За да работите ефективно с всяка база данни, трябва да имате представа за производителността на базата данни. Това може да не е очевидно, когато всичко върви добре, но веднага щом нещо се обърка, достъпът до информация може да помогне за бързото и правилно диагностициране на проблема.
Всички бази данни предоставят част от вътрешните си данни за състоянието на потребителите. В MySQL можете да получите тези данни най-вече като изпълните 'SHOW STATUS' и 'SHOW GLOBAL STATUS', като изпълните 'SHOW ENGINE INNODB STATUS', проверите таблици information_schema и, в по-нови версии, като направите заявка за таблици performance_schema.

Тези методи далеч не са удобни в ежедневните операции, оттук и популярността на различни решения за мониторинг и тенденции. Инструменти като Nagios/Icinga са предназначени да наблюдават хостове/услуги и да предупреждават, когато дадена услуга попада извън приемливия диапазон. Други инструменти като Cacti и Munin предоставят графичен поглед върху информацията за хост/услуга и дават исторически контекст на производителността и използването. ClusterControl комбинира тези два вида мониторинг, така че ще разгледаме информацията, която представя, и как трябва да я тълкуваме.
Ако използвате Galera Cluster (MySQL Galera Cluster от Codership или MariaDB Cluster или Percona XtraDB Cluster), може да сте забелязали следния раздел в раздела „Преглед“ на ClusterControl:
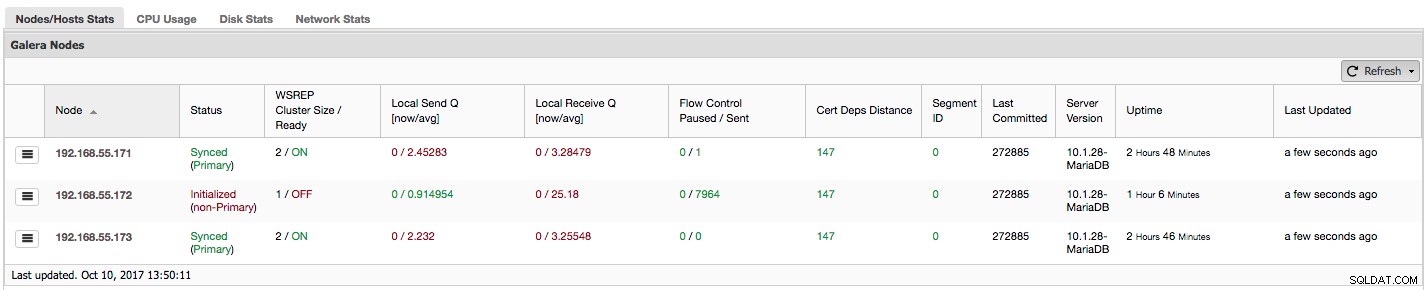
Нека видим, стъпка по стъпка, какви данни имаме тук.
Първата колона съдържа списък с възли с техните IP адреси - няма какво друго да се каже за нея.
Втората колона е по-интересна - описва състоянието на възела (wsrep_local_state_comment състояние). Възелът може да бъде в различни състояния:
- Инициализиран – Възелът е готов и работи, но не е част от клъстер. Може да бъде причинено например от проблеми с мрежата;
- Присъединяване – Възелът е в процес на присъединяване към клъстера и или получава, или иска прехвърляне на състояние от един от другите възли;
- Донор/десинхронизиран – Възелът служи като донор на друг възел, който се присъединява към клъстера;
- Присъединил се – Възелът е присъединен към клъстера, но е зает с наваксване на ангажирани набори за запис;
- Синхронизиран – Възелът работи нормално.
В същата колона в скобата е състоянието на клъстера (wsrep_cluster_status състояние). Може да има три различни състояния:
- Основна – комуникацията между възлите работи и е налице кворум (повечето възли са налични)
- Неосновен – Възелът беше част от клъстера, но по някаква причина загуби контакт с останалата част от клъстера. В резултат на това този възел се счита за неактивен и няма да приема заявки
- Прекъснато свързване – Възелът не можа да установи групова комуникация.
"WSREP Cluster Size / Ready" ни казва за размера на клъстера, както го вижда възелът, и дали възелът е готов да приема заявки. Не-основните компоненти създават клъстер с размер 1 и готовността за wsrep е ИЗКЛЮЧЕНА.
