В тази публикация в блога ще анализираме 6 различни сценария на отказ в системите за производствена база данни, вариращи от проблеми с един сървър до планове за превключване при отказ от множество центрове за данни. Ще ви преведем през процедурите за възстановяване и преодоляване на срив за съответния сценарий. Надяваме се, че това ще ви даде добро разбиране на рисковете, пред които може да се сблъскате, и нещата, които трябва да вземете предвид при проектирането на вашата инфраструктура.
Схемата на базата данни е повредена
Нека започнем с инсталация на един възел - настройка на база данни в най-простата форма. Лесен за изпълнение, на най-ниска цена. В този сценарий стартирате множество приложения на един сървър, където всяка от схемите на базата данни принадлежи на различното приложение. Подходът за възстановяване на една схема ще зависи от няколко фактора.
- Имам ли резервно копие?
- Имам ли резервно копие и колко бързо мога да го възстановя?
- Какъв вид устройство за съхранение се използва?
- Имам ли PITR-съвместим (възстановяване в момент) резервно копие?
Повредата на данните може да бъде идентифицирана чрез mysqlcheck.
mysqlcheck -uroot -p <DATABASE>Заменете DATABASE с името на базата данни и заменете TABLE с името на таблицата, която искате да проверите:
mysqlcheck -uroot -p <DATABASE> <TABLE>Mysqlcheck проверява посочената база данни и таблици. Ако дадена таблица премине проверката, mysqlcheck показва OK за таблицата. В примера по-долу можем да видим, че таблицата заплати изисква възстановяване.
employees.departments OK
employees.dept_emp OK
employees.dept_manager OK
employees.employees OK
Employees.salaries
Warning : Tablespace is missing for table 'employees/salaries'
Error : Table 'employees.salaries' doesn't exist in engine
status : Operation failed
employees.titles OKЗа инсталация с един възел без допълнителни DR сървъри, основният подход би бил възстановяването на данни от архивиране. Но това не е единственото нещо, което трябва да вземете предвид. Наличието на множество схеми на база данни под един и същи екземпляр причинява проблем, когато трябва да свалите сървъра си, за да възстановите данни. Друг въпрос е дали можете да си позволите да върнете всичките си бази данни до последното архивиране. В повечето случаи това не би било възможно.
Тук има някои изключения. Възможно е да се възстанови една таблица или база данни от последното архивиране, когато не е необходимо възстановяване в даден момент. Такъв процес е по-сложен. Ако имате mysqldump, можете да извлечете вашата база данни от него. Ако стартирате двоични архиви с xtradbackup или mariabackup и сте активирали таблица за файл, тогава е възможно.
Ето как да проверите дали имате активирана опция за таблица за файл.
mysql> SET GLOBAL innodb_file_per_table=1; С активиран innodb_file_per_table, можете да съхранявате InnoDB таблици в tbl_name .ibd файл. За разлика от механизма за съхранение на MyISAM, със своите отделни tbl_name .MYD и tbl_name .MYI файлове за индекси и данни, InnoDB съхранява данните и индексите заедно в един .ibd файл. За да проверите вашата машина за съхранение, трябва да стартирате:
mysql> select table_name,engine from information_schema.tables where table_name='table_name' and table_schema='database_name';или директно от конзолата:
[example@sqldat.com ~]# mysql -u<username> -p -D<database_name> -e "show table status\G"
Enter password:
*************************** 1. row ***************************
Name: test1
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 12
Avg_row_length: 1365
Data_length: 16384
Max_data_length: 0
Index_length: 0
Data_free: 0
Auto_increment: NULL
Create_time: 2018-05-24 17:54:33
Update_time: NULL
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment: За да възстановите таблици от xtradbackup, трябва да преминете през процес на експортиране. Архивът трябва да бъде подготвен, преди да може да бъде възстановен. Експортирането се извършва в етапа на подготовка. След като бъде създадено пълно архивиране, стартирайте стандартната процедура за подготовка с допълнителния флаг --export :
innobackupex --apply-log --export /u01/backupТова ще създаде допълнителни файлове за експортиране, които ще използвате по-късно във фазата на импортиране. За да импортирате таблица на друг сървър, първо създайте нова таблица със същата структура като тази, която ще бъде импортирана на този сървър:
mysql> CREATE TABLE corrupted_table (...) ENGINE=InnoDB;изхвърлете пространството за таблици:
mysql> ALTER TABLE mydatabase.mytable DISCARD TABLESPACE;След това копирайте файловете mytable.ibd и mytable.exp в дома на базата данни и импортирайте нейното пространство за таблици:
mysql> ALTER TABLE mydatabase.mytable IMPORT TABLESPACE;Въпреки това, за да направите това по по-контролиран начин, препоръката би била да възстановите резервно копие на базата данни в друг екземпляр/сървър и да копирате това, което е необходимо, обратно в основната система. За да направите това, трябва да стартирате инсталацията на екземпляра на mysql. Това може да се направи или на една и съща машина – но изисква повече усилия за конфигуриране по начин, по който и двата екземпляра да могат да работят на една и съща машина – например това ще изисква различни настройки за комуникация.
Можете да комбинирате възстановяване на задачата и инсталиране, като използвате ClusterControl.
ClusterControl ще ви преведе през наличните резервни копия локално или в облака, ще ви позволи да изберете точно време за възстановяване или точната позиция на регистрационния файл и да инсталирате нов екземпляр на базата данни, ако е необходимо.
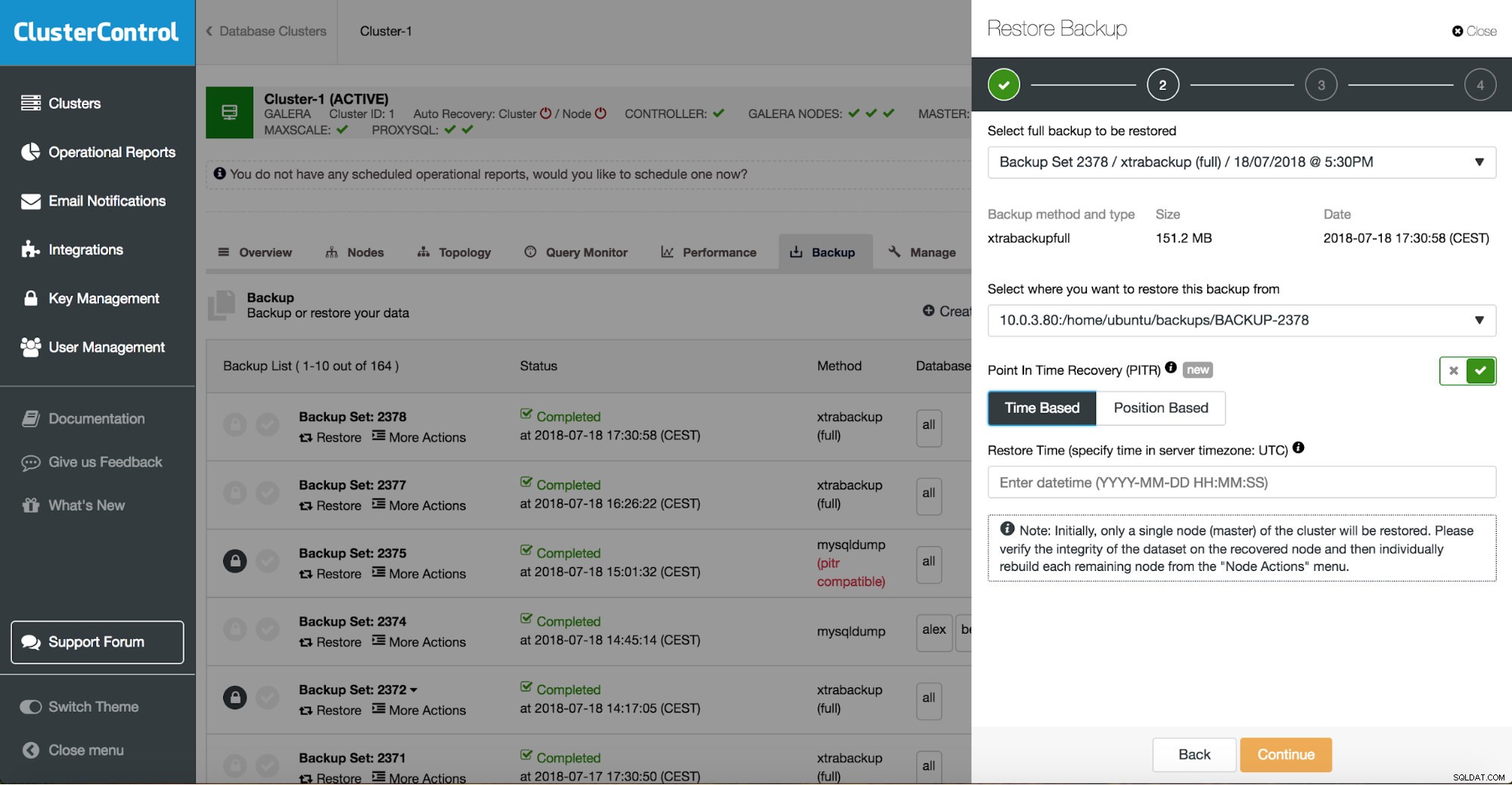 Възстановяване на точка във времето на ClusterControl
Възстановяване на точка във времето на ClusterControl 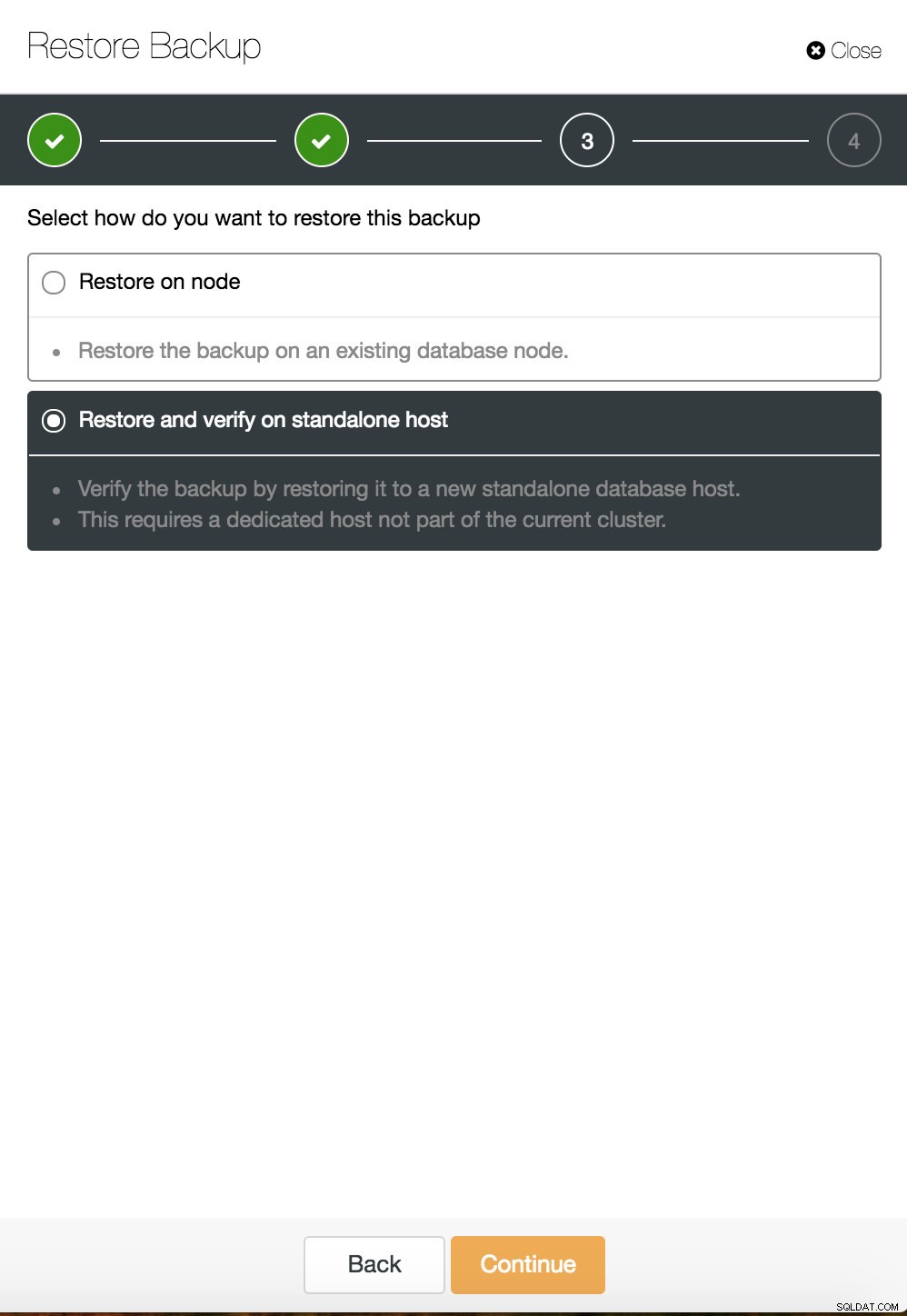 Възстановяване и проверка на ClusterControl на самостоятелен хост
Възстановяване и проверка на ClusterControl на самостоятелен хост 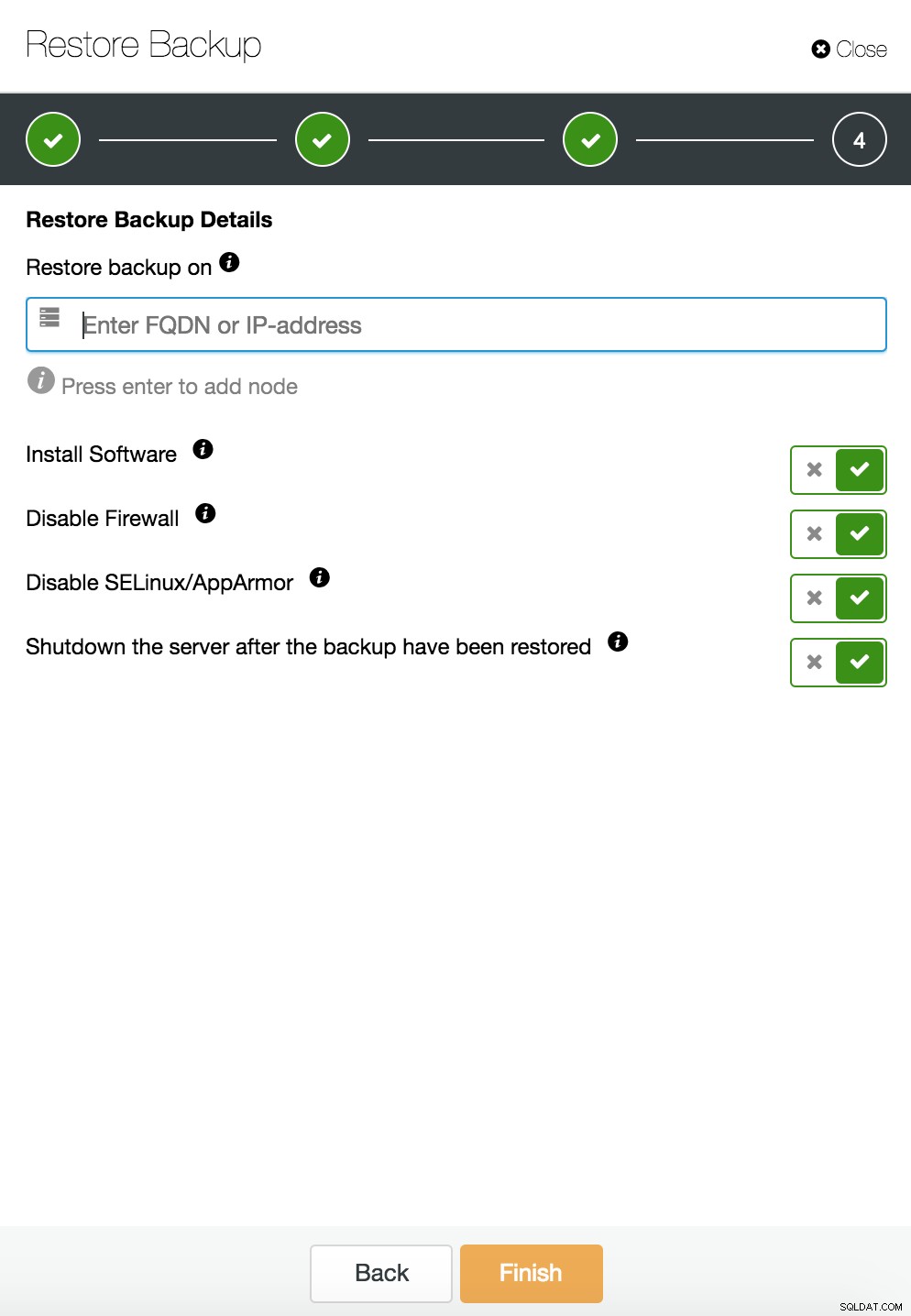 Възстановяване и проверка на CusterControl на самостоятелен хост. Опции за инсталиране.
Възстановяване и проверка на CusterControl на самостоятелен хост. Опции за инсталиране. Можете да намерите повече информация за възстановяването на данни в блог Моята база данни MySQL е повредена... Какво да направя сега?
Екземпляр на базата данни е повреден на специалния сървър
Дефектите в основната платформа често са причина за повреда на базата данни. Вашият MySQL екземпляр разчита на редица неща за съхраняване и извличане на данни - дискова подсистема, контролери, комуникационни канали, драйвери и фърмуер. Сривът може да засегне части от вашите данни, двоични файлове на mysql или дори архивни файлове, които съхранявате в системата. За да разделите различни приложения, можете да ги поставите на специални сървъри.
Различни схеми на приложение на отделни системи е добра идея, ако можете да си ги позволите. Може да се каже, че това е загуба на ресурси, но има шанс въздействието върху бизнеса да бъде по-малко, ако само един от тях падне. Но дори и тогава трябва да защитите вашата база данни от загуба на данни. Съхраняването на резервно копие на същия сървър не е лоша идея, стига да имате копие на друго място. В наши дни облачното съхранение е отлична алтернатива за архивиране на лента.
ClusterControl ви позволява да съхранявате копие на архива си в облака. Поддържа качване до 3-те най-добри облачни доставчици - Amazon AWS, Google Cloud и Microsoft Azure.
Когато възстановите пълния си архив, може да искате да го възстановите до определен момент от време. Възстановяването в даден момент ще обнови сървъра до по-скорошно време, отколкото когато е направен пълното архивиране. За да направите това, трябва да активирате вашите двоични регистрационни файлове. Можете да проверите наличните двоични регистрационни файлове с:
mysql> SHOW BINARY LOGS;И текущият регистрационен файл с:
SHOW MASTER STATUS;След това можете да улавяте инкрементални данни, като предавате двоични регистрационни файлове в sql файл. След това липсващите операции могат да бъдат изпълнени отново.
mysqlbinlog --start-position='14231131' --verbose /var/lib/mysql/binlog.000010 /var/lib/mysql/binlog.000011 /var/lib/mysql/binlog.000012 /var/lib/mysql/binlog.000013 /var/lib/mysql/binlog.000015 > binlog.outСъщото може да се направи в ClusterControl.
