Клъстерът Galera налага силна последователност на данните, където всички възли в клъстера са тясно свързани. Въпреки че се поддържа сегментиране на мрежата, производителността на репликацията все още е обвързана от два фактора:
-
Времето за двупосочно пътуване (RTT) до най-отдалечения възел в клъстера от възела инициатор.
-
Размерът на набор за запис, който трябва да бъде прехвърлен и сертифициран за конфликт на възела на приемника.
Въпреки че има начини за повишаване на производителността на Galera, не е възможно да се заобиколят тези два ограничаващи фактора.
За щастие, Galera Cluster е изграден върху MySQL, който също идва с вградена функция за репликация (дя!). Както репликацията на Galera, така и репликацията на MySQL съществуват в един и същ сървърен софтуер независимо. Можем да използваме тези технологии, за да работим заедно, където цялата репликация в центъра за данни ще бъде на Galera, докато репликацията между центрове за данни ще бъде на стандартна MySQL репликация. Подчинения сайт може да действа като сайт за гореща готовност, готов да обслужва данни, след като приложенията бъдат пренасочени към сайта за архивиране. Разгледахме това в предишен блог за MySQL архитектури за възстановяване след бедствие.
Репликацията от клъстер към клъстер беше въведена в ClusterControl във версия 1.7.4. В тази публикация в блога ще покажем колко лесно е да настроите репликация между два клъстера Galera (PXC 8.0). След това ще разгледаме по-предизвикателната част:обработка на неуспехи както на нива на възел, така и на клъстер с помощта на ClusterControl; Операциите за преодоляване на срив и отказ са от решаващо значение за запазването на целостта на данните в цялата система.
Разгръщане на клъстер
В името на нашия пример ще ни трябват поне два клъстера и два сайта – един за основния и друг за вторичния. Работи подобно на традиционната MySQL главна-подчинена репликация, но в по-голям мащаб с три възела на база данни във всеки сайт. С ClusterControl бихте постигнали това чрез разгръщане на първичен клъстер, последвано от разгръщане на вторичния клъстер на сайта за аварийно възстановяване като клъстер реплика, репликиран чрез двупосочна асинхронна репликация.
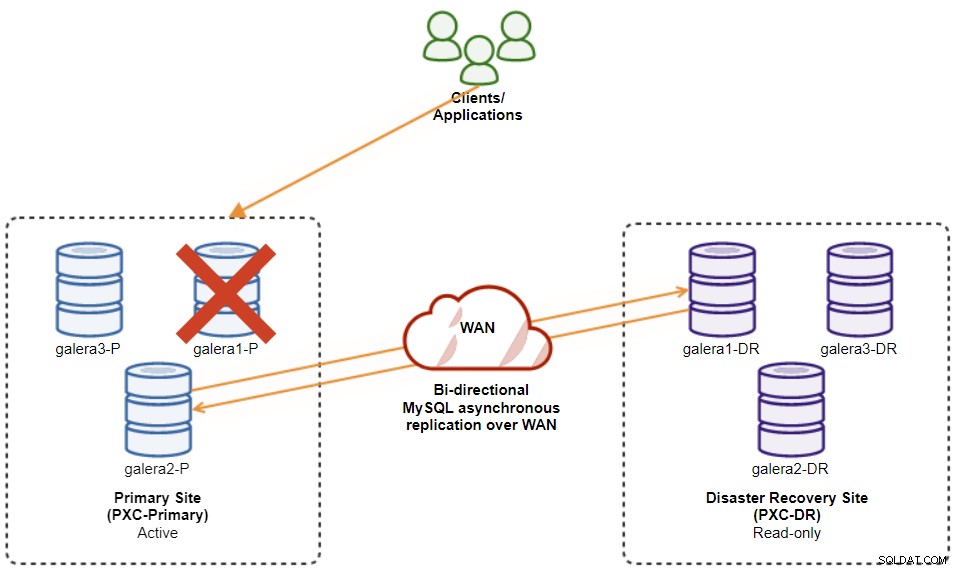
Следната диаграма илюстрира нашата окончателна архитектура:

Имаме общо шест възела на базата данни, три на основния сайт и още един три на сайта за аварийно възстановяване. За да опростим представянето на възела, ще използваме следните обозначения:
-
Основен сайт:
-
galera1-P - 192.168.11.171 (главен)
-
galera2-P - 192.168.11.172
-
galera3-P - 192.168.11.173
-
-
Сайт за възстановяване при бедствия:
-
galera1-DR - 192.168.11.181 (подчинен)
-
galera2-DR - 192.168.11.182
-
galera3-DR - 192.168.11.183
-
Първо, просто разгръщайте първия клъстер и ние го наричаме PXC-Primary. Отворете ClusterControl UI → Deploy → MySQL Galera и въведете всички необходими подробности:
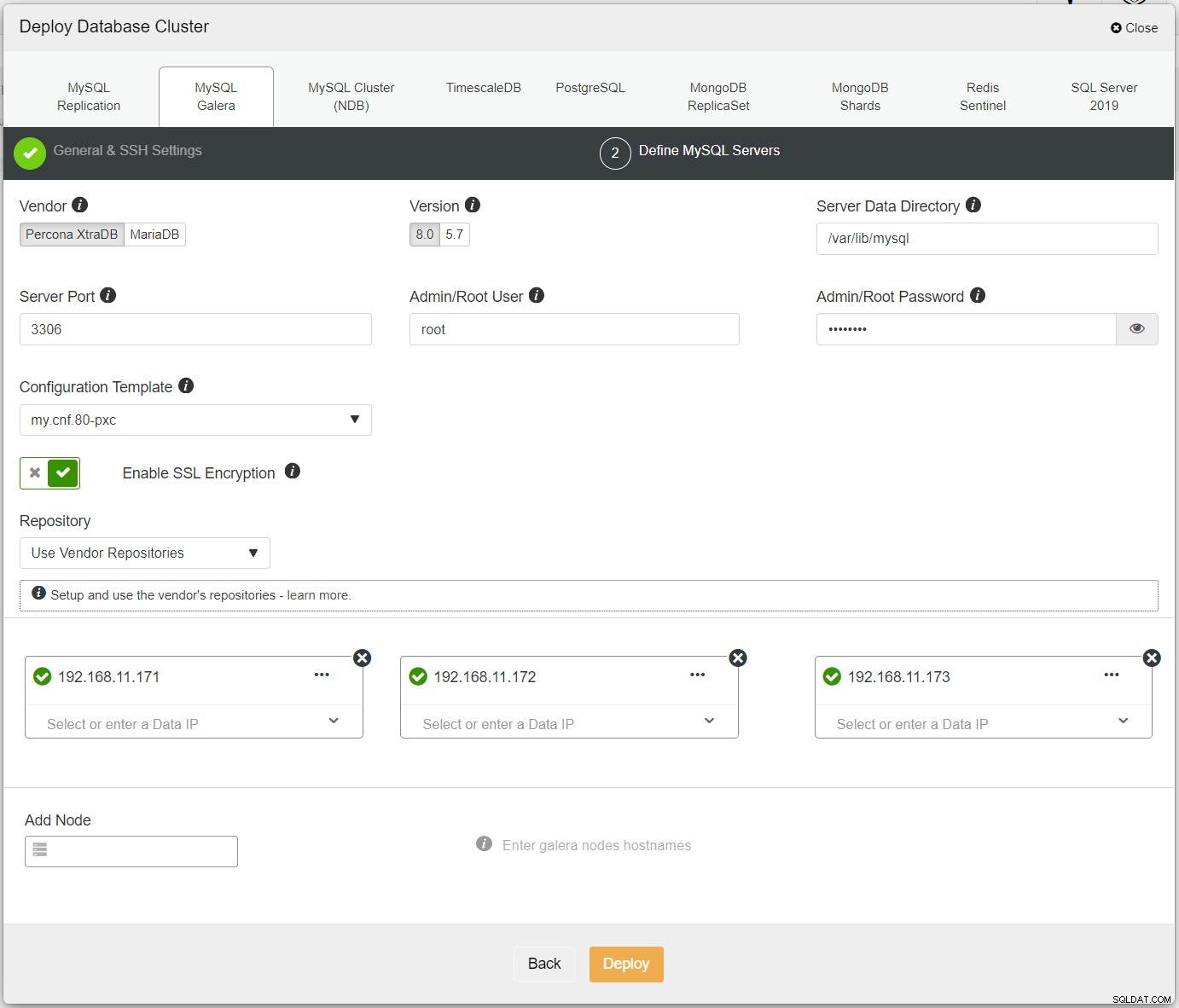
Уверете се, че всеки посочен възел има зелена отметка до себе си, което показва, че ClusterControl може да се свърже с хоста чрез SSH без парола. Щракнете върху Разгръщане и изчакайте внедряването да завърши. След като приключите, трябва да видите следния клъстер, посочен на страницата на таблото за управление на клъстера:
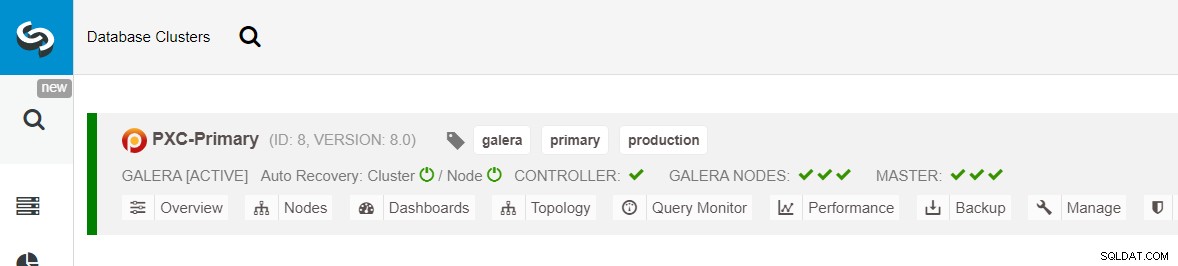
След това ще използваме функцията ClusterControl, наречена Create Replica Cluster, достъпна от падащото меню Cluster Action:
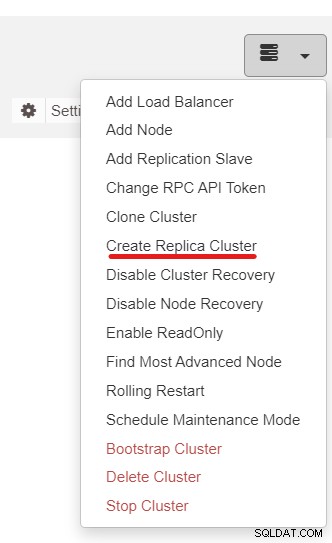
Ще бъдете представени със следния изскачащ прозорец на страничната лента:
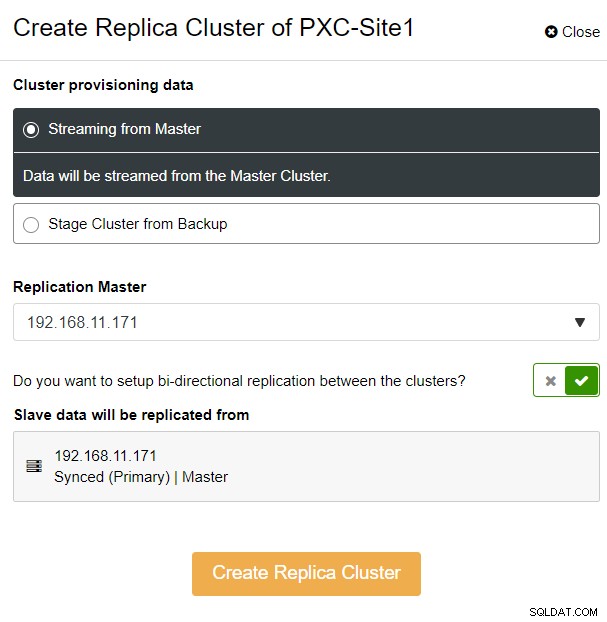
Избрахме опцията "Стрийминг от Master", където ClusterControl ще използва избран главен, за да синхронизирате клъстера на репликата и да конфигурирате репликацията. Обърнете внимание на опцията за двупосочна репликация. Ако е активирано, ClusterControl ще настрои двупосочна репликация между двата сайта (кръгова репликация). Избраният главен обект ще се репликира от първия главен, дефиниран за клъстера на репликата, и обратно. Тази настройка ще сведе до минимум времето за етапи, необходимо при възстановяване след отказ или отказ. Щракнете върху „Създаване на реплики клъстер“, където ClusterControl отваря нов съветник за внедряване на клъстера реплики, както е показано по-долу:
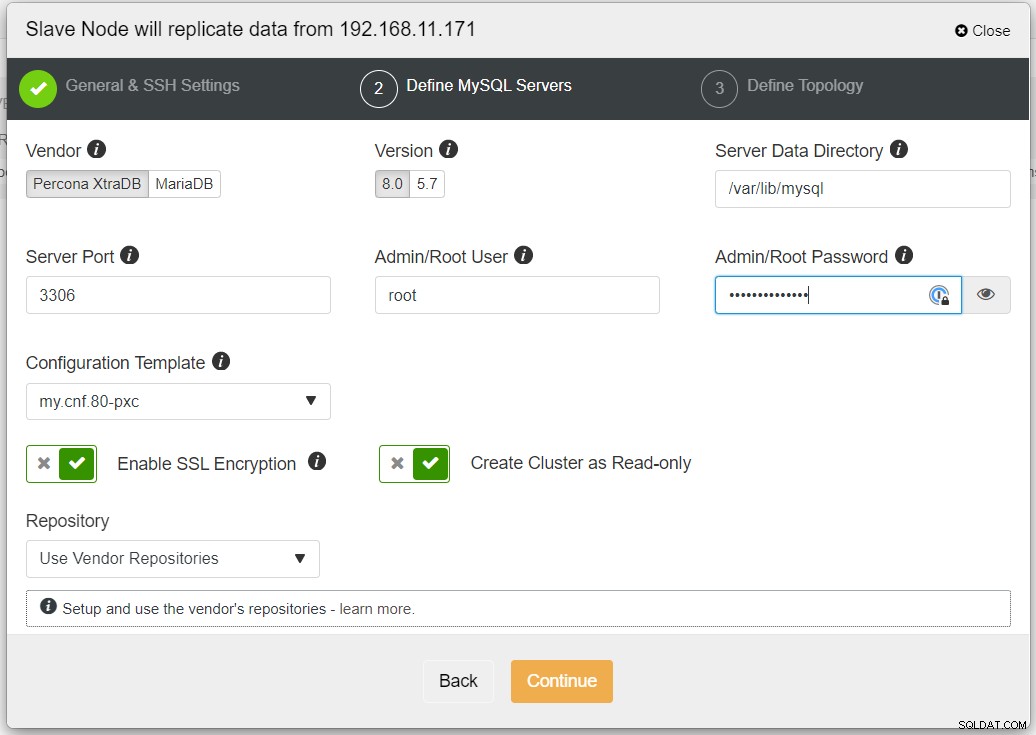
Препоръчително е да активирате SSL криптиране, ако репликацията включва ненадеждни мрежи като WAN, нетунелирани мрежи или Интернет. Също така се уверете, че „Създаване на клъстер като само за четене“ е включено; това е защитата срещу случайни записвания и добър индикатор за лесно разграничаване между активния клъстер (четене-запис) и пасивния клъстер (само за четене).
Когато попълвате цялата необходима информация, трябва да стигнете до следния етап, за да дефинирате топологията на клъстера реплика:
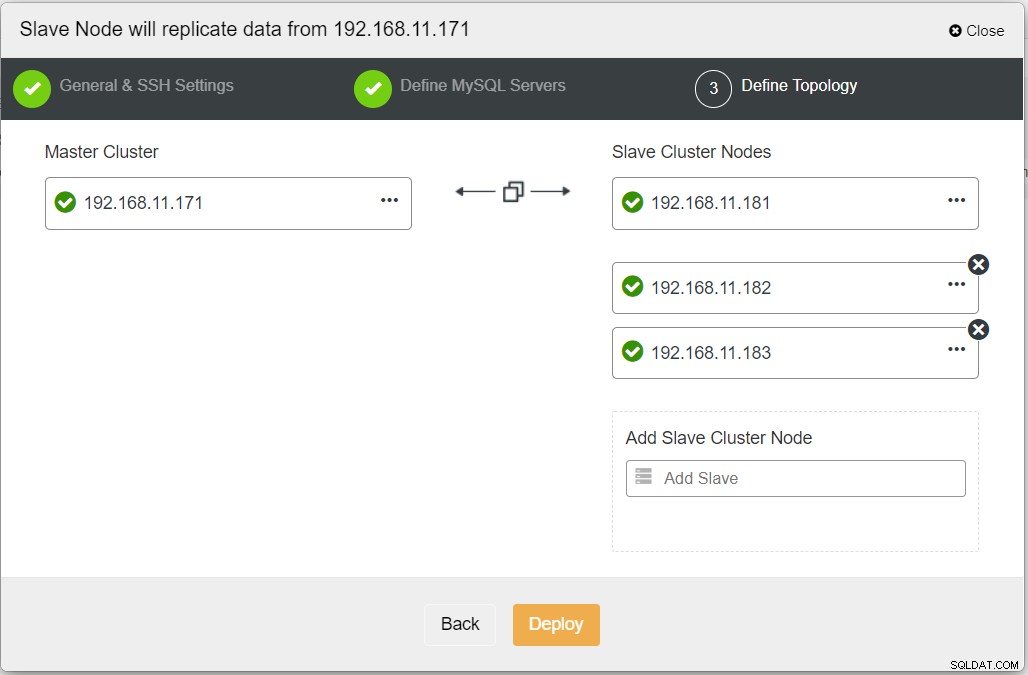
От таблото за управление на ClusterControl, след като внедряването приключи, трябва да видите Сайтът DR има двупосочна стрелка, свързана с основния сайт:
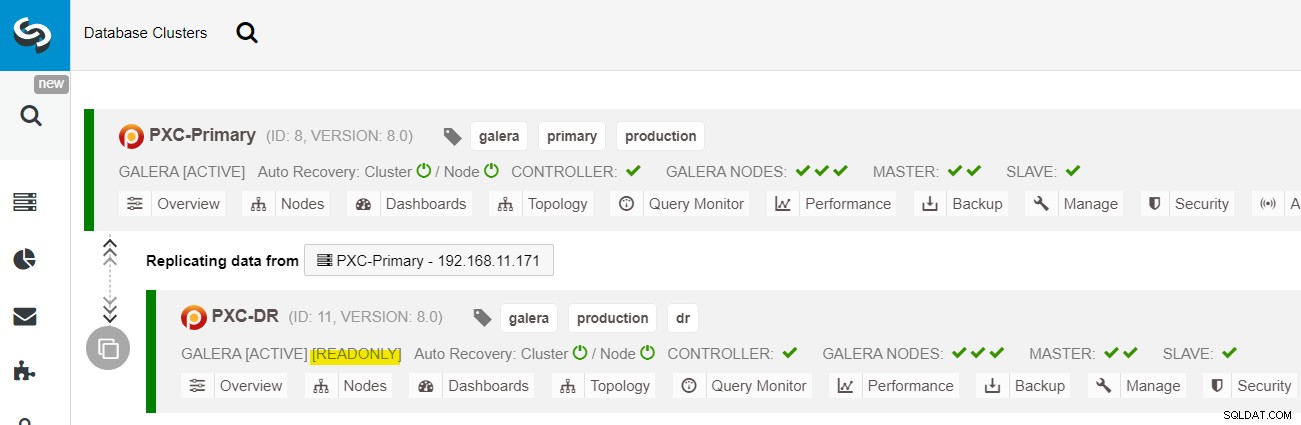
Внедряването вече е завършено. Приложенията трябва да изпращат записи само до основния сайт, тъй като това е активният сайт и DR сайтът е конфигуриран само за четене (маркиран в жълто). Четенията могат да се изпращат и на двата сайта, въпреки че има риск DR сайтът да изостава поради естеството на асинхронната репликация. Тази настройка ще направи основния сайт и сайтовете за възстановяване при бедствия независими един от друг, слабо свързани с асинхронна репликация. Един от възлите на Galera в сайта на DR ще бъде подчинен, който се репликира от един от възлите на Galera (главен) в основния сайт.
Вече имаме система, при която повреда на клъстера на основния сайт няма да засегне резервния сайт. По отношение на производителността забавянето на WAN няма да повлияе на актуализациите на активния клъстер. Те се изпращат асинхронно към сайта за архивиране.
Като странична забележка, възможно е също да имате специален подчинен екземпляр като реле за репликация, вместо да използвате един от възлите на Galera като подчинен.