Нека да разгледаме екранната снимка по-горе и да видим какво ни казва за Galera. Можем да видим три възела. Два от тях (192.168.55.171 и 192.168.55.173) са напълно изрядни, и двата са „Синхронизирани“ и клъстерът е в „Основно“ състояние. В момента клъстерът се състои от два възела. Възел 192.168.55.172 е "инициализиран" и образува "не-първичен" компонент. Това означава, че този възел е загубил връзка с клъстера – най-вероятно някакъв вид мрежови проблеми (всъщност използвахме iptables, за да блокираме трафик към този възел както от 192.168.55.171, така и от 192.168.55.173).
В този момент трябва да спрем малко и да опишем как Galera Cluster работи вътрешно. Няма да навлизаме в твърде много подробности, тъй като това не е в обхвата на тази публикация в блога, но са необходими известни познания, за да се разбере важността на данните, представени в следващите колони.
Galera е "практически" синхронен, мулти-главен клъстер. Това означава, че трябва да очаквате данните да се прехвърлят между възли "виртуално" по едно и също време (няма повече досадни проблеми с изоставащите подчинени устройства) и че можете да пишете на всеки възел в клъстер (без повече досадни проблеми с промотирането на подчинен към главен ). За да постигне това, Galera използва набори за запис - атомен набор от промени, които се репликират в клъстера. Наборът за запис може да съдържа няколко промени в редове и допълнителна необходима информация, като данни относно заключването.
След като клиентът издаде COMMIT, но преди MySQL действително да извърши нещо, се създава набор за запис и се изпраща до всички възли в клъстера за сертифициране. Всички възли проверяват дали е възможно да се фиксират промените или не (тъй като промените могат да попречат на други записи, изпълнявани междувременно директно на друг възел). Ако отговорът е да, данните действително се поемат от MySQL, ако не, се изпълнява връщане назад.
Това, което е важно да запомните, е фактът, че възлите, подобно на подчинените при редовна репликация, могат да работят по различен начин - някои може да имат по-добър хардуер от други, някои може да са по-натоварени от други. И все пак Galera изисква от тях да обработват наборите за запис по кратък и бърз начин, за да поддържат „виртуална“ синхронизация. Трябва да има механизъм, който може да намали репликацията и да позволи на по-бавните възли да се справят с останалата част от клъстера.
Нека да разгледаме колоните „Local Send Q [сега/ср.]“ и „Local Receive Q [сега/ср.]“. Всеки възел има локална опашка за изпращане и получаване на набори за запис. Позволява да се паралелизират някои от данните за запис и опашка, които не могат да бъдат обработени наведнъж, ако възелът не може да се справи с трафика. В SHOW GLOBAL STATUS можем да намерим осем брояча, описващи и двете опашки, по четири брояча на опашка:
- wsrep_local_send_queue - текущо състояние на опашката за изпращане
- wsrep_local_send_queue_min - минимум от СТАТУС НА ПРОМИВАНЕ
- wsrep_local_send_queue_max - максимум от СТАТУС НА ПРОМИВАНЕ
- wsrep_local_send_queue_avg - средно от FLUSH STATUS
- wsrep_local_recv_queue - текущо състояние на опашката за получаване
- wsrep_local_recv_queue_min - минимум от СТАТУС НА ПРОМИВАНЕ
- wsrep_local_recv_queue_max - максимум от СТАТУС НА ПРОМИВАНЕ
- wsrep_local_recv_queue_avg - средно от FLUSH STATUS
Горните показатели са обединени между възли под ClusterControl -> Performance -> DB Status:
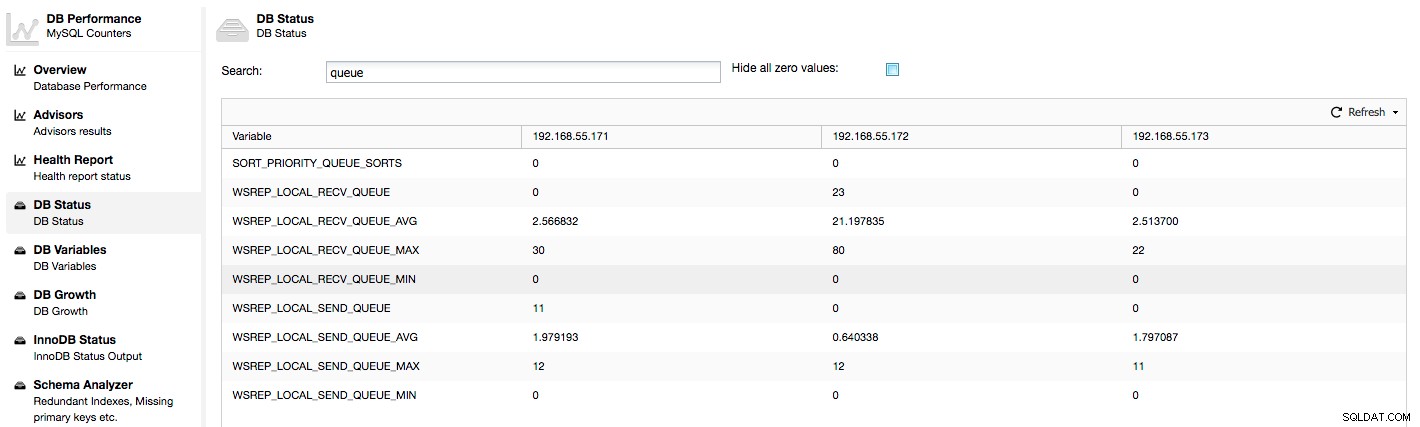
ClusterControl показва броячи "сега" и "средно", тъй като те са най-смислени като едно число (можете също така да създавате персонализирани графики въз основа на променливи, описващи текущото състояние на опашките). Когато видим, че една от опашките се повишава, това означава, че възелът не може да се справи с репликацията и други възли ще трябва да се забавят, за да му позволят да настигне. Бихме препоръчали да проучите работното натоварване на този възел - проверете списъка с процеси за някои продължителни заявки, проверете статистически данни за ОС като използване на процесора и I/O работно натоварване. Може би също така е възможно да се преразпредели част от трафика от този възел към останалата част от клъстера.
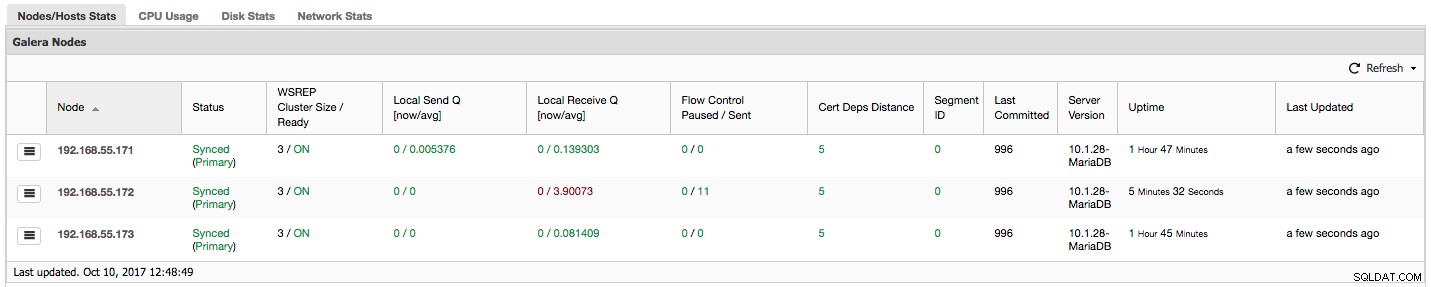
„Управлението на потока е на пауза“ показва информация за процента от времето, през което даден възел е трябвало да спре репликацията си поради твърде голямо натоварване. Когато даден възел не може да се справи с работното натоварване, той изпраща пакети за управление на потока до други възли, като ги информира, че трябва да намалят изпращането на набори за запис. В нашата екранна снимка имаме стойност „0,30“ за възел 192.168.55.172. Това означава, че в почти 30% от времето този възел трябваше да постави на пауза репликацията, защото не беше в състояние да се справи със скоростта на сертифициране на набора за запис, изисквана от други възли (или по-просто, твърде много записи го удрят!). Както виждаме, това е „Local Receive Q [ср.]“ също ни насочва към този факт.
Следващата колона „Изпратено управление на потока“ ни дава информация за това колко пакета за контрол на потока даден възел е изпратил към клъстера. Отново виждаме, че възелът 192.168.55.172 забавя клъстера.
Какво можем да направим с тази информация? Най-вече трябва да проучим какво се случва в бавния възел. Проверете използването на процесора, проверете I/O производителността и мрежовата статистика. Тази първа стъпка помага да преценим какъв проблем сме изправени.
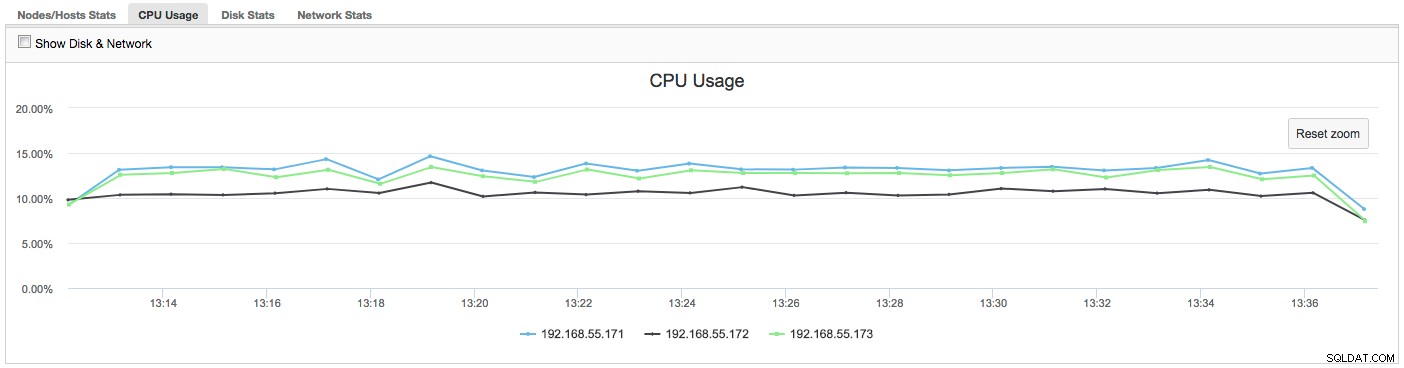
В този случай, след като преминем към раздела Използване на процесора, става ясно, че широкото използване на процесора причинява нашите проблеми. Следващата стъпка би била да се идентифицира виновникът, като се разгледа PROCESSLIST (Монитор на заявки -> Изпълняващи се заявки -> филтър по 192.168.55.172), за да се провери за нарушаващи заявки:
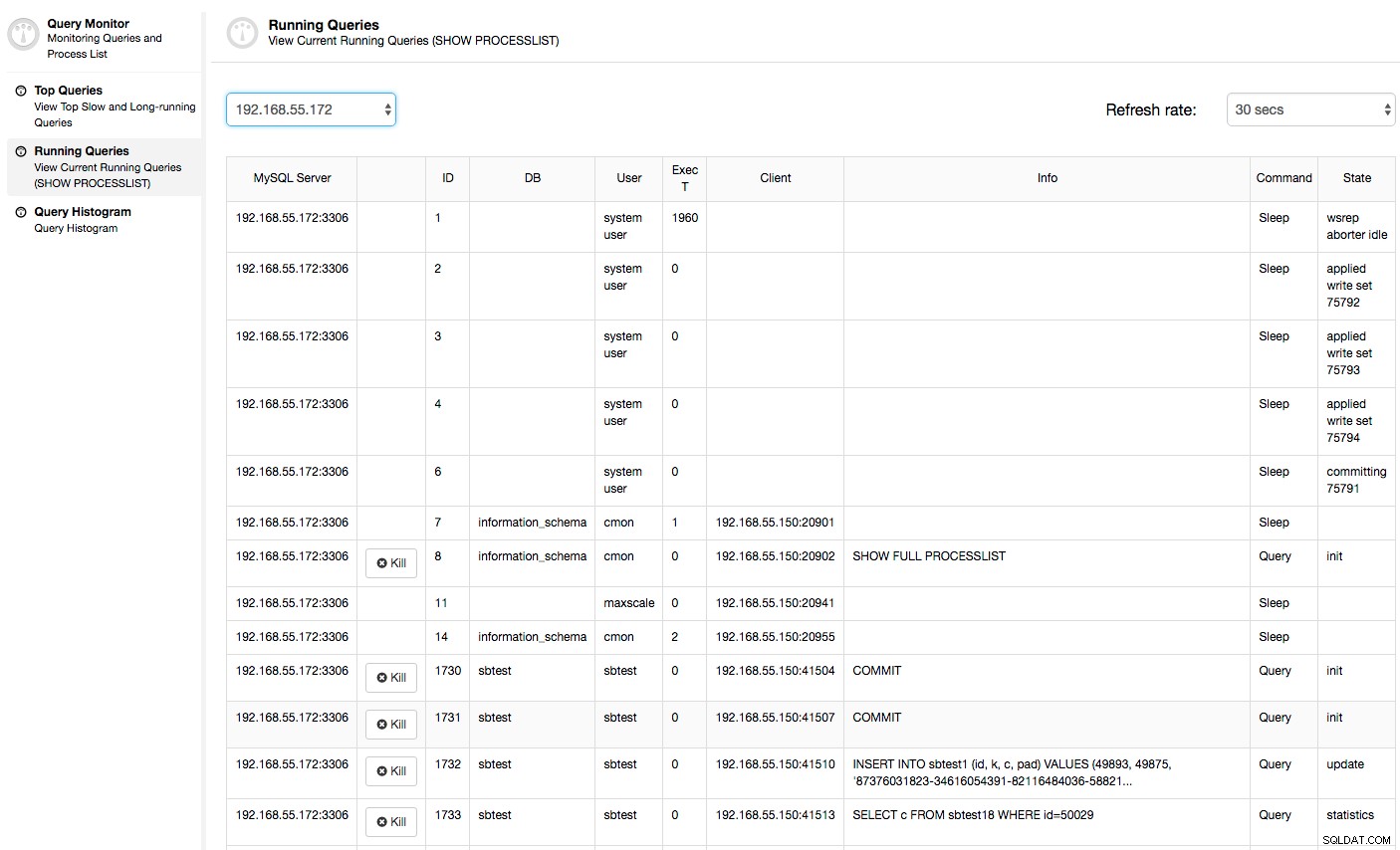
Или проверете процесите на възела от страната на операционната система (Nodes -> 192.168.55.172 -> Top), за да видите дали натоварването не е причинено от нещо извън Galera/MySQL.
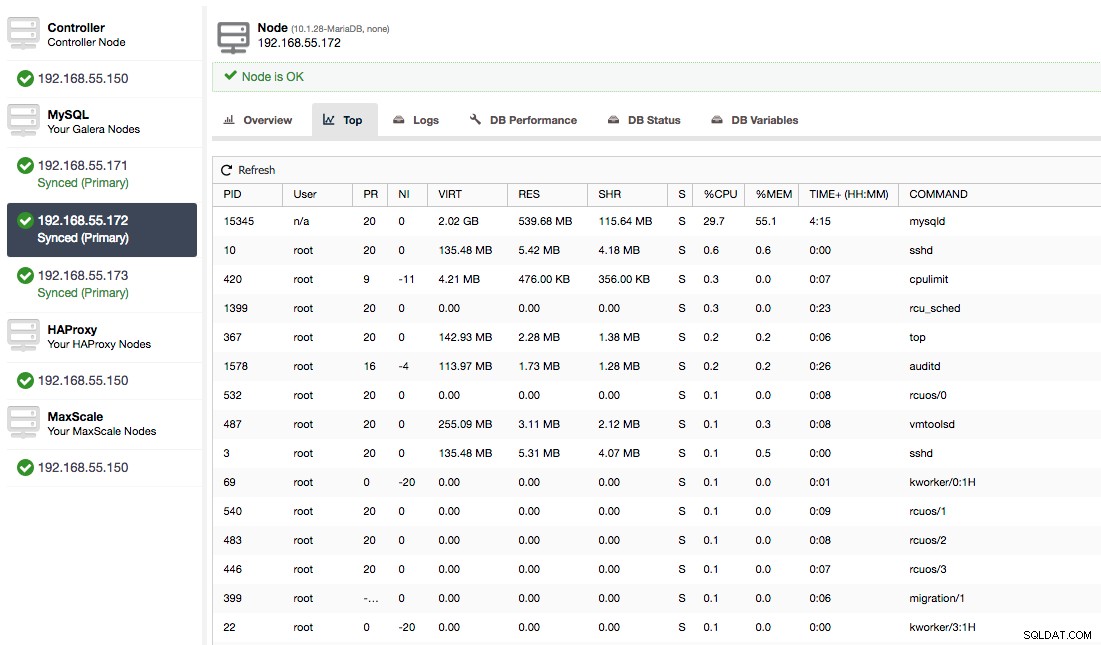
В този случай ние изпълнихме командата mysqld чрез cpulimit, за да симулираме бавното използване на процесора специално за mysqld процес, като го ограничихме до 30% от 400% налични CPU (сървърът има 4 ядра).
Колоната "Cert Deps Distance" ни дава информация за това колко набори за запис средно могат да бъдат приложени паралелно. Понякога наборите за запис могат да се изпълняват едновременно - Galera се възползва от това, като използва множество wsrep_slave_threads за прилагане на набори за запис. Тази колона ви дава представа колко подчинени нишки бихте могли да използвате за вашето работно натоварване. Струва си да се отбележи, че няма смисъл да настройвате wsrep_slave_threads променлива до стойности, по-високи от тези, които виждате в тази колона или в wsrep_cert_deps_distance променлива на състоянието, на която се основава колоната "Cert Deps Distance". Друга важна забележка - също няма смисъл да задавате wsrep_slave_threads променлива за повече от броя ядра, които вашият процесор има.
„Идентификатор на сегмента“ – тази колона ще изисква малко повече обяснения. Сегментите са нова функция, добавена в Galera 3.0. Преди тази версия наборите за запис бяха обменени между всички възли. Да приемем, че имаме два центъра за данни:
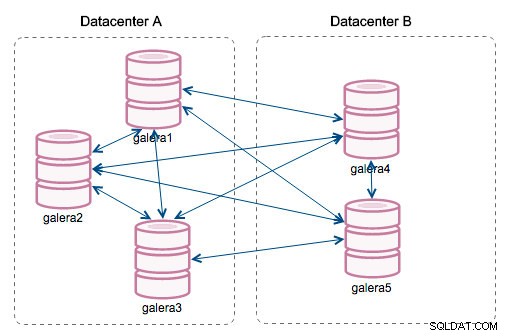
Този вид бърборене работи добре в локалните мрежи, но WAN е различна история – сертифицирането се забавя поради увеличеното латентност, генерират се допълнителни разходи поради мрежовата честотна лента, използвана за прехвърляне на набори за запис между всеки член на клъстера.
С въвеждането на „Сегменти“ нещата се промениха. Можете да присвоите възел към сегмент, като промените wsrep_provider_options променлива и добавяне на "gmcast.segment=x" (0, 1, 2) към нея. Възлите със същия номер на сегмента се третират, тъй като са в същия център за данни, свързани чрез локална мрежа. Тогава нашата графика става различна:
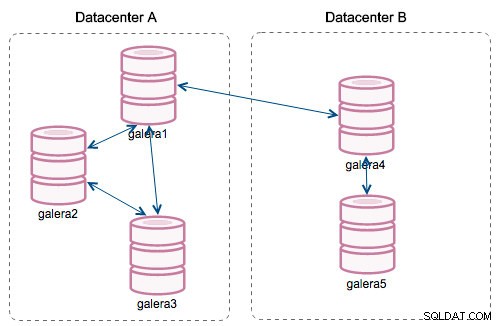
Основната разлика е, че вече не е комуникацията всеки към всеки. В рамките на всеки сегмент, да - все още е един и същ механизъм, но и двата сегмента комуникират само чрез една връзка между два избрани възела. В случай на прекъсване, тази връзка ще премине автоматично. В резултат на това получаваме по-малко мрежови разговори и по-малко използване на честотната лента между отдалечени центрове за данни. Така че по принцип колоната „ID на сегмента“ ни казва към кой сегмент е присвоен възел.
Колоната "Последно извършено" ни дава информация за поредния номер на набора за запис, който последно е бил изпълнен на даден възел. Може да бъде полезно при определяне кой възел е най-актуалният, ако има нужда от стартиране на клъстера.
Останалите колони се обясняват сами:версия на сървъра, време на работа на възел и кога състоянието е актуализирано.
Както можете да видите, секцията „Galera Nodes“ на „Статистика на възлите/хостовете“ в раздела „Преглед“ ви дава доста добро разбиране за здравето на клъстера – дали той образува „основен“ компонент, колко възли са здрави , има ли проблеми с производителността на някои възли и ако да, кой възел забавя клъстера.
Този набор от данни е много удобен, когато управлявате своя клъстер Galera, така че да се надяваме, че няма повече летене на сляпо :-)