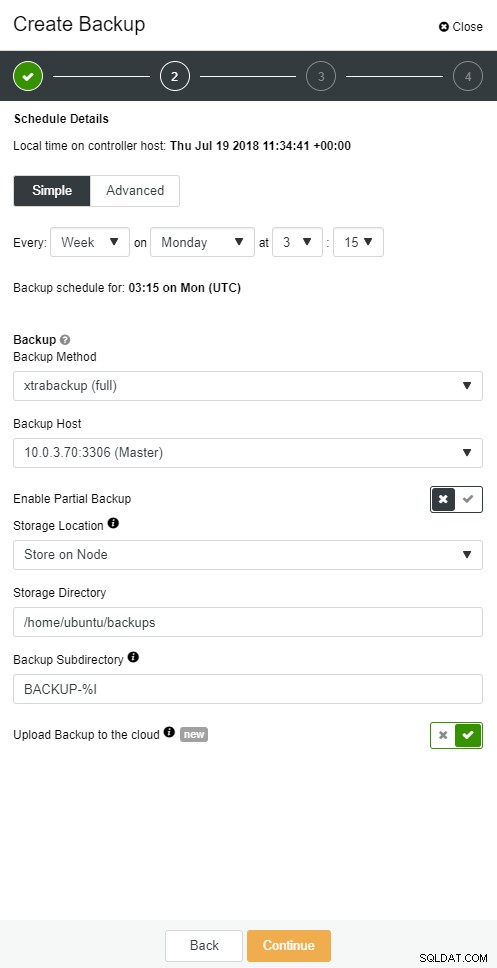 Облачно архивиране на ClusterControl
Облачно архивиране на ClusterControl 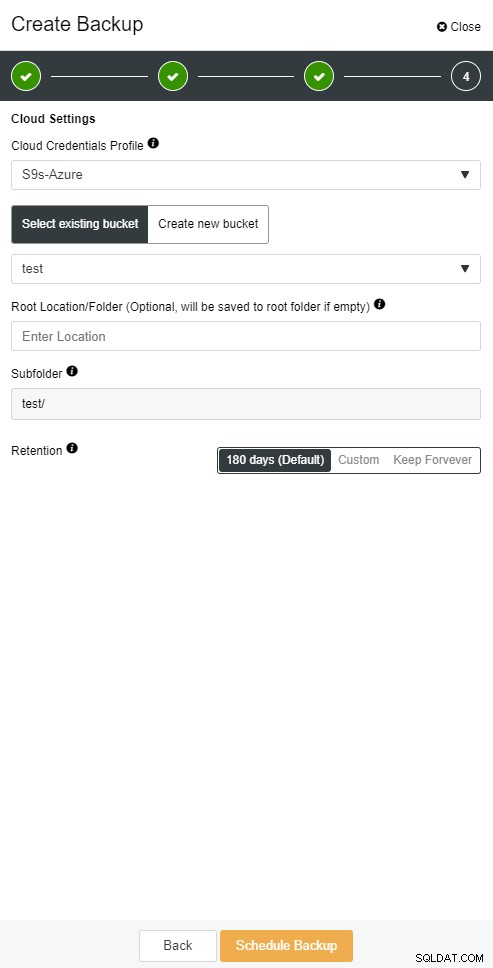 Облачно архивиране на ClusterControl
Облачно архивиране на ClusterControl Подчинената база данни се срива
Добре, така че вашата база данни работи на специален сървър. Създадохте усъвършенстван график за архивиране с комбинация от пълно и постепенно архивиране, качвате ги в облака и съхранявате най-новото архивиране на локални дискове за бързо възстановяване. Имате различни правила за запазване на резервни копия – по-кратки за резервни копия, съхранявани на локални дискови драйвери, и разширени за вашите архивни копия в облак.
Изглежда, че сте добре подготвени за сценарий на бедствие. Но когато става въпрос за времето за възстановяване, то може да не задоволи нуждите на вашия бизнес.
Имате нужда от функция за бързо превключване при отказ. Сървър, който ще работи и ще прилага бинарни регистрационни файлове от главния, където се извършват записите. Главен/подчинен репликация започва нова глава в сценария на отказ. Това е бърз метод за връщане на вашето приложение към живот, ако мастерът ви падне.
Но има няколко неща, които трябва да се вземат предвид в сценария на отказ. Единият е да настроите подчинен сървър за отложена репликация, така че да можете да реагирате на команди с дебел пръст, които са били задействани на главния сървър. Подчинен сървър може да изостава от главния поне за определено време. Закъснението по подразбиране е 0 секунди. Използвайте опцията MASTER_DELAY за CHANGE MASTER TO, за да зададете забавянето на N секунди:
CHANGE MASTER TO MASTER_DELAY = N;Второто е да активирате автоматично преминаване при отказ. На пазара има много автоматизирани решения за отказване. Можете да настроите автоматично преминаване при отказ с инструменти на командния ред като MHA, MRM, mysqlfailover или GUI Orchestrator и ClusterControl. Когато е настроен правилно, може значително да намали прекъсването ви.
ClusterControl поддържа автоматизирано преминаване на отказ за MySQL, PostgreSQL и MongoDB репликации, както и решения за клъстер с множество глави Galera и NDB.
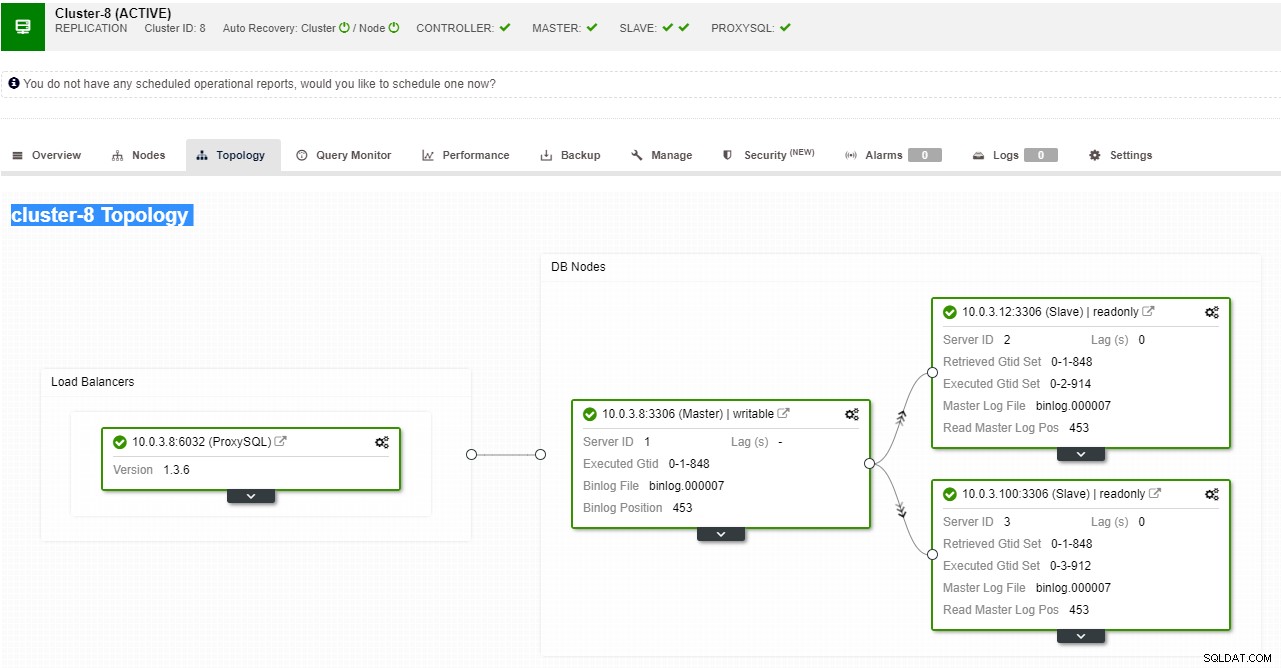 Изглед на топология за репликация на ClusterControl
Изглед на топология за репликация на ClusterControl Когато подчинен възел се срине и сървърът изостава сериозно, може да искате да изградите отново своя подчинен сървър. Процесът на възстановяване на подчинен е подобен на възстановяването от резервно копие.
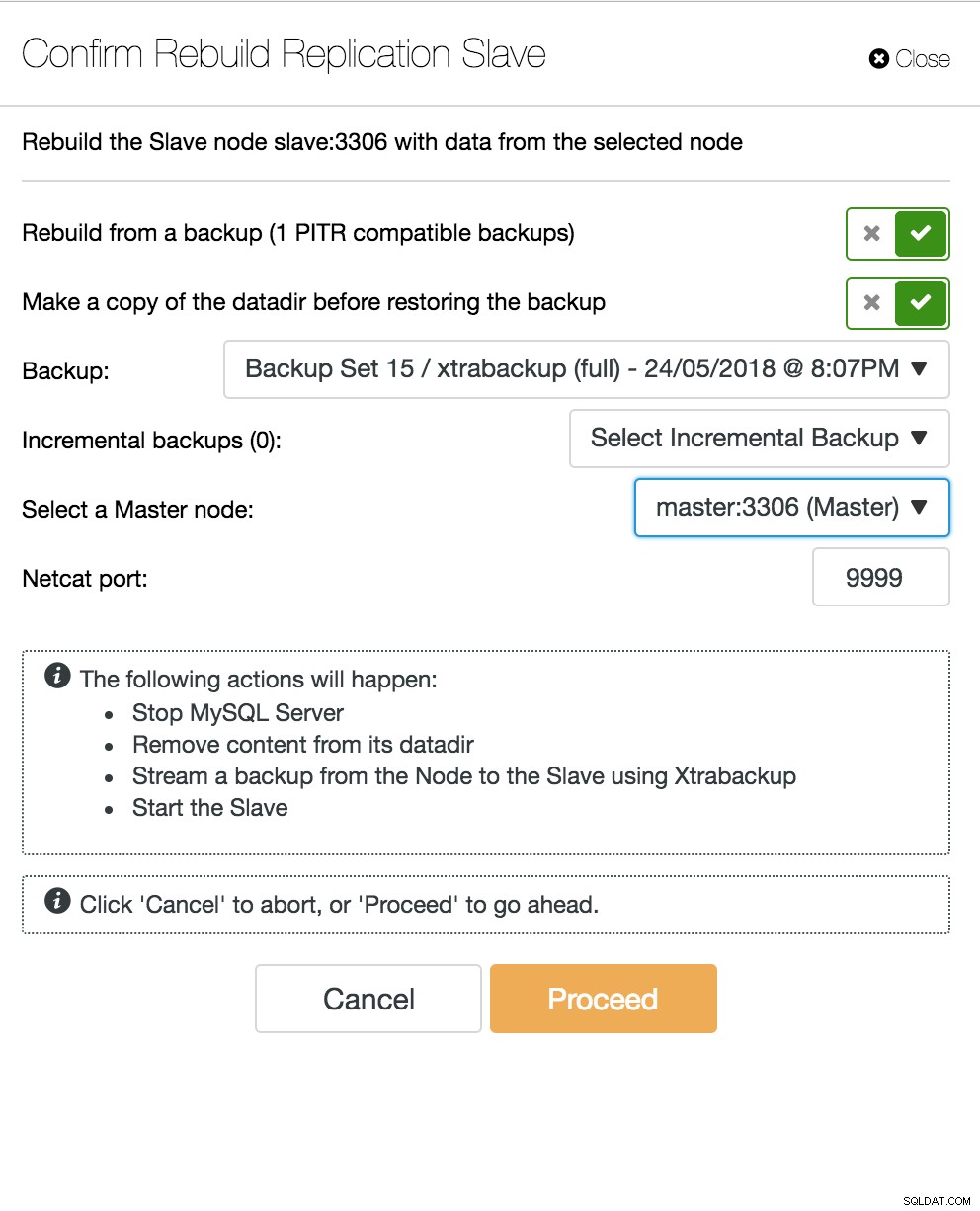 ClusterControl повторно изгражда подчинен
ClusterControl повторно изгражда подчинен Многоглавен сървър на базата данни пада
Сега, когато имате подчинен сървър, действащ като DR възел и вашият процес на отказ е добре автоматизиран и тестван, животът на вашия DBA става по-удобен. Това е вярно, но има още няколко пъзела за решаване. Изчислителната мощност не е безплатна и вашият бизнес екип може да ви помоли да използвате по-добре хардуера си, може да искате да използвате своя подчинен сървър не само като пасивен сървър, но и за обслужване на операции за запис.
След това може да искате да проучите решение за репликация с множество главни. Galera Cluster се превърна в основна опция за MySQL и MariaDB с висока достъпност. И въпреки че сега е известен като надежден заместител на традиционните архитектури главен-подчинен на MySQL, той не е заместител.
Клъстерът Galera има обща архитектура за нищо. Вместо споделени дискове, Galera използва базирана на сертификация репликация с групова комуникация и подреждане на транзакции, за да постигне синхронна репликация. Клъстерът от база данни трябва да може да оцелее при загуба на възел, въпреки че това се постига по различни начини. В случай на Galera, критичният аспект е броят на възлите. Galera изисква кворум, за да работи. Клъстер с три възела може да оцелее при срива на един възел. С повече възли във вашия клъстер можете да преживеете повече неуспехи.