Процедура за преодоляване на възел на Галера
В случай, че текущият главен (galera1-P) не успее и останалите възли в първичния сайт са все още активни, подчиненото устройство на сайта за аварийно възстановяване (galera1-DR) трябва да бъде насочено към всички налични главни устройства на основния сайт, както е показано на следната диаграма:
От списъка с клъстери ClusterControl можете да видите, че състоянието на клъстера е влошено , и ако превъртите с мишката върху иконата на удивителен знак, можете да видите грешката за този конкретен възел (galera1-P):
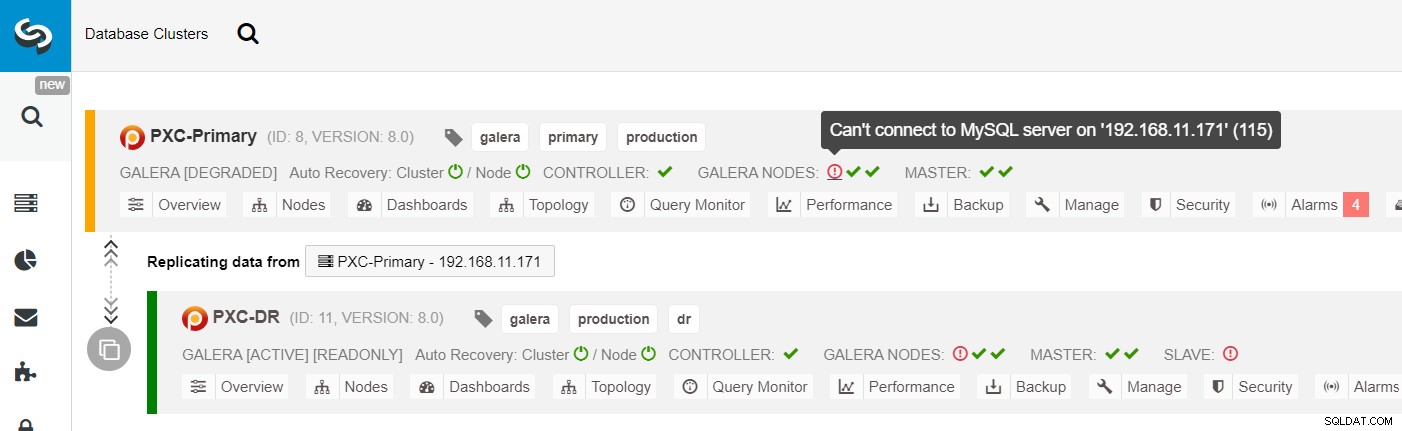
С ClusterControl можете просто да отидете на PXC-DR клъстер → Възли → изберете galera1-DR → Действия на възел → Повторно изграждане на подчинен репликация и ще ви бъде представен следния диалогов прозорец за конфигурация:
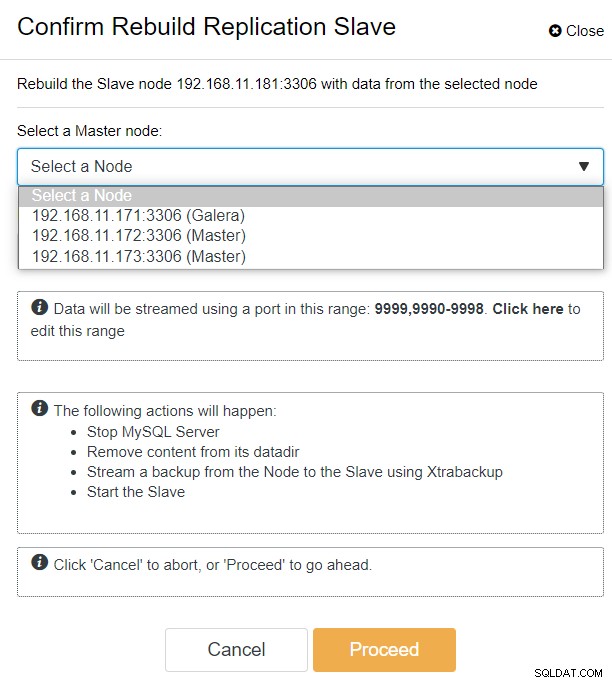
Можем да видим всички възли на Galera в основния сайт (192.168.11.17x ) от падащия списък. Изберете вторичния възел 192.168.11.172 (galera2-P) и щракнете върху Продължи. След това ClusterControl ще конфигурира топологията на репликация както трябва да бъде, като настрои двупосочна репликация от galera2-P към galera1-DR. Можете да потвърдите това от страницата на таблото за управление на клъстера (маркирана в жълто):
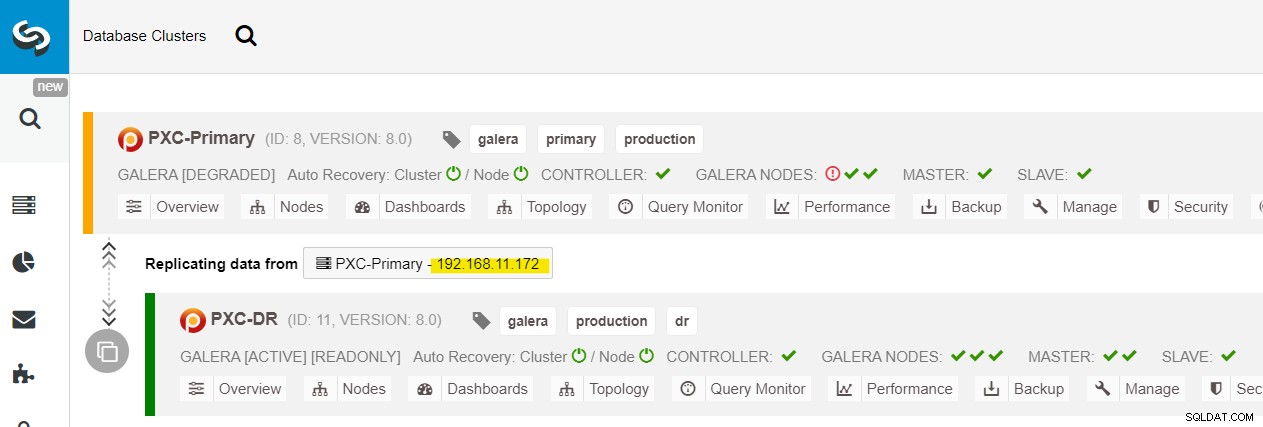
В този момент основният клъстер (PXC-Primary) все още обслужва като активен клъстер за тази топология. Това не трябва да оказва влияние върху времето на работа на услугата за база данни на основния клъстер.
