че режимът на поддръжка не е постоянен. Ако MaxScale се рестартира, когато възелът е в режим на поддръжка, нов екземпляр на MariaDB MaxScale няма да спазва този режим. Ако множество екземпляри на MariaDB MaxScale са конфигурирани да използват възела, техният режим на поддръжка трябва да бъде зададен във всеки екземпляр на MariaDB MaxScale. Въпреки това, ако няколко услуги в рамките на един екземпляр на MariaDB MaxScale използват сървъра, тогава трябва само веднъж да зададете режима на поддръжка на сървъра, за да могат всички услуги да забележат промяната на режима.
След като приключите с поддръжката си, просто изчистете сървъра със следната команда. Например,
maxctrl: clear server DB_785 maintenance
OKПроверете дали е върнато нормално, просто изпълнете командата list servers .
Можете също да приложите определени административни действия чрез потребителския интерфейс на ClusterControl. Вижте примерната екранна снимка по-долу:
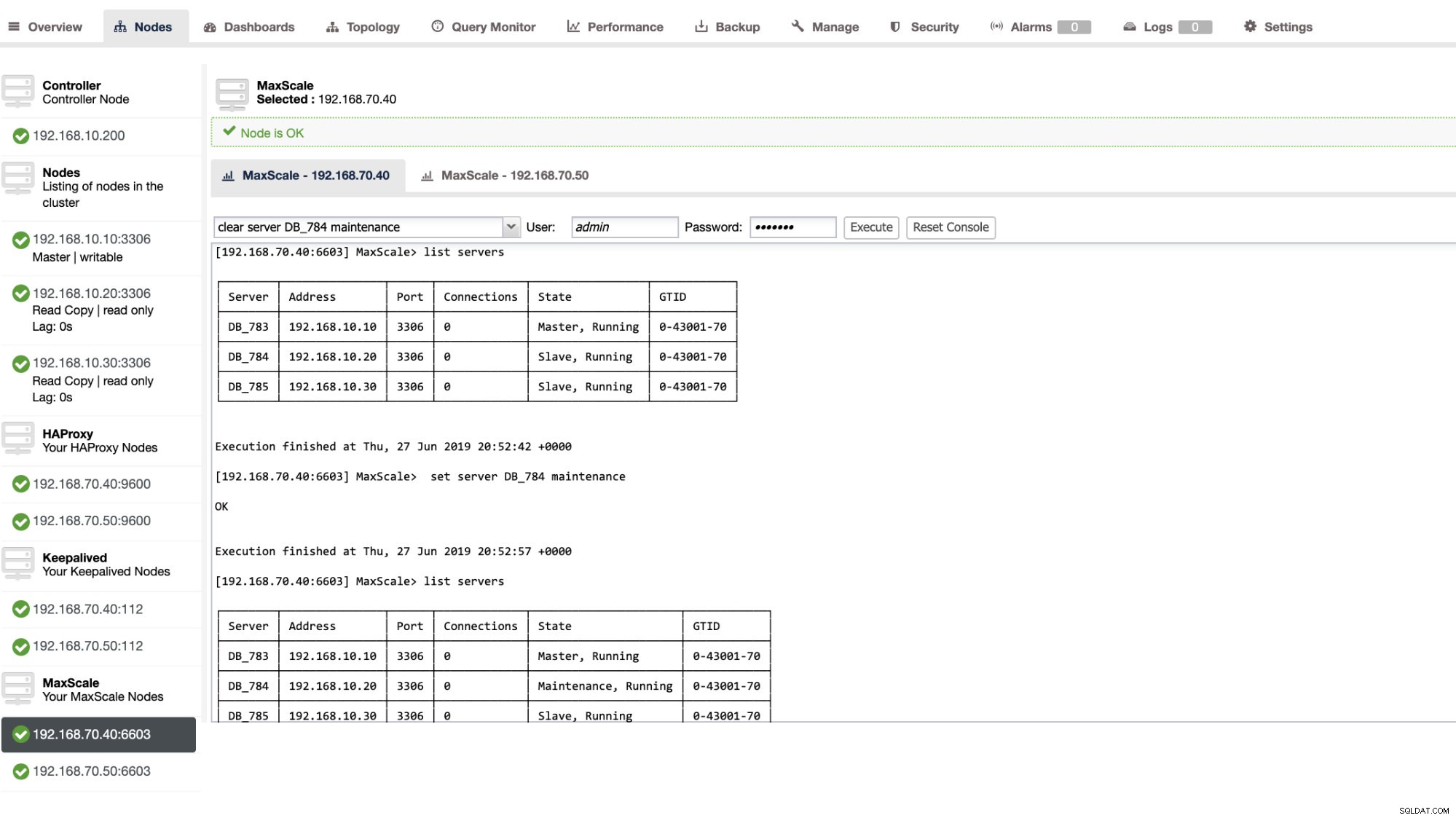
MaxScale Failover в действие
Автоматичният отказ
Преодоляването на срив MaxScale на MariaDB работи много ефективно и преконфигурира подчинения според очакванията. В този тест имаме следния набор от конфигурационни файлове, който е създаден и управляван от ClusterControl. Вижте по-долу:
[replication_monitor]
type=monitor
servers=DB_783,DB_784,DB_785
disk_space_check_interval=1000
disk_space_threshold=/:85
detect_replication_lag=true
enforce_read_only_slaves=true
failcount=3
auto_failover=1
auto_rejoin=true
monitor_interval=300
password=725DE70F196694B277117DC825994D44
user=maxscalecc
replication_password=5349E1268CC4AF42B919A42C8E52D185
replication_user=rpl_user
module=mariadbmonОбърнете внимание, че само auto_failover и auto_rejoin са променливите, които добавих, тъй като ClusterControl няма да добави това по подразбиране, след като настроите балансьор на натоварване MaxScale (вижте този блог за това как да настроите MaxScale с помощта на ClusterControl). Не забравяйте, че трябва да рестартирате MariaDB MaxScale, след като приложите промените във вашия конфигурационен файл. Просто бягай,
systemctl restart maxscaleи сте готови.
