В предишна публикация обсъдихме как можете да поемете контрола върху процеса на отказ в ClusterControl, като използвате бели и черни списъци. В тази публикация ще обсъдим подобна концепция. Но този път ще се съсредоточим върху интеграцията с външни скриптове и приложения чрез множество кукички, предоставени от ClusterControl.
Инфраструктурните среди могат да бъдат изградени по различни начини, тъй като често има много опции за избор за дадено парче от пъзела. Как да дефинираме към кой възел на базата данни да пишем? Използвате ли виртуален IP? Използвате ли някакъв вид откриване на услуга? Може би отивате с DNS записи и променяте A записите, когато е необходимо? Какво ще кажете за прокси слоя? Разчитате ли на стойността „read_only“ за вашите прокси сървъри, за да вземат решение за писателя, или може би правите необходимите промени директно в конфигурацията на проксито? Как вашата среда се справя с превключването? Можете ли просто да продължите и да го изпълните или може би трябва да предприемете някои предварителни действия предварително? Например, спиране на някои други процеси, преди да можете действително да извършите превключването?
Не е възможно софтуерът за преодоляване на отказ да бъде предварително конфигуриран, за да покрива всички различни настройки, които хората могат да създадат. Това е основната причина да се осигурят различни начини за включване в процеса на отказ. По този начин можете да го персонализирате и да направите възможно да се справите с всички тънкости на вашата настройка. В тази публикация в блога ще разгледаме как процесът на отказ на ClusterControl може да бъде персонализиран с помощта на различни скриптове преди и след отказ. Ще обсъдим също някои примери за това какво може да се постигне с такова персонализиране.
Интегриране на ClusterControl
ClusterControl предоставя няколко куки, които могат да се използват за включване на външни скриптове. По-долу ще намерите списък с тези с известно обяснение.
- Replication_onfail_failover_script – този скрипт се изпълнява веднага след като се установи, че е необходимо преминаване при отказ. Ако скриптът върне различен от нула, той ще принуди прекратяването на отказ. Ако скриптът е дефиниран, но не е намерен, преминаването при отказ ще бъде прекратено. На скрипта се предоставят четири аргумента:arg1='all servers' arg2='oldmaster' arg3='candidate', arg4='slaves of oldmaster' и се предават по следния начин:'scripname arg1 arg2 arg3 arg4'. Скриптът трябва да е достъпен на контролера и да е изпълним.
- Replication_pre_failover_script – този скрипт се изпълнява преди преодоляването на отказ да се случи, но след като кандидатът е избран и е възможно да продължи процеса на отказ. Ако скриптът върне различен от нула, той ще принуди прекратяването на отказ. Ако скриптът е дефиниран, но не е намерен, преминаването при отказ ще бъде прекратено. Скриптът трябва да е достъпен на контролера и да е изпълним.
- Replication_post_failover_script – този скрипт се изпълнява, след като се е случило отказът. Ако скриптът върне различен от нула, в дневника на заданията ще бъде записано предупреждение. Скриптът трябва да е достъпен на контролера и да е изпълним.
- Replication_post_unsuccessful_failover_script – Този скрипт се изпълнява след неуспешен опит за преминаване при отказ. Ако скриптът върне различен от нула, в дневника на заданията ще бъде записано предупреждение. Скриптът трябва да е достъпен на контролера и да е изпълним.
- Replication_failed_reslave_failover_script – този скрипт се изпълнява, след като нов главен е бил повишен и ако повторното подчиняване на подчинените към новия главен е неуспешно. Ако скриптът върне различен от нула, в дневника на заданията ще бъде записано предупреждение. Скриптът трябва да е достъпен на контролера и да е изпълним.
- Replication_pre_switchover_script – този скрипт се изпълнява преди да се случи превключването. Ако скриптът върне различен от нула, той ще принуди превключването да се провали. Ако скриптът е дефиниран, но не е намерен, превключването ще бъде прекратено. Скриптът трябва да е достъпен на контролера и да е изпълним.
- Replication_post_switchover_script – този скрипт се изпълнява след превключването. Ако скриптът върне различен от нула, в дневника на заданията ще бъде записано предупреждение. Скриптът трябва да е достъпен на контролера и да е изпълним.
