Presto е с отворен код, паралелно разпределен SQL двигател за обработка на големи данни. Той е разработен от самото начало от Facebook. Първата вътрешна версия се състоя през 2013 г. и беше доста революционно решение за техните проблеми с големи данни.
Със стотиците геолокирани сървъри и петабайтове данни, Facebook започна да търси алтернативна платформа за своите Hadoop клъстери. Техният инфраструктурен екип искаше да намали времето, необходимо за изпълнение на пакетни задачи за анализ и да опрости разработването на конвейер, като използва език за програмиране, широко познат в организацията – SQL.
Според фондация Presto, „Facebook използва Presto за интерактивни заявки към няколко вътрешни хранилища за данни, включително тяхното 300PB хранилище за данни. Над 1000 служители на Facebook използват Presto ежедневно, за да изпълняват повече от 30 000 заявки, които общо сканират над петабайт всяка на ден.”
Въпреки че Facebook има изключителна среда за съхранение на данни, същите предизвикателства присъстват в много организации, занимаващи се с големи данни.
В този блог ще разгледаме как да настроим основна среда presto с помощта на Docker сървър от tar файла. Като източник на данни ще се съсредоточим върху източника на данни MySQL, но може да бъде всяка друга популярна RDBMS.
Изпълнение на Presto в среда с големи данни
Преди да започнем, нека да разгледаме набързо основните му принципи на архитектурата. Presto е алтернатива на инструменти, които отправят заявки към HDFS, използвайки тръбопроводи от задания MapReduce - като Hive. За разлика от Hive Presto не използва MapReduce. Presto работи със специална машина за изпълнение на заявки с оператори от високо ниво и обработка в паметта.
За разлика от Hive Presto може да предава поточно данни през всички етапи наведнъж, като едновременно изпълнява парчета данни. Той е проектиран да изпълнява ad-hoc аналитични заявки срещу единични или разпределени хетерогенни източници на данни. Той може да достигне от платформа Hadoop, за да потърси релационни бази данни или други хранилища на данни, като плоски файлове.
Presto използва стандартен ANSI SQL, включително агрегации, обединявания или аналитични прозоречни функции. SQL е добре познат и много по-лесен за използване в сравнение с MapReduce, написан на Java.
Разгръщане на Presto в Docker
Основната конфигурация на Presto може да бъде разгърната с предварително конфигуриран образ на Docker или tarball на presto сървъра.
Docker сървърът и Presto CLI контейнерите могат лесно да бъдат разгърнати с:
docker run -d -p 127.0.0.1:8080:8080 --name presto starburstdata/presto
docker exec -it presto presto-cliМожете да избирате между две версии на сървъра Presto. Общностна версия и корпоративна версия от Starburst. Тъй като ще го стартираме в непроизводствена пясъчна среда, ще използваме версията на Apache в тази статия.
Предварителни изисквания
Presto е реализиран изцяло в Java и изисква JVM да бъде инсталиран на вашата система. Работи както на OpenJDK, така и на Oracle Java. Минималната версия е Java 8u151 или Java 11.
За да изтеглите JAVA JDK, посетете https://openjdk.java.net/ или https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
Можете да проверите вашата версия на Java с
$ java -version
openjdk version "1.8.0_222"
OpenJDK Runtime Environment (AdoptOpenJDK)(build 1.8.0_222-b10)
OpenJDK 64-Bit Server VM (AdoptOpenJDK)(build 25.222-b10, mixed mode)Инсталиране на Presto
За да инсталираме Presto, ще изтеглим сървърен tar и изпълним файл Presto CLI jar.
Архивът ще съдържа единствена директория от най-високо ниво, presto-server-0.223, която ще наречем инсталационна директория.
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.223/presto-server-0.223.tar.gz
$ tar -xzvf presto-server-0.223.tar.gz
$ cd presto-server-0.223/
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.223/presto-cli-0.223-executable.jar
$ mv presto-cli-0.223-executable.jar presto
$ chmod +x prestoОсвен това Presto се нуждае от директория с данни за съхранение на регистрационни файлове и др.
Препоръчително е да създадете директория с данни извън инсталационната директория.
$ mkdir -p ~/data/presto/Това местоположение е мястото, когато започваме нашето отстраняване на неизправности.
Конфигуриране на Presto
Преди да започнем нашия първи екземпляр, трябва да създадем куп конфигурационни файлове. Започнете със създаването на etc/ директория в инсталационната директория. Това местоположение ще съдържа следните конфигурационни файлове:
и т.н./
- Свойства на възел – конфигурация на средата на възел
- JVM Config (jvm.config) – конфигурация на виртуалната машина на Java
- Config Properties(config.properties) -конфигурация за сървъра Presto
- Свойства на каталога – конфигурация за конектори (източници на данни)
- Свойства на регистрационния файл – Конфигурация на регистратори
По-долу можете да намерите някои основни конфигурации за стартиране на Presto sandbox. За повече подробности посетете документацията.
vi etc/config.properties
Config.properties
coordinator = true
node-scheduler.include-coordinator = true
http-server.http.port = 8080
query.max-memory = 5GB
query.max-memory-per-node = 1GB
discovery-server.enabled = true
discovery.uri = https://localhost:8080
vi etc/jvm.config
-server
-Xmx8G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
vi etc/log.properties
com.facebook.presto = INFOvi etc/node.properties
node.environment = production
node.id = ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir = /Users/bartez/data/prestoОсновната структура etc/ може да изглежда по следния начин:

Следващата стъпка е да настроим MySQL конектора.
Ще се свържем с един от 3-те възела MariaDB Cluster.
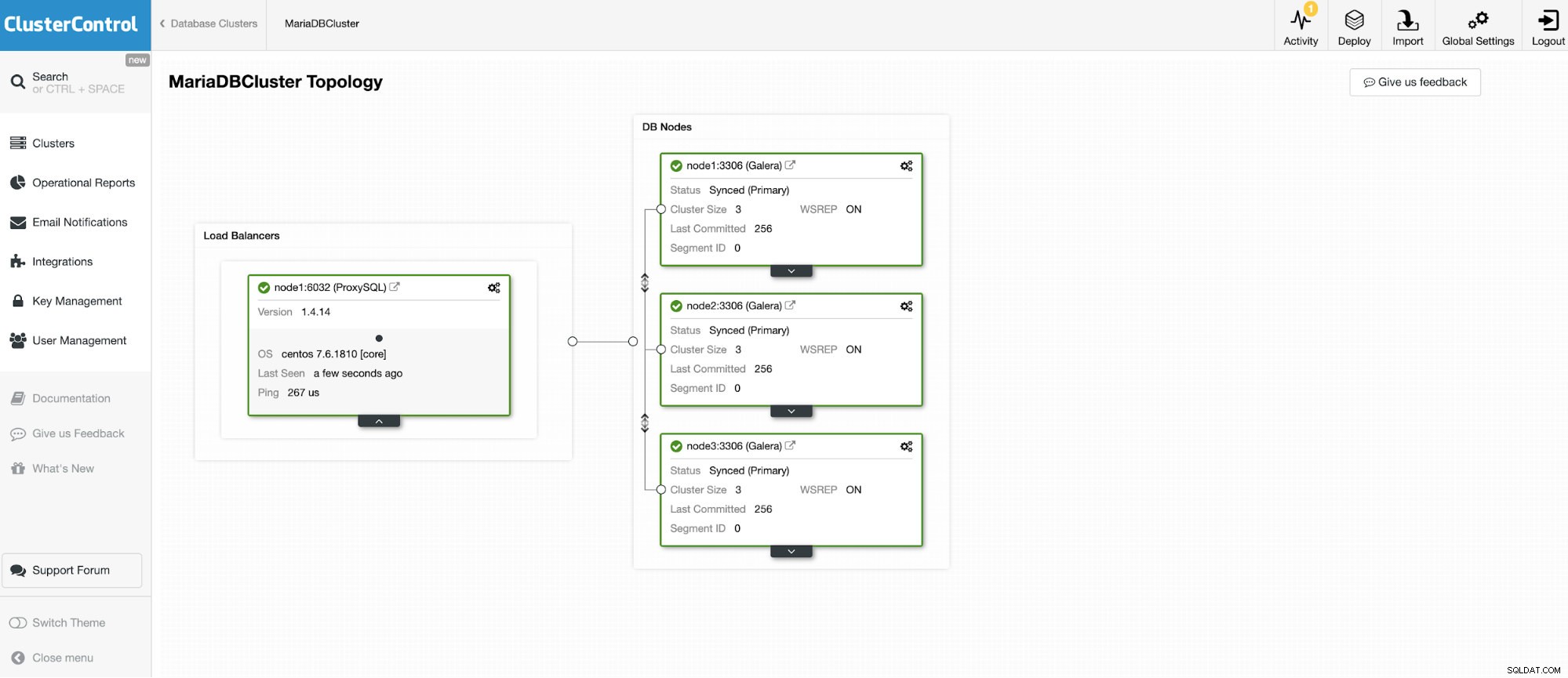
И още един самостоятелен екземпляр, работещ с Oracle MySQL 5.7.
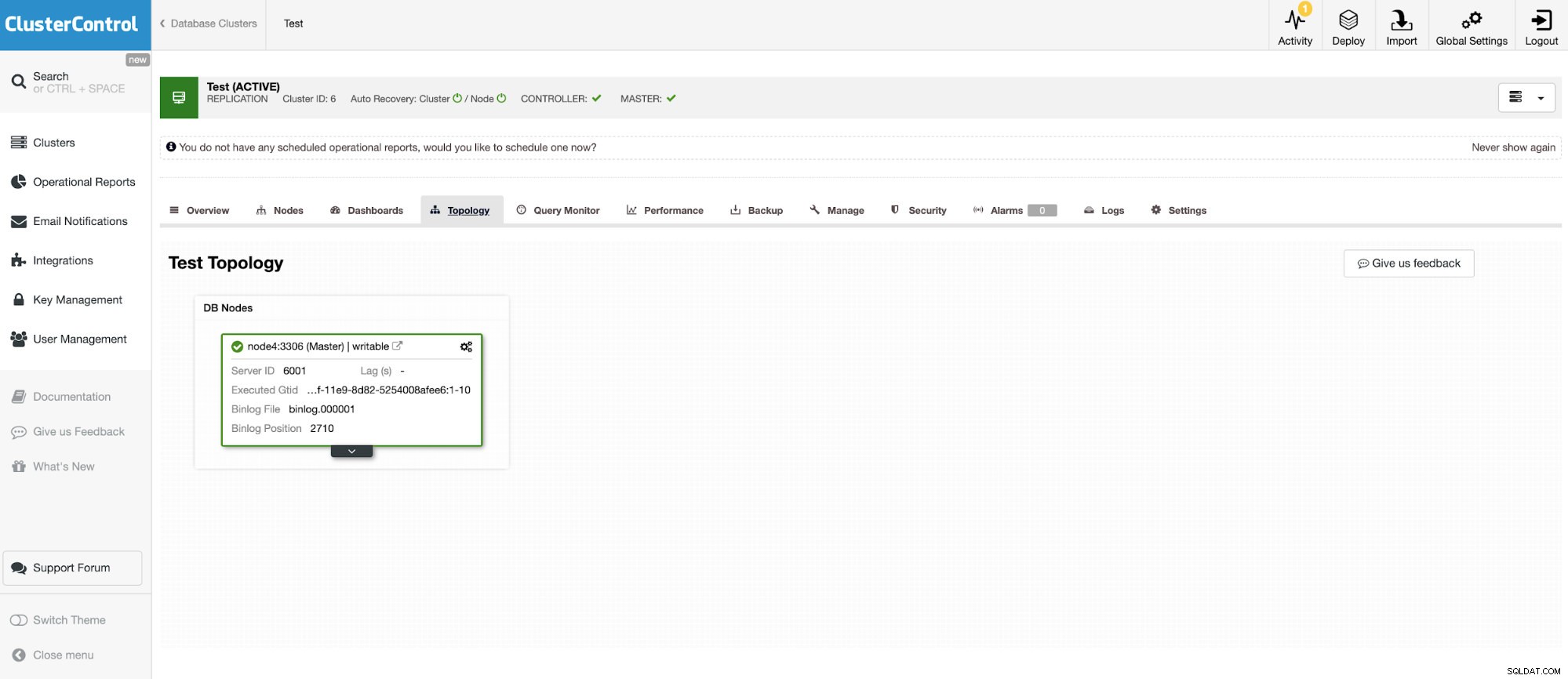
MySQL конекторът позволява заявки и създаване на таблици във външна MySQL база данни. Това може да се използва за обединяване на данни между различни системи като MariaDB и MySQL от Oracle.
Presto използва щепселни конектори и конфигурацията е много лесна. За да конфигурирате MySQL конектора, създайте файл със свойства на каталог в etc/catalog с име, например, mysql.properties, за да монтирате MySQL конектора като mysql каталог. Всеки от файловете представлява връзка с друг сървър. В този случай имаме два файла:
vi etc/catalog/mysq.properties:
connector.name=mysql
connection-url=jdbc:mysql://node1.net:3306
connection-user=bart
connection-password=secretvi etc/catalog/mysq2.properties
connector.name=mysql
connection-url=jdbc:mysql://node4.net:3306
connection-user=bart2
connection-password=secretИзпълнявам Presto
Когато всичко е настроено, е време да стартирате екземпляр на Presto. За да започнете presto, отидете в директорията bin под preso инсталация и изпълнете следното:
$ bin/launcher start
Started as 18363За да спрете Presto run
$ bin/launcher stopСега, когато сървърът е готов и работи, можем да се свържем с Presto с CLI и да отправим заявка към MySQL база данни.
За да стартирате Presto конзолата, изпълнете:
./presto --server localhost:8080 --catalog mysql --schema employeesСега можем да правим заявки за нашите бази данни чрез CLI.
presto:mysql> select * from mysql.employees.departments;
dept_no | dept_name
---------+--------------------
d009 | Customer Service
d005 | Development
d002 | Finance
d003 | Human Resources
d001 | Marketing
d004 | Production
d006 | Quality Management
d008 | Research
d007 | Sales
(9 rows)
Query 20190730_232304_00019_uq3iu, FINISHED, 1 node
Splits: 17 total, 17 done (100,00%)
0:00 [9 rows, 0B] [81 rows/s, 0B/s]
И двете бази данни MariaDB cluster и MySQL са захранвани с база данни на служителите.