Преди да продължим с теста за отказ, нека първо проверим здравето на клъстера:
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Изглежда страхотно!
Убих главната само с чистата команда убиец KILL -9 $(pidof mysqld) в моя главен възел и видях, че не е изненада, мониторът бързо забелязва това и задейства превключването при отказ. Вижте регистрационните файлове, както следва:
2019-06-28 06:39:14.306 error : (mon_log_connect_error): Monitor was unable to connect to server DB_783[192.168.10.10:3306] : 'Can't connect to MySQL server on '192.168.10.10' (115)'
2019-06-28 06:39:14.329 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: master_down. [Master, Running] -> [Down]
2019-06-28 06:39:14.329 warning: (handle_auto_failover): Master has failed. If master status does not change in 2 monitor passes, failover begins.
2019-06-28 06:39:15.011 notice : (select_promotion_target): Selecting a server to promote and replace 'DB_783'. Candidates are: 'DB_784', 'DB_785'.
2019-06-28 06:39:15.011 warning: (warn_replication_settings): Slave 'DB_784' has gtid_strict_mode disabled. Enabling this setting is recommended. For more information, see https://mariadb.com/kb/en/library/gtid/#gtid_strict_mode
2019-06-28 06:39:15.012 warning: (warn_replication_settings): Slave 'DB_785' has gtid_strict_mode disabled. Enabling this setting is recommended. For more information, see https://mariadb.com/kb/en/library/gtid/#gtid_strict_mode
2019-06-28 06:39:15.012 notice : (select_promotion_target): Selected 'DB_784'.
2019-06-28 06:39:15.012 notice : (handle_auto_failover): Performing automatic failover to replace failed master 'DB_783'.
2019-06-28 06:39:15.017 notice : (redirect_slaves_ex): Redirecting 'DB_785' to replicate from 'DB_784' instead of 'DB_783'.
2019-06-28 06:39:15.024 notice : (redirect_slaves_ex): All redirects successful.
2019-06-28 06:39:15.527 notice : (wait_cluster_stabilization): All redirected slaves successfully started replication from 'DB_784'.
2019-06-28 06:39:15.527 notice : (handle_auto_failover): Failover 'DB_783' -> 'DB_784' performed.
2019-06-28 06:39:15.634 notice : (mon_log_state_change): Server changed state: DB_784[192.168.10.20:3306]: new_master. [Slave, Running] -> [Master, Running]
2019-06-28 06:39:20.165 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: slave_up. [Down] -> [Slave, Running]Сега нека да разгледаме здравето на неговия клъстер,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Down │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Възелът 192.168.10.10, който преди е бил главен, е свален. Опитах се да рестартирам и да видя дали автоматичното повторно присъединяване ще се задейства и както забелязахте в регистрационния файл във времето 2019-06-28 06:39:20.165, беше толкова бързо да се улови състоянието на възела и след това да се настрои конфигурацията автоматично без никакви проблеми, за да може DBA да го включи.
Сега, проверявайки накрая състоянието му, изглежда перфектно работещ според очакванията. Вижте по-долу:
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Бившият ми господар е оправен и възстановен и искам да превключвам
Преминаването към предишния ви господар също не е проблем. Можете да управлявате това с maxctrl (или maxadmin в предишни версии на MaxScale) или чрез потребителски интерфейс на ClusterControl (както беше показано по-горе).
Нека просто се обърнем към предишното състояние на здравето на клъстера за репликация по-рано и искахме да превключим 192.168.10.10 (в момента подчинен) обратно към неговото главно състояние. Преди да продължим, може да се наложи първо да идентифицирате монитора, който ще използвате. Можете да проверите това със следната команда по-долу:
maxctrl: list monitors
┌─────────────────────┬─────────┬────────────────────────┐
│ Monitor │ State │ Servers │
├─────────────────────┼─────────┼────────────────────────┤
│ replication_monitor │ Running │ DB_783, DB_784, DB_785 │
└─────────────────────┴─────────┴────────────────────────┘След като го имате, можете да направите следната команда по-долу, за да превключите:
maxctrl: call command mariadbmon switchover replication_monitor DB_783 DB_784
OKСлед това проверете отново състоянието на клъстера,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Изглежда перфектно!