Както можете да видите, куките покриват повечето от случаите, в които може да искате да предприемете някои действия - преди и след превключване, преди и след отказ, когато reslave е неуспешен или когато превключването е неуспешно. Всички скриптове се извикват с четири аргумента (които могат или не могат да се обработват в скрипта, не е задължително скриптът да използва всички тях):всички сървъри, име на хост (или IP - както е дефинирано в ClusterControl) на стария главен, име на хост (или IP - както е дефинирано в ClusterControl) на главния кандидат и четвъртия, всички реплики на стария хозяин. Тези опции трябва да направят възможно справянето с повечето случаи.
Всички тези куки трябва да бъдат дефинирани в конфигурационен файл за даден клъстер (/etc/cmon.d/cmon_X.cnf, където X е идентификаторът на клъстера). Пример може да изглежда така:
replication_pre_failover_script=/usr/bin/stonith.py
replication_post_failover_script=/usr/bin/vipmove.shРазбира се, извиканите скриптове трябва да бъдат изпълними, в противен случай cmon няма да може да ги изпълни. Нека да отделим малко време и да преминем през процеса на отказ в ClusterControl и да видим кога се изпълняват външните скриптове.
Процес при отказ в ClusterControl
Дефинирахме всички налични куки:
replication_onfail_failover_script=/tmp/1.sh
replication_pre_failover_script=/tmp/2.sh
replication_post_failover_script=/tmp/3.sh
replication_post_unsuccessful_failover_script=/tmp/4.sh
replication_failed_reslave_failover_script=/tmp/5.sh
replication_pre_switchover_script=/tmp/6.sh
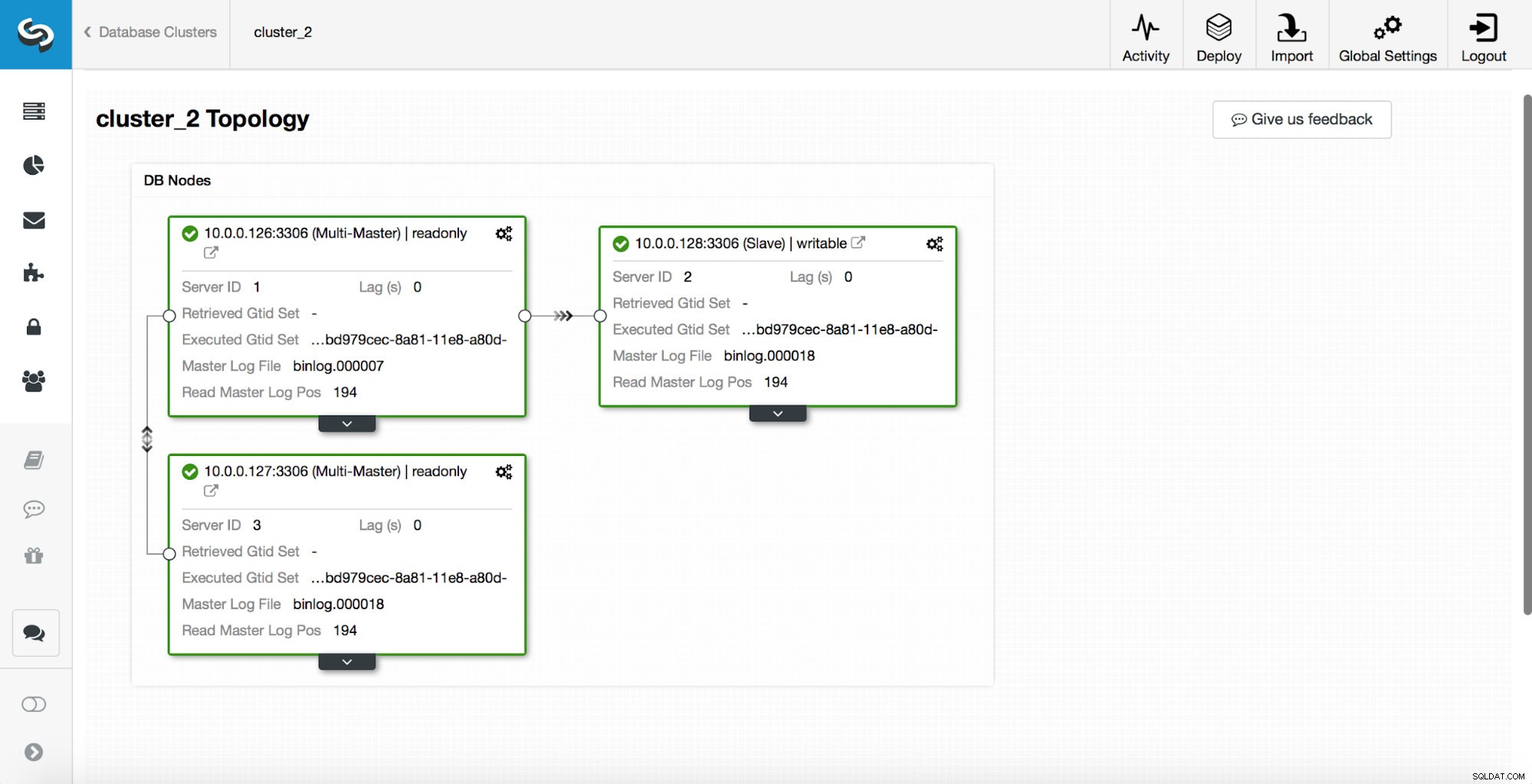
replication_post_switchover_script=/tmp/7.shСлед това трябва да рестартирате процеса на cmon. След като бъде направено, ние сме готови да тестваме отказоустойчивостта. Оригиналната топология изглежда така:
Главният е убит и процесът на отказ е стартиран. Моля, имайте предвид, че по-скорошните записи в регистрационния файл са в горната част, така че искате да следвате преминаването при отказ отдолу нагоре.
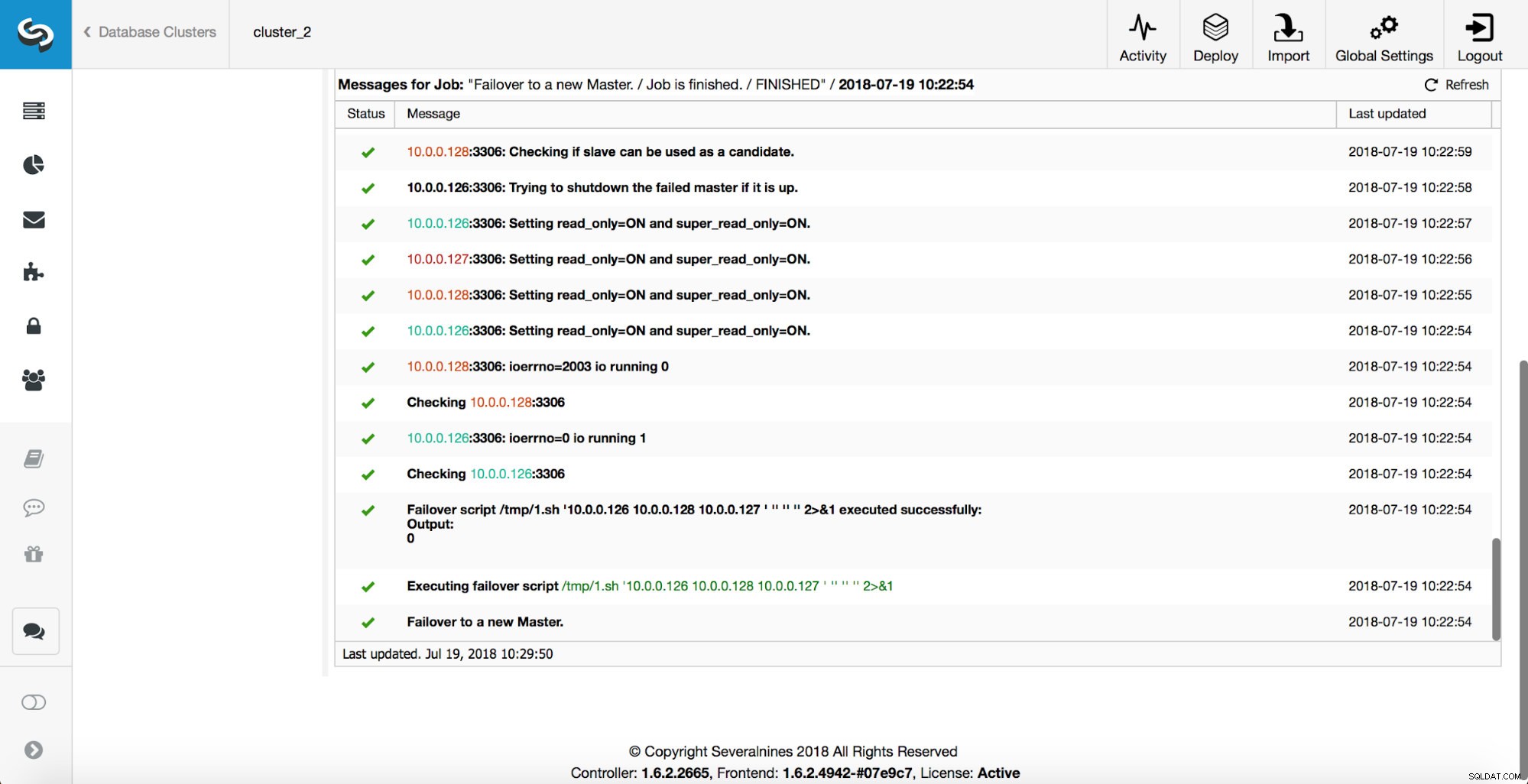
Както можете да видите, веднага след стартиране на задачата за преодоляване на отказ, тя задейства куката „replication_onfail_failover_script“. След това всички достъпни хостове са маркирани като read_only и ClusterControl се опитва да предотврати стартирането на стария главен.
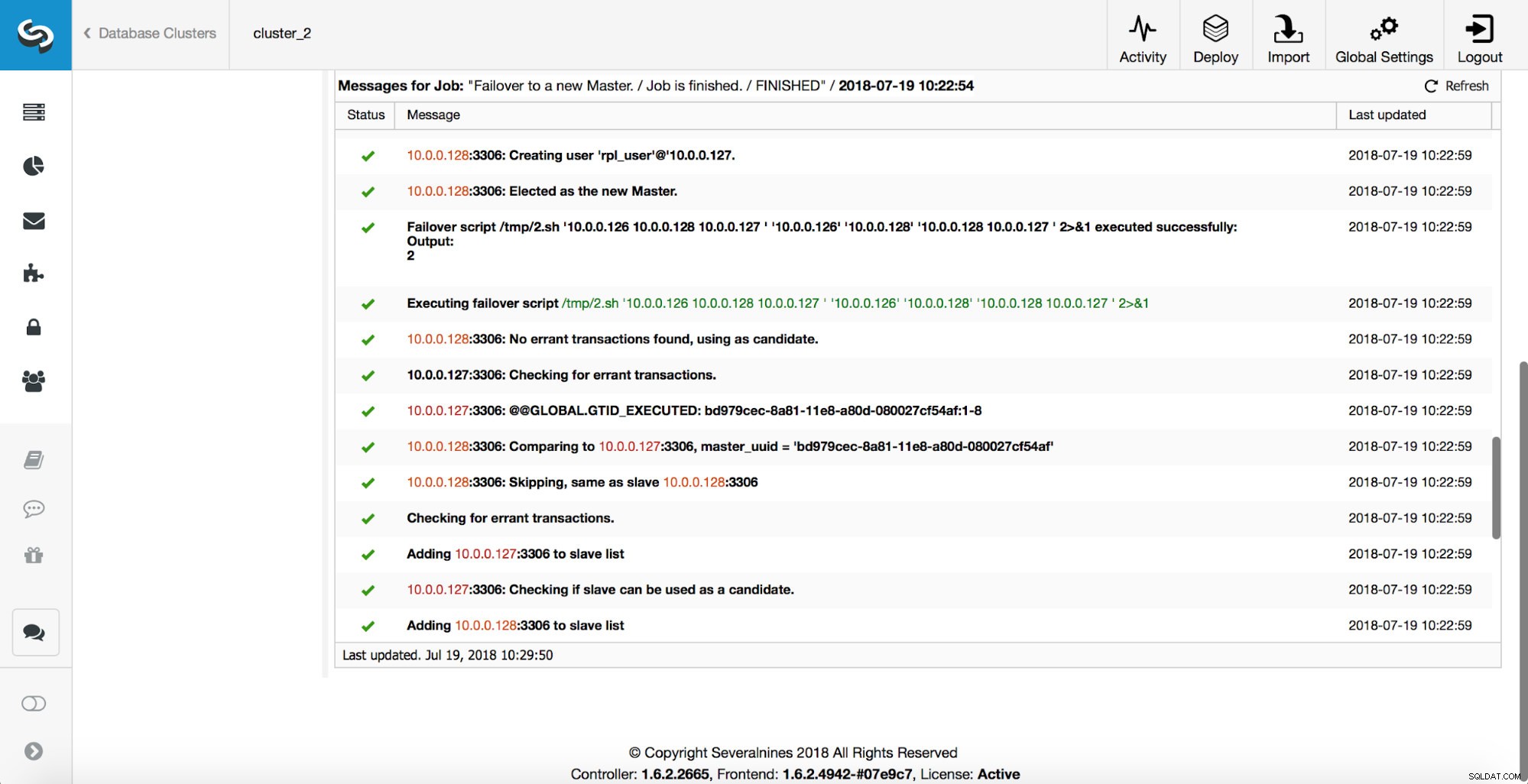
След това се избира главният кандидат, извършват се проверки за здравина. След като бъде потвърдено, че главният кандидат може да се използва като нов главен, се изпълнява „replication_pre_failover_script“.