Процедура за отказване на клъстер в Galera
Ако основният клъстер се повреди, се срине или просто загуби връзка от гледна точка на приложението, приложението може да бъде насочено към сайта на DR почти незабавно. SysAdmin просто трябва да деактивира само за четене на всички възли на Galera на сайта за аварийно възстановяване, като използва следното изявление:
mysql> SET GLOBAL read_only = 0; -- repeat on galera1-DR, galera2-DR, galera3-DRЗа потребители на ClusterControl можете да използвате потребителски интерфейс на ClusterControl → Възли → изберете DB възел → Действия на възел → Деактивиране само за четене. ClusterControl CLI също е достъпен чрез изпълнение на следните команди на възела ClusterControl:
$ s9s node --nodes="192.168.11.181" --cluster-id=11 --set-read-write
$ s9s node --nodes="192.168.11.182" --cluster-id=11 --set-read-write
$ s9s node --nodes="192.168.11.183" --cluster-id=11 --set-read-writeПреминаването към DR сайта вече е завършено и приложенията могат да започнат да изпращат записи към PXC-DR клъстера. От потребителския интерфейс на ClusterControl трябва да видите нещо подобно:
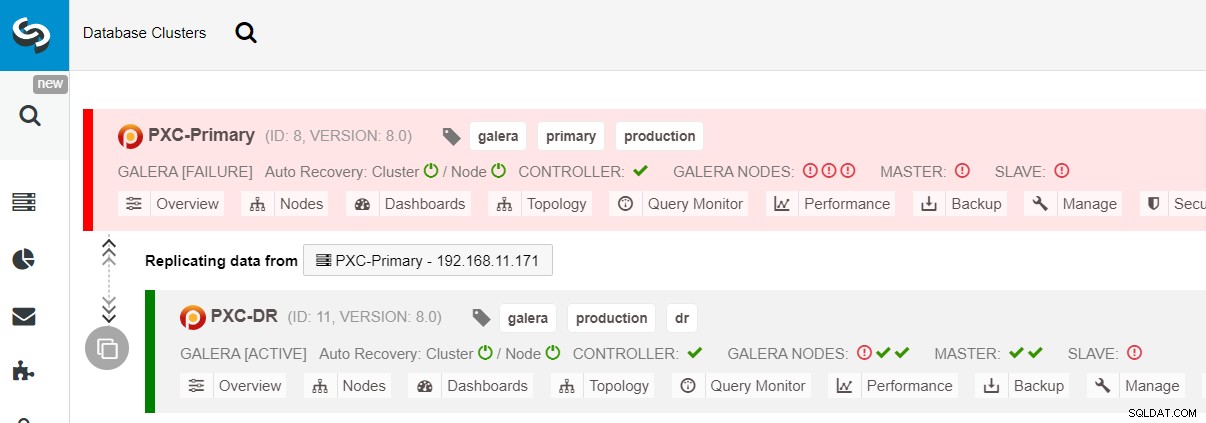
Следната диаграма показва нашата архитектура, след като приложението се провали на сайта на DR :
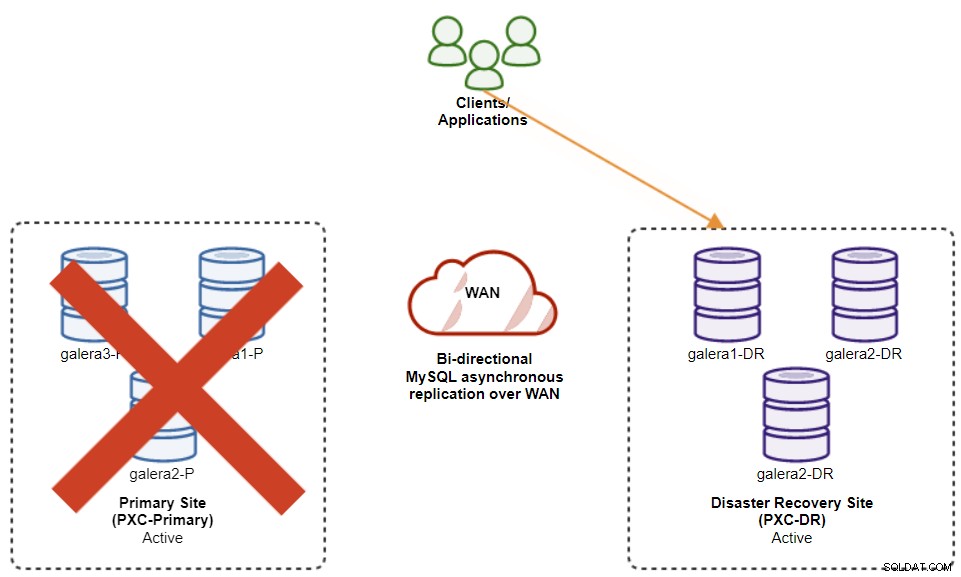
Ако приемем, че основният сайт все още не работи, в този момент няма репликация между сайтове, докато първичният сайт се върне отново.