wget https://github.com/datacharmer/test_db/archive/master.zip
mysql -uroot -psecret < employees.sqlСъстоянието на заявката се вижда и в уеб конзолата Presto:https://localhost:8080/ui/#
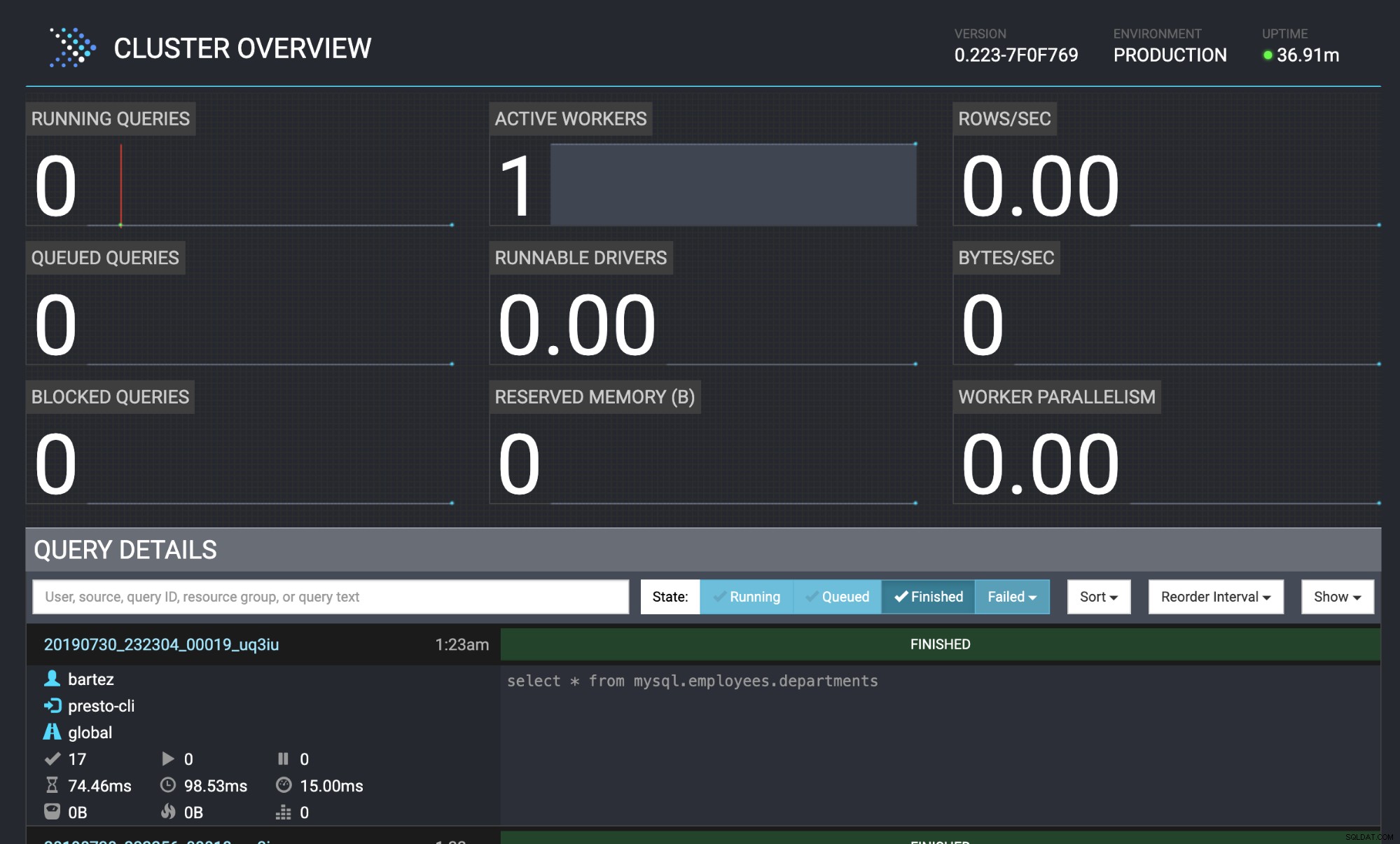 Преглед на Presto Cluster
Преглед на Presto Cluster Заключение
Много добре известни компании (като Airbnb, Netflix, Twitter) приемат Presto за производителност с ниска латентност. Без съмнение това е много интересен софтуер, който може да елиминира необходимостта от стартиране на тежки процеси на ETL склад на данни. В този блог току-що разгледахме MySQL конектора, но можете да го използвате за анализиране на данни от HDFS, обекти, RDBMS (SQL Server, Oracle, PostgreSQL), Kafka, Cassandra, MongoDB и много други.