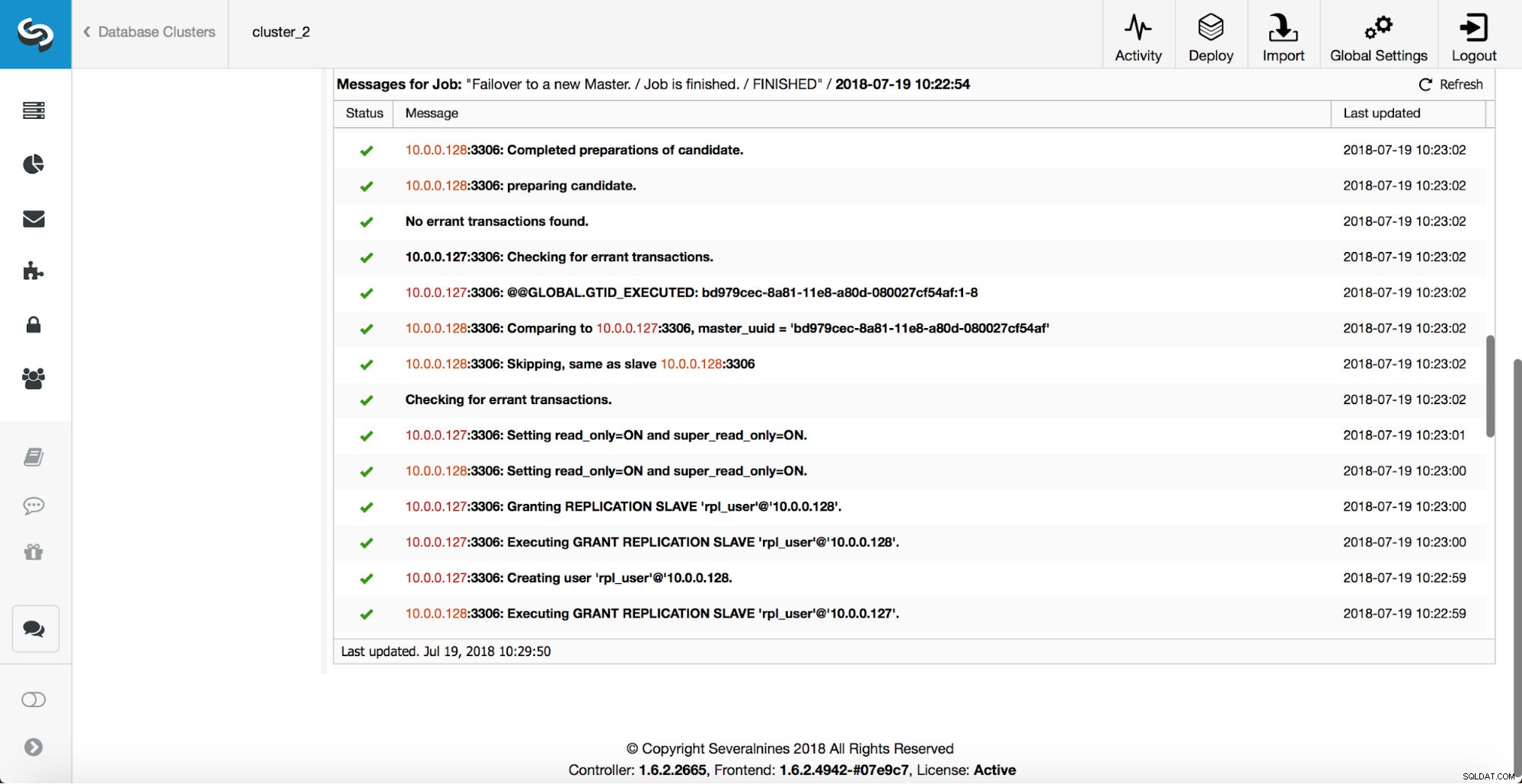
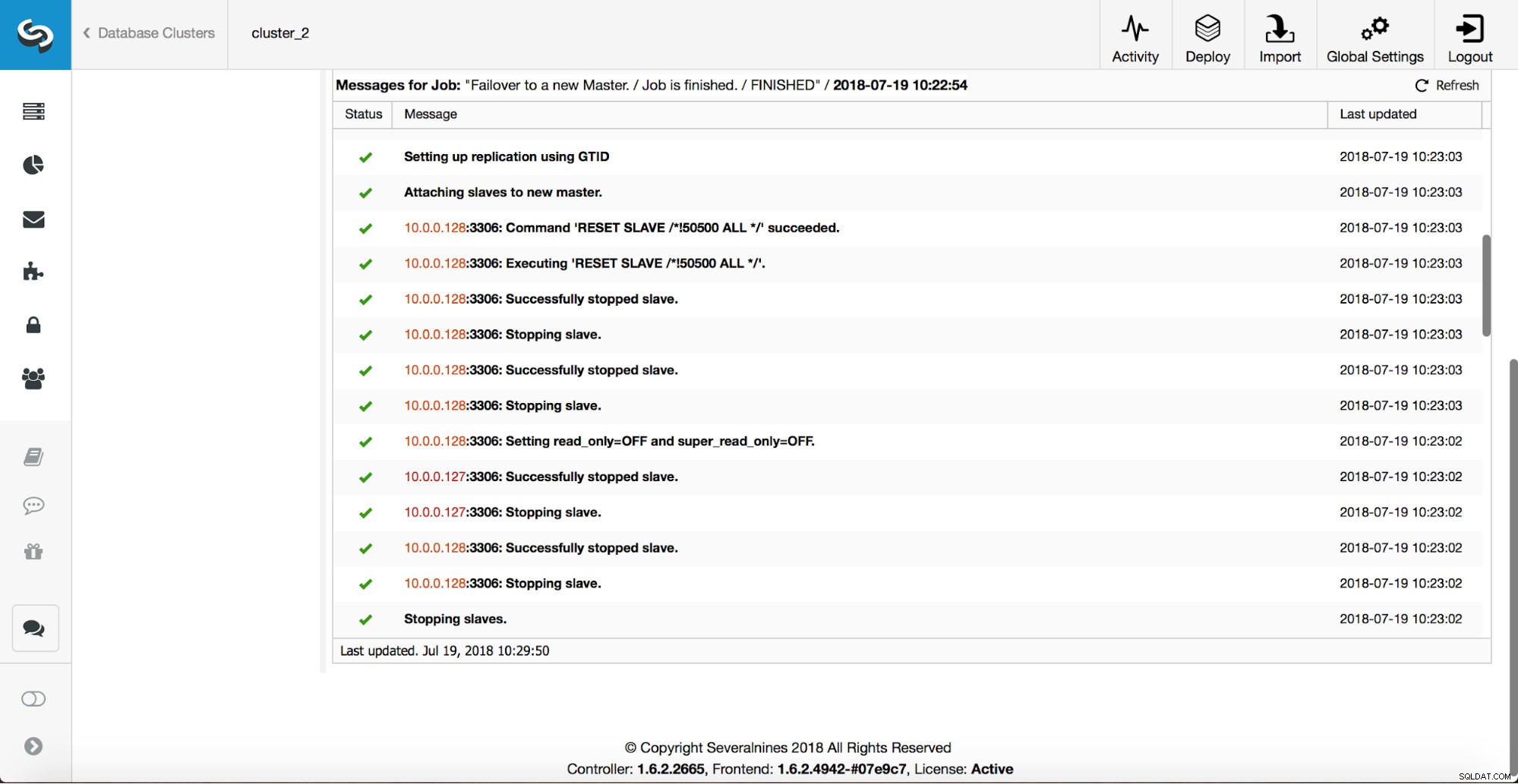
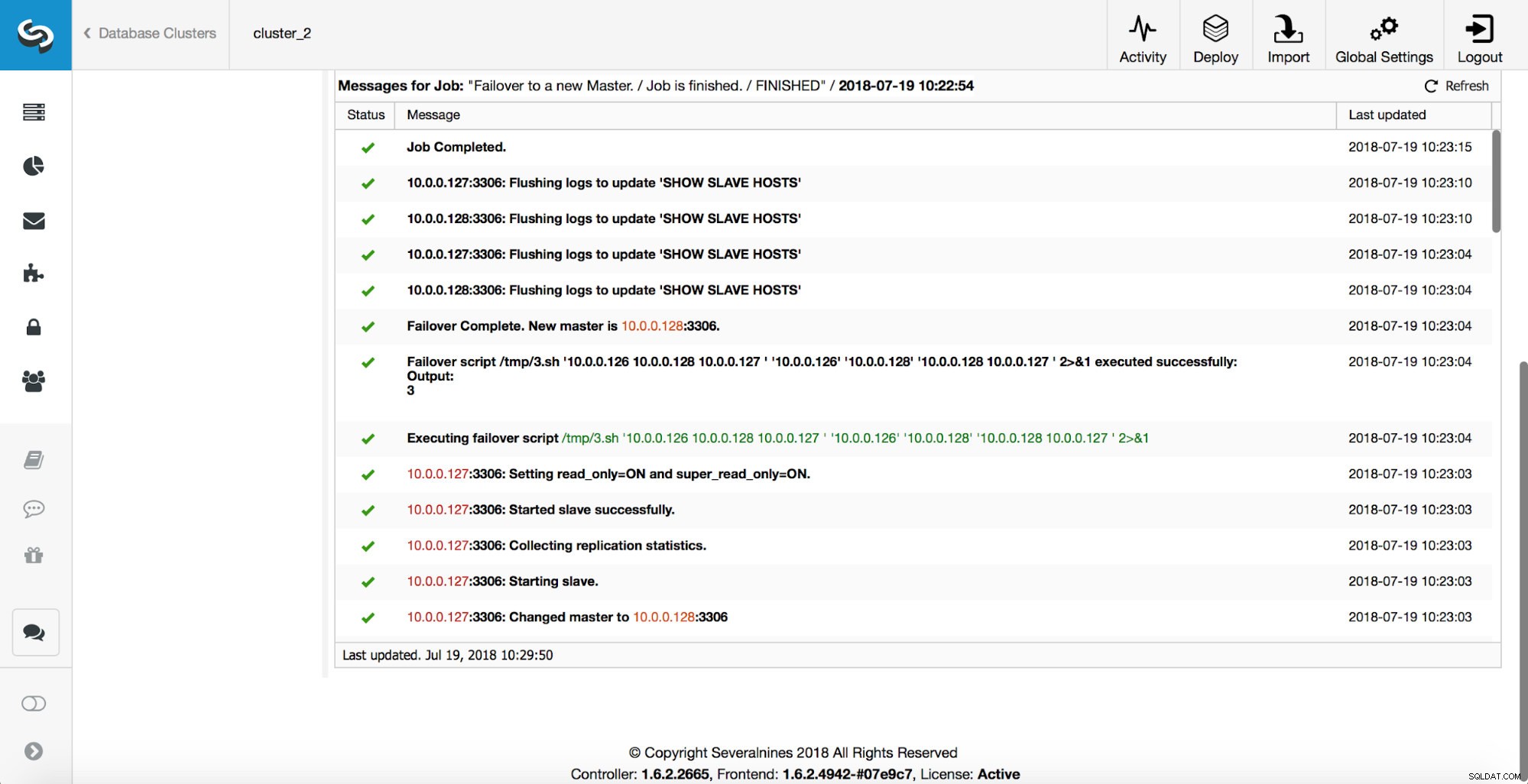
Извършват се повече проверки, репликите се спират и се подчиняват на новия главен. Накрая, след като приключването на отказ е завършено, се задейства окончателна кука, „replication_post_failover_script“.