Процедура за отказ от отказ в клъстер на Galera
След като основният сайт се появи, важно е да се отбележи, че основният клъстер трябва да бъде настроен само за четене, така че да знаем, че активният клъстер е този в сайта за аварийно възстановяване. От ClusterControl отидете в падащото меню на клъстера и изберете „Активиране само за четене“, което ще активира само четене на всички възли в основния клъстер и обобщава текущата топология, както следва:
Уверете се, че всичко е зелено, преди да планирате да стартирате процедурата за възстановяване на клъстер (зелено означава, че всички възли са активирани и синхронизирани един с друг). Ако има възел в влошено състояние, например, реплициращият възел все още изостава или са били достъпни само някои от възлите в първичния клъстер, изчакайте, докато клъстерът бъде напълно възстановен, или като изчакате процедурите за автоматично възстановяване на ClusterControl за завършване или ръчна намеса.
В този момент активният клъстер все още е клъстерът на DR, а основният клъстер действа като вторичен клъстер. Следната диаграма илюстрира текущата архитектура:
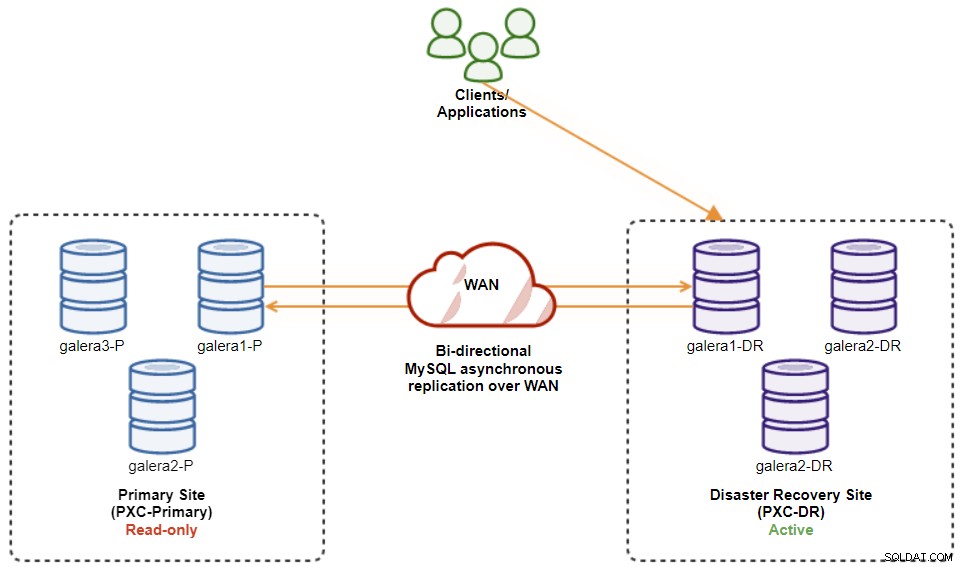
Най-сигурният начин за връщане към основния сайт е да зададете само за четене в клъстера на DR, последвано от деактивиране само за четене на основния сайт. Отидете на ClusterControl UI → PXC-DR (падащо меню) → Активиране само за четене. Това ще задейства задание за задаване само за четене на всички възли в клъстера на DR. След това отидете на ClusterControl UI → PXC-Primary → Nodes и деактивирайте само четене на всички възли на базата данни в основния клъстер.