Дневниците ще ви покажат многословно как е минало и поредицата от действия по време на превключването. Вижте подробностите по-долу:
2019-06-28 07:03:48.064 error : (switchover_prepare): 'DB_784' is not a valid promotion target for switchover because it is already the master.
2019-06-28 07:03:48.064 error : (manual_switchover): Switchover cancelled.
2019-06-28 07:04:30.700 notice : (create_start_slave): Slave connection from DB_784 to [192.168.10.10]:3306 created and started.
2019-06-28 07:04:30.700 notice : (redirect_slaves_ex): Redirecting 'DB_785' to replicate from 'DB_783' instead of 'DB_784'.
2019-06-28 07:04:30.708 notice : (redirect_slaves_ex): All redirects successful.
2019-06-28 07:04:31.209 notice : (wait_cluster_stabilization): All redirected slaves successfully started replication from 'DB_783'.
2019-06-28 07:04:31.209 notice : (manual_switchover): Switchover 'DB_784' -> 'DB_783' performed.
2019-06-28 07:04:31.318 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: new_master. [Slave, Running] -> [Master, Running]
2019-06-28 07:04:31.318 notice : (mon_log_state_change): Server changed state: DB_784[192.168.10.20:3306]: new_slave. [Master, Running] -> [Slave, Running]В случай на грешно превключване, той няма да продължи и следователно ще генерира грешка, както е показано в дневника по-горе. Така че ще бъдете в безопасност и няма никакви страшни изненади.
Направете вашата MaxScale високодостъпна
Въпреки че е малко извън темата по отношение на отказоустойчивостта, исках да добавя някои ценни точки тук по отношение на високата наличност и как тя е свързана с отказването на MariaDB MaxScale.
Осигуряването на висока достъпност на вашия MaxScale е важна част в случай, че системата ви се срине, изпитате повреда на диска или повреда на виртуалната машина. Тези ситуации са неизбежни и могат да повлияят на състоянието на вашата автоматична настройка за превключване при отказ, когато възникнат тези неочаквани цикли на поддръжка.
За среда от тип клъстер за репликация, това е много полезно и силно се препоръчва за конкретна настройка на MaxScale. Целта на това е само един екземпляр на MaxScale да може да модифицира клъстера във всеки даден момент. Ако сте настроили с Keepalived, това е мястото, където се намират екземплярите със статус MASTER. Самата MaxScale не знае състоянието си, но сmaxctrl (или maxadmin в предишни версии) може да зададе екземпляр на MaxScale в пасивен режим. От версия 2.2.2 пасивната MaxScale се държи подобно на активната с разликата, че няма да извърши отказ, превключване или повторно присъединяване. Дори ръчните версии на тези команди ще завършат с грешка. Разликите в пасивния/активния режим могат да бъдат разширени в бъдеще, така че следете за такива промени в MaxScale. За да направите това, просто направете следното:
maxctrl: alter maxscale passive true
OKМожете да проверите това след това, като изпълните командата по-долу:
[example@sqldat.com vagrant]# maxctrl -u admin -p mariadb -h 127.0.0.1:8989 show maxscale|grep 'passive'
│ │ "passive": true, │Ако искате да проверите как да настроите високодостъпно с Keepalived, моля, проверете тази публикация от MariaDB.
VIP работа
Освен това, тъй като MaxScale няма вградена VIP обработка, можете да използвате Keepalived, за да се справите с това вместо вас. Можете просто да използвате virtual_ipaddress, присвоен на възела на състоянието MASTER. Това вероятно ще доведе до управление на виртуален IP точно както MHA прави с променлива master_failover_script. Както споменахме по-рано, разгледайте тази публикация в блога за настройка на Keepalived с MaxScale от MariaDB.
Заключение
MariaDB MaxScale е богат на функции и има много възможности, не само като прокси и балансьор на натоварване, но също така предлага механизма за преодоляване на срива, който търсят големите организации. Това е почти универсален софтуер, но разбира се идва с ограничения, които може да се наложи на определено приложение, за разлика от други средства за балансиране на натоварването, като ProxySQL.
ClusterControl също така предлага автоматично отказване и главен механизъм за автоматично откриване, плюс възстановяване на клъстер и възел с възможност за внедряване на Maxscale и други технологии за балансиране на натоварването.
Всеки от тези инструменти има своите разнообразни функции и функционалност, но MariaDB MaxScale се поддържа добре в ClusterControl и може да бъде разгърнат по възможност заедно с Keepalived, HAProxy, за да ви помогне да ускорите ежедневната си рутинна задача.