Кога куките могат да бъдат полезни?
В този раздел ще разгледаме няколко примерни случая, в които може да е добра идея да внедрите външни скриптове. Няма да навлизаме в подробности, тъй като те са твърде тясно свързани с конкретна среда. Това ще бъде по-скоро списък с предложения, които може да са полезни за прилагане.
STONITH скрипт
Shoot The Other Node In The Head (STONITH) е процес, за да се уверите, че старият господар, който е мъртъв, ще остане мъртъв (и да... не харесваме зомбита, които бродят в нашата инфраструктура). Последното нещо, което вероятно искате, е да имате неотговарящ стар мастер, който след това се връща онлайн и в резултат на това ще получите два записващи мастера. Има предпазни мерки, които можете да вземете, за да сте сигурни, че старият главен файл няма да се използва, дори ако се появи отново, и е по-безопасно да остане офлайн. Начините за това как да се гарантира, ще се различават в зависимост от средата. Следователно най-вероятно няма да има вградена поддръжка за STONITH в инструмента за преодоляване на срив. В зависимост от средата, може да искате да изпълните CLI команда, която ще спре (и дори премахне) VM, на която работи старият главен. Ако имате локална настройка, може да имате повече контрол върху хардуера. Може да е възможно да се използва някакъв вид дистанционно управление (интегрирано изключване на осветлението или някакъв друг отдалечен достъп до сървъра). Възможно е също така да имате достъп до управляеми захранващи контакти и да изключите захранването в един от тях, за да сте сигурни, че сървърът никога няма да стартира отново без човешка намеса.
Откриване на услуга
Вече споменахме малко за откриването на услугата. Има много начини, по които човек може да съхранява информация за топологията на репликация и да открие кой хост е главен. Определено една от по-популярните опции е да използвате etc.d или Consul за съхраняване на данни за текущата топология. С него приложение или прокси може да разчита на тези данни за изпращане на трафика към правилния възел. ClusterControl (точно като повечето инструменти, които поддържат обработка на отказ) няма директна интеграция нито с etc.d, нито с Consul. Задачата за актуализиране на топологичните данни е на потребителя. Тя може да използва куки като replication_post_failover_script или replication_post_switchover_script, за да извика някои от скриптовете и да направи необходимите промени. Друго доста често срещано решение е да използвате DNS за насочване на трафика към правилните екземпляри. Ако ще запазите времето на живот на DNS запис ниско, трябва да можете да дефинирате домейн, който ще сочи към вашия главен (т.е. writes.cluster1.example.com). Това изисква промяна в DNS записите и отново куки като replication_post_failover_script или replication_post_switchover_script могат да бъдат наистина полезни за извършване на необходимите модификации след като се случи отказ.
Преконфигуриране на прокси сървър
Всеки използван прокси сървър трябва да изпраща трафик към правилните инстанции. В зависимост от самото прокси, как се извършва главното откриване може да бъде (частично) твърдо кодирано или може да зависи от потребителя да дефинира каквото пожелае. Механизмът за преодоляване на отказ на ClusterControl е проектиран по начин, който се интегрира добре с прокси сървъри, които е разположил и конфигурира. Все още може да се случи, че има прокси сървъри, които не са инсталирани от ClusterControl и те изискват някои ръчни действия, докато се изпълнява отказът. Такива прокси сървъри могат също да бъдат интегрирани с процеса на отказ на ClusterControl чрез външни скриптове и куки като replication_post_failover_script или replication_post_switchover_script.
Допълнително регистриране
Може да се случи, че искате да съберете данни от процеса на отказ за целите на отстраняване на грешки. ClusterControl има обширни разпечатки, за да се увери, че е възможно да се проследи процеса и да се разбере какво се е случило и защо. Все още може да се случи, че искате да съберете допълнителна персонализирана информация. По принцип всички кукички могат да се използват тук - можете да съберете първоначалното състояние, преди преминаването на отказ, можете да проследявате състоянието на средата на всички етапи на отказването.