Можете също да опростите горните процедури с ClusterControl CLI. Като алтернатива, изпълнете следните команди на хоста на ClusterControl:
$ s9s cluster --cluster-id=11 --set-read-only # enable cluster-wide read-only
$ s9s node --nodes="192.168.11.171" --cluster-id=8 --set-read-write
$ s9s node --nodes="192.168.11.172" --cluster-id=8 --set-read-write
$ s9s node --nodes="192.168.11.173" --cluster-id=8 --set-read-writeСлед като е готово, посоката на репликация се връща към първоначалната си конфигурация, където PXC-Primary е активният клъстер, а PXC-DR е клъстерът в режим на готовност. Следната диаграма илюстрира окончателната архитектура след операцията за възстановяване на клъстера:
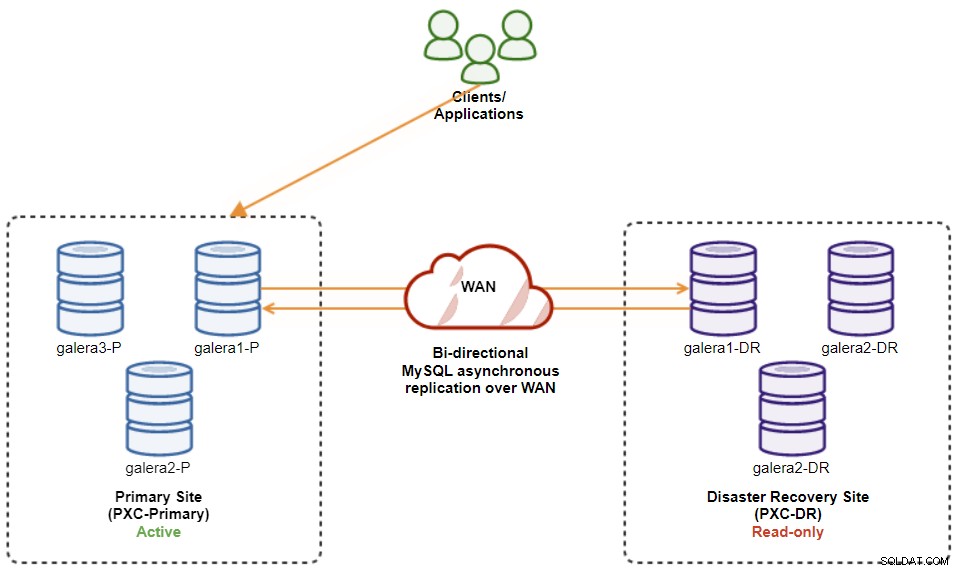
В този момент вече е безопасно да пренасочвате приложенията към писане основния сайт.
Предимства на асинхронната репликация от клъстер към клъстер
Клъстер към клъстер с асинхронна репликация идва с редица предимства:
-
Минимално време на престой по време на операция за преодоляване на база данни. По принцип можете да пренасочите записа почти мигновено към подчинения сайт, само ако можете да защитите записите да не достигат до главния сайт (тъй като тези записи няма да бъдат репликирани и вероятно ще бъдат презаписани при повторно синхронизиране от DR сайта).
-
Няма влияние върху производителността на основния сайт, тъй като той е независим от резервния (DR) сайт. Репликацията от главен към подчинен се извършва асинхронно. Главният сайт генерира двоични регистрационни файлове, подчинения сайт репликира събитията и прилага събитията по-късно.
-
Сайтовете за възстановяване при бедствия могат да се използват за други цели, например архивиране на база данни, архивиране на двоичен регистрационен файл и отчитане, или тежки аналитични заявки (OLAP). И двата сайта могат да се използват едновременно, с изключение на забавянето на репликацията и операциите само за четене на подчинената страна.
-
Клъстерът DR може потенциално да работи на по-малки екземпляри в обществена облачна среда, стига да могат да се справят с първичния клъстер. Можете да надстроите екземплярите, ако е необходимо. При определени сценарии това може да ви спести някои разходи.
-
Необходим ви е само един допълнителен сайт за аварийно възстановяване в сравнение с активна-активна настройка за многосайтова репликация на Galera, която изисква поне три активни сайта, за да работи правилно.
Недостатъци на асинхронната репликация от клъстер към клъстер
Има и недостатъци на тази настройка, в зависимост от това дали използвате двупосочна или еднопосочна репликация:
-
Има вероятност да пропуснете някои данни по време на отказ, ако подчиненият е бил зад, тъй като репликацията е асинхронна. Това може да бъде подобрено с полусинхронна и многонишкова подчинена репликация, въпреки че ще има друг набор от предизвикателства, които чакат (мрежови разходи, пропуски в репликацията и т.н.).
-
При еднопосочна репликация, въпреки че процедурите за преодоляване на отказ са сравнително прости, процедурите за възстановяване при отказ могат да бъдат трудни и предразположени към човешки грешка. Това изисква известен опит за превключване на ролята главен/подчинен обратно към основния сайт. Препоръчително е да поддържате процедурите документирани, да репетирате редовно операцията за превключване/отказ и да използвате точни инструменти за отчитане и наблюдение.
-
Може да струва доста скъпо, тъй като трябва да настроите подобен брой възли на сайта за възстановяване при бедствия . Това не е черно-бяло, тъй като обосновката на разходите обикновено идва от изискванията на вашия бизнес. С известно планиране е възможно да се увеличи максимално използването на ресурсите на базата данни и на двата сайта, независимо от ролите на базата данни.
Приключване
Настройването на асинхронна репликация за вашите MySQL Galera Clusters може да бъде сравнително лесен процес — стига да разбирате как правилно да се справяте с неуспехите както на ниво възел, така и на ниво клъстер. В крайна сметка операциите за преодоляване и възстановяване на отказ са от решаващо значение за гарантиране на целостта на данните.
За повече съвети относно проектирането на вашите клъстери Galera с предвид стратегии за преодоляване и възстановяване при отказ, вижте тази публикация за MySQL архитектури за възстановяване след бедствие. Ако търсите помощ за автоматизирането на тези операции, оценете ClusterControl безплатно за 30 дни и следвайте стъпките в тази публикация.
Не забравяйте да ни последвате в Twitter или LinkedIn и да се абонирате за нашия бюлетин, бъдете информирани за най-новите новини и най-добрите практики за управление на вашата инфраструктура на база данни с отворен код.