Процесът на възстановяване е автоматизиран, така че не е необходимо да извършвате никакви операции за преодоляване на срив. Добрата практика обаче би била да убиете възли и да видите колко бързо можете да ги върнете обратно. За да направите тази операция по-ефективна, можете да промените размера на кеша на galera. Ако размерът на кеша на galera не е правилно планиран, следващият ви възел за зареждане ще трябва да направи пълно архивиране, вместо да липсва само набори за запис в кеша.
Сценарият на отказ е прост като стартиране на инстанцията. Въз основа на данните в кеша на galera, зареждащият възел ще извърши SST (възстановяване от пълен архив) или IST (прилагане на липсващи набори за запис). Това обаче често е свързано с човешка намеса. Ако искате да автоматизирате целия процес на отказ, можете да използвате функцията за автоматично възстановяване на ClusterControl (ниво на възел и клъстер).
 Автоматично възстановяване на клъстер ClusterControl
Автоматично възстановяване на клъстер ClusterControl Изчислете размера на кеша на galera:
MariaDB [(none)]> SET @start := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); do sleep(60); SET @end := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); SET @gcache := (SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(@@GLOBAL.wsrep_provider_options,'gcache.size = ',-1), 'M', 1)); SELECT ROUND((@end - @start),2) AS `MB/min`, ROUND((@end - @start),2) * 60 as `MB/hour`, @gcache as `gcache Size(MB)`, ROUND(@gcache/round((@end - @start),2),2) as `Time to full(minutes)`;За да направите преминаването при отказ по-последователно, трябва да активирате gcache.recover=yes в mycnf. Тази опция ще съживи кеша на galera при рестартиране. Това означава, че възелът може да действа като ДОНОР и да обслужва липсващи набори за запис (улесняване на IST, вместо да използва SST).
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 2,
members = 2/3 (joined/total),
act_id = 12810,
last_appl. = 0,
protocols = 0/7/3 (gcs/repl/appl),
group UUID = 49eca8f8-0e3a-11e8-be4a-e7e3fe48cb69
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Flow-control interval: [28, 28]
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Trying to continue unpaused monitor
2018-07-20 8:59:44 139657311033088 [Note] WSREP: New cluster view: global state: 49eca8f8-0e3a-11e8-be4a-e7e3fe48cb69:12810, view# 3: Primary, number of nodes: 3, my index: 1, protocol version 3Прокси SQL възел пада
Ако имате настройка на виртуален IP, всичко, което трябва да направите, е да насочите приложението си към виртуалния IP адрес и всичко трябва да е правилно по отношение на връзката. Не е достатъчно да имате екземпляри на база данни, обхващащи множество центрове за данни, все още се нуждаете от приложенията си за достъп до тях. Да приемем, че сте увеличили броя на репликите за четене, може да искате да внедрите виртуални IP адреси за всяка от тези реплики за четене поради причини за поддръжка или наличност. Може да се превърне в тромав набор от виртуални IP адреси, които трябва да управлявате. Ако една от тези реплики за четене е изправена пред срив, трябва да пренастроите виртуалния IP на различния хост, или в противен случай приложението ви ще се свърже или с хост, който не работи, или в най-лошия случай, изоставащ сървър с остарели данни.
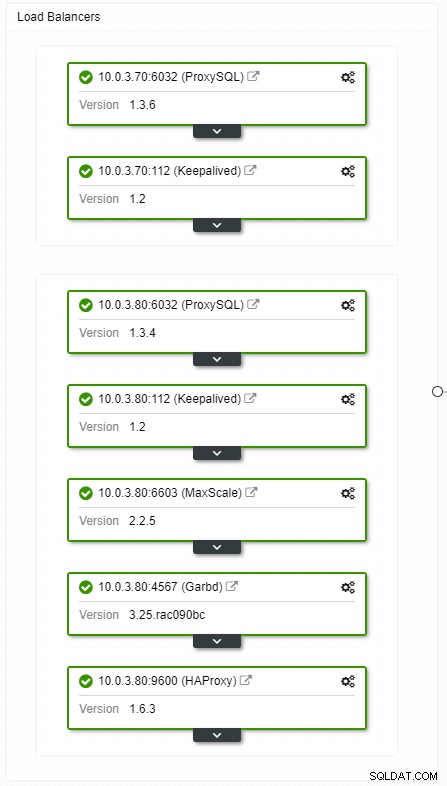 ClusterControl HA балансиране на натоварването изглед на топология
ClusterControl HA балансиране на натоварването изглед на топология Сривовете не са чести, но са по-вероятни, отколкото сървърите да се повредят. Ако поради каквато и да е причина подчинено устройство се повреди, нещо като ProxySQL ще пренасочи целия трафик към главния, с риск от претоварване. Когато робът се възстанови, трафикът ще бъде пренасочен обратно към него. Обикновено такъв престой не трябва да отнема повече от няколко минути, така че общата тежест е средна, въпреки че вероятността също е средна.
За да имате излишни компоненти за балансиране на натоварването, можете да използвате keepalived.
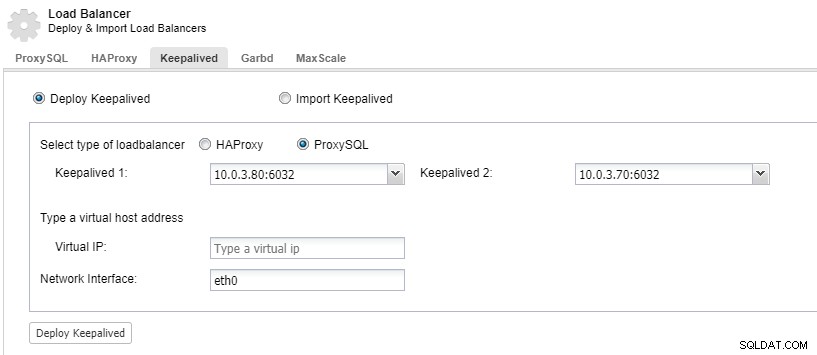 ClusterControl:Внедряване на keepalived за балансиране на натоварването на ProxySQL
ClusterControl:Внедряване на keepalived за балансиране на натоварването на ProxySQL Центърът за данни се срива
Основният проблем с репликацията е, че няма мажоритарен механизъм за откриване на повреда в центъра за данни и обслужване на нов главен. Едно от решенията е да използвате Orchestrator/Raft. Orchestrator е надзорник на топологията, който може да контролира отказите. Когато се използва заедно с Raft, Orchestrator ще осъзнае кворума. Една от инстанциите на Orchestrator се избира за лидер и изпълнява задачи за възстановяване. Връзката между възела на оркестратора не корелира с ангажиментите на транзакционна база данни и е рядка.
Orchestrator/Raft може да използва допълнителни екземпляри, които извършват мониторинг на топологията. В случай на мрежово разделяне, разделените екземпляри на Orchestrator няма да предприемат никакви действия. Частта от клъстера Orchestrator, която има кворум, ще избере нов главен и ще направи необходимите промени в топологията.
ClusterControl се използва за управление, мащабиране и, което е най-важното, възстановяване на възли - Orchestrator ще се справи с отказите, но ако подчинен се срине, ClusterControl ще се погрижи той да бъде възстановен. Orchestrator и ClusterControl ще бъдат разположени в една и съща зона за наличност, отделени от възлите на MySQL, за да се гарантира, че тяхната активност няма да бъде засегната от разделяне на мрежата между зоните за достъпност в центъра за данни.