Балансьорите на натоварване са основен компонент във високата наличност на база данни; особено когато правите промените в топологията прозрачни за приложенията и внедрявате функционалност за разделяне на четене и запис. ClusterControl предоставя набор от функции за сигурно внедряване, наблюдение и конфигуриране на водещите в индустрията технологии за балансиране на натоварването с отворен код.
През изминалата година добавихме поддръжка за ProxySQL и добавихме множество подобрения за HAProxy и Maxscale на MariaDB. Продължаваме тази традиция с най-новата версия на ClusterControl 1.5.
Въз основа на обратната връзка, която получихме от нашите потребители, подобрихме как се управлява ProxySQL. Добавихме и поддръжка за HAProxy и Keepalived, за да работят върху PostgreSQL клъстери.
В тази публикация в блога ще разгледаме тези подобрения...
ProxySQL – Подобрения в управлението на потребителите
Преди това потребителският интерфейс ви позволяваше да създадете нов потребител или да добавите съществуващ, един по един. Една обратна връзка, която получихме от нашите потребители, беше, че е доста трудно да се управлява голям брой потребители. Ние слушахме и в ClusterControl 1.5 вече е възможно да се импортират големи партиди потребители. Нека да разгледаме как можете да направите това. На първо място, трябва да разполагате с вашия ProxySQL. След това отидете на възела ProxySQL и в раздела Потребители трябва да видите бутон „Импортиране на потребители“.

След като щракнете върху него, ще се отвори нов диалогов прозорец:

Тук можете да видите всички потребители, които ClusterControl е открил във вашия клъстер. Можете да превъртите през тях и да изберете тези, които искате да импортирате. Можете също да изберете или премахнете избора на всички потребители от текущ изглед.

След като започнете да пишете в полето за търсене, ClusterControl ще филтрира несъответстващи резултати, стеснявайки списъка само до потребители, подходящи за вашето търсене.
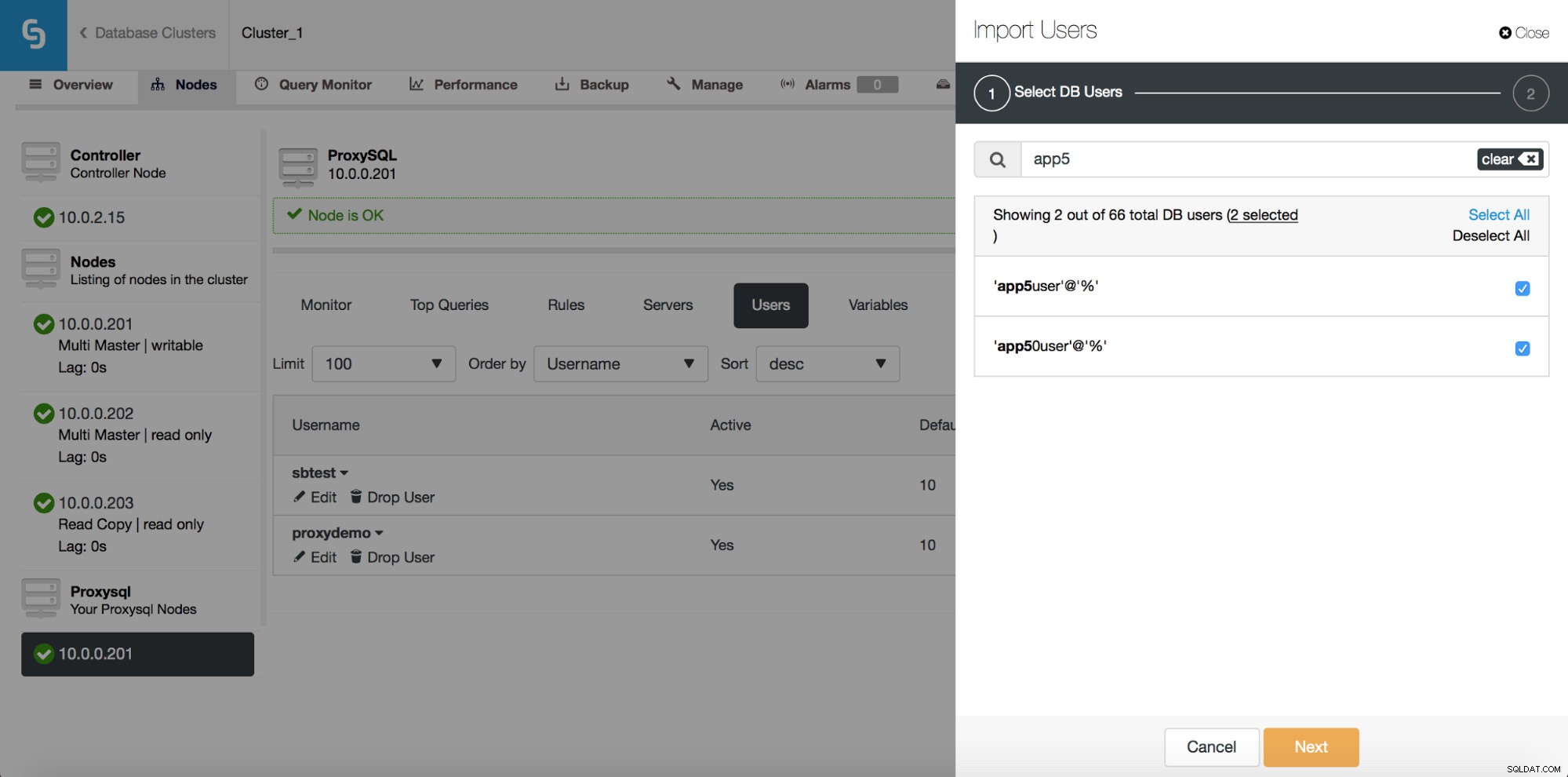
Можете да използвате бутона „Избор на всички“, за да изберете всички потребители, които отговарят на вашето търсене. Разбира се, след като изберете потребители, които искате да импортирате, можете да изчистите полето за търсене и да започнете друго търсене:

Моля, обърнете внимание на „(7 избрани)“ – това ви казва колко потребители, общо (не само от това търсене), сте избрали да импортирате. Можете също да кликнете върху него, за да видите само потребителите, които сте избрали за импортиране.

След като сте доволни от избора си, можете да щракнете върху „Напред“, за да преминете към следващия екран.

Тук трябва да решите каква трябва да бъде хостгрупата по подразбиране за всеки потребител. Можете да направите това за всеки потребител или глобално, за целия набор или подгрупа потребители, получени в резултат на търсене.

След като щракнете върху бутона „Импортиране на потребители“, потребителите ще бъдат импортирани и ще се покажат в раздела Потребители.
ProxySQL – Управление на планировчик
Планировчикът на ProxySQL е модул, подобен на cron, който позволява на ProxySQL да стартира външни скриптове на редовен интервал. Графикът може да бъде доста подробен - до едно изпълнение на всяка милисекунда. Обикновено планировщикът се използва за изпълнение на скриптове за проверка на Galera (като proxysql_galera_checker.sh), но може да се използва и за изпълнение на всеки друг скрипт, който ви харесва. В миналото ClusterControl използваше планировчика за разгръщане на скрипта за проверка на Galera, но това не беше изложено в потребителския интерфейс. Стартирайки ClusterControl 1.5, вече имате пълен контрол.

Както можете да видите, един скрипт е планиран да се изпълнява на всеки 2 секунди (2000 милисекунди) – това е конфигурацията по подразбиране за клъстера Galera.

Горната екранна снимка ни показва опции за редактиране на съществуващи записи. Моля, имайте предвид, че ProxySQL поддържа до 5 аргумента към скриптовете, които ще изпълни чрез планировчика.

Ако искате нов скрипт да бъде добавен към планировчика, можете да щракнете върху бутона „Добавяне на нов скрипт“ и ще ви бъде представен екран като горния. Можете също да прегледате как ще изглежда пълният скрипт, когато бъде изпълнен. След като попълните всички полета „Аргумент“ и определите интервала, можете да кликнете върху бутона „Добавяне на нов скрипт“.

В резултат на това към планировчика ще бъде добавен скрипт и той ще се вижда в списъка с планирани скриптове.
Изтеглете Бялата книга днес Управление и автоматизация на PostgreSQL с ClusterControl Научете какво трябва да знаете, за да внедрите, наблюдавате, управлявате и мащабирате PostgreSQLD Изтеглете Бялата книгаPostgreSQL – Изграждане на стека за висока достъпност
Настройката на репликация с автоматично преминаване на отказ е добра, но приложенията се нуждаят от прост начин за проследяване на записващия главен код. Така че добавихме поддръжка за HAProxy и Keepalived върху PostgreSQL клъстерите. Това позволява на нашите потребители на PostgreSQL да разгръщат пълен стек с висока наличност, използвайки ClusterControl.

От подраздела Load Balancer вече можете да разгръщате HAProxy - ако сте запознати с това как ClusterControl внедрява MySQL репликация, това е много подобна настройка. Инсталираме HAProxy на даден хост, два бекенда, чете на порт 3308 и пише на порт 3307. Той използва tcp-check, очаквайки връщане на конкретен низ. За да се създаде този низ, следните стъпки се изпълняват на всички възли на базата данни. На първо място, xinet.d е конфигуриран да изпълнява услуга на порт 9201 (за да се избегне объркване с настройката на MySQL, която използва порт 9200).
# default: on
# description: postgreschk
service postgreschk
{
flags = REUSE
socket_type = stream
port = 9201
wait = no
user = root
server = /usr/local/sbin/postgreschk
log_on_failure += USERID
disable = no
#only_from = 0.0.0.0/0
only_from = 0.0.0.0/0
per_source = UNLIMITEDУслугата изпълнява /usr/local/sbin/postgreschk скрипт, който потвърждава състоянието на PostgreSQL и казва дали даден хост е наличен и какъв тип хост е (главен или подчинен). Ако всичко е наред, връща низа, очакван от HAProxy.
Точно както при MySQL, HAProxy възлите в PostgreSQL клъстерите се виждат в потребителския интерфейс и може да се осъществи достъп до страницата за състоянието:

Тук можете да видите и двата бекенда и да се уверите, че само главният е готов за r/w бекенда и всички възли могат да бъдат достъпни чрез бекенда само за четене. Можете също да получите някои статистически данни за трафика и връзките.
HAProxy помага за подобряване на високата наличност, но може да се превърне в единична точка на отказ. Трябва да направим допълнителна миля и да конфигурираме излишък с помощта на Keepalived.

Под Управление -> Балансиране на натоварване -> Keepalived избирате HAProxy хостовете, които искате да използвате, и Keepalived ще бъде разгърнат върху тях с виртуален IP, прикачен към избрания от вас интерфейс.
Оттук нататък цялата свързаност трябва да отива към VIP, който ще бъде свързан към един от възлите на HAProxy. Ако този възел падне, Keepalived ще свали VIP на този възел и ще го изведе на друг HAProxy възел.
Това е всичко за функциите за балансиране на натоварването, въведени в ClusterControl 1.5. Опитайте ги и ни уведомете как сте