Sysbench е чудесен инструмент за генериране на тестови данни и извършване на сравнителни показатели за MySQL OLTP. Обикновено се прави цикъл подготовка-изпълнение-почистване, когато се извършва бенчмарк с помощта на Sysbench. По подразбиране таблицата, генерирана от Sysbench, е стандартна базова таблица без дялове. Това поведение може да бъде разширено, разбира се, но трябва да знаете как да го напишете в LUA скрипта.
В тази публикация в блога ще покажем как да генерирате тестови данни за разделена таблица в MySQL с помощта на Sysbench. Това може да се използва като игрална площадка, за да се потопим по-нататък в причинно-следствието от разделянето на таблици, разпределението на данни и маршрутизирането на заявки.
Разделяне на таблица с един сървър
Разделянето на един сървър просто означава, че всички дялове на таблицата се намират на един и същ MySQL сървър/екземпляр. Когато създаваме структурата на таблицата, ще дефинираме всички дялове наведнъж. Този вид разделяне е добър, ако имате данни, които губят своята полезност с течение на времето и могат лесно да бъдат премахнати от разделена таблица, като изхвърлите дяла (или дяловете), съдържащи само тези данни.
Създайте схемата на Sysbench:
mysql> CREATE SCHEMA sbtest;Създайте потребителя на базата данни sysbench:
mysql> CREATE USER 'sbtest'@'%' IDENTIFIED BY 'passw0rd';
mysql> GRANT ALL PRIVILEGES ON sbtest.* TO 'sbtest'@'%';В Sysbench човек би използвал командата --prepare, за да подготви MySQL сървъра със структури на схемата и да генерира редове от данни. Трябва да пропуснем тази част и да дефинираме структурата на таблицата ръчно.
Създайте разделена таблица. В този пример ще създадем само една таблица, наречена sbtest1, и тя ще бъде разделена от колона с име "k", която по същество е цяло число от 0 до 1 000 000 (въз основа на опцията --table-size, която сме ще се използва в операцията само за вмъкване по-късно):
mysql> CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`,`k`)
)
PARTITION BY RANGE (k) (
PARTITION p1 VALUES LESS THAN (499999),
PARTITION p2 VALUES LESS THAN MAXVALUE
);Ще имаме 2 дяла - Първият дял се нарича p1 и ще съхранява данни, където стойността в колона "k" е по-ниска от 499 999, а вторият дял, p2, ще съхранява останалите стойности . Ние също така създаваме първичен ключ, който съдържа и двете важни колони - "id" е за идентификатор на ред, а "k" е ключът на дяла. При разделянето първичният ключ трябва да включва всички колони във функцията за разделяне на таблицата (където използваме "k" във функцията за разделяне на диапазона).
Проверете дали дяловете са там:
mysql> SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA='sbtest2'
AND TABLE_NAME='sbtest1';
+--------------+------------+----------------+------------+
| TABLE_SCHEMA | TABLE_NAME | PARTITION_NAME | TABLE_ROWS |
+--------------+------------+----------------+------------+
| sbtest | sbtest1 | p1 | 0 |
| sbtest | sbtest1 | p2 | 0 |
+--------------+------------+----------------+------------+След това можем да започнем операция само за вмъкване на Sysbench, както следва:
$ sysbench \
/usr/share/sysbench/oltp_insert.lua \
--report-interval=2 \
--threads=4 \
--rate=20 \
--time=9999 \
--db-driver=mysql \
--mysql-host=192.168.11.131 \
--mysql-port=3306 \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=passw0rd \
--tables=1 \
--table-size=1000000 \
runНаблюдавайте как дяловете на таблицата растат, докато Sysbench работи:
mysql> SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA='sbtest2'
AND TABLE_NAME='sbtest1';
+--------------+------------+----------------+------------+
| TABLE_SCHEMA | TABLE_NAME | PARTITION_NAME | TABLE_ROWS |
+--------------+------------+----------------+------------+
| sbtest | sbtest1 | p1 | 1021 |
| sbtest | sbtest1 | p2 | 1644 |
+--------------+------------+----------------+------------+Ако преброим общия брой редове с помощта на функцията COUNT, той ще съответства на общия брой редове, отчетени от дяловете:
mysql> SELECT COUNT(id) FROM sbtest1;
+-----------+
| count(id) |
+-----------+
| 2665 |
+-----------+Това е. Имаме готово разделяне на таблица с един сървър, с което можем да си играем.
Разделяне на таблица с множество сървъри
При разделянето на няколко сървъра ще използваме множество MySQL сървъри, за да съхраняваме физически подмножество от данни на определена таблица (sbtest1), както е показано на следната диаграма:
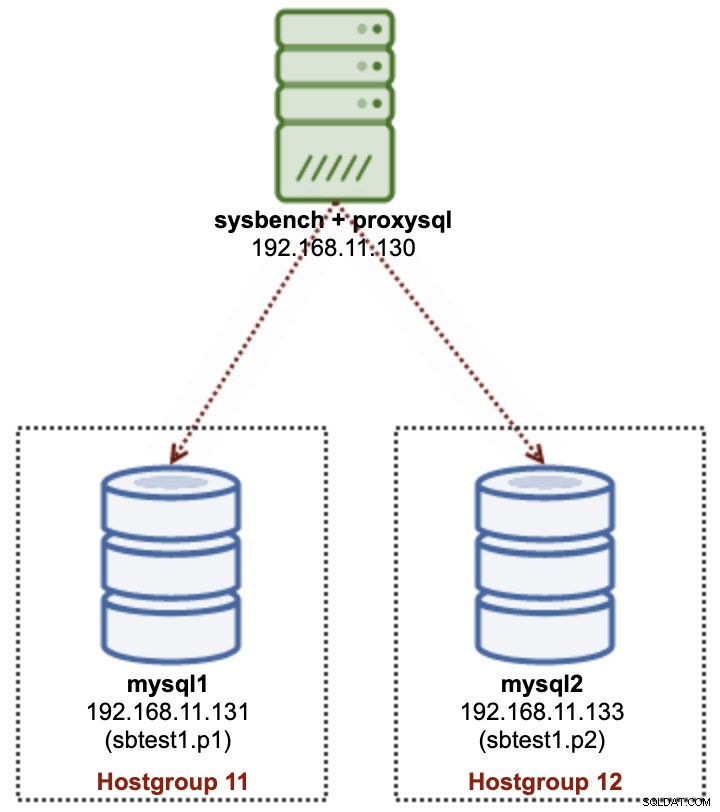
Ще внедрим 2 независими MySQL възела - mysql1 и mysql2. Таблицата sbtest1 ще бъде разделена на тези два възела и ще наречем тази комбинация дял + хост шард. Sysbench работи отдалечено на третия сървър, имитирайки нивото на приложението. Тъй като Sysbench не е наясно с дялове, трябва да имаме драйвер за база данни или рутер, за да насочим заявките към базата данни към десния шард. Ще използваме ProxySQL, за да постигнем тази цел.
Нека създадем друга нова база данни, наречена sbtest3 за тази цел:
mysql> CREATE SCHEMA sbtest3;
mysql> USE sbtest3;Предоставете правилните привилегии на потребителя на базата данни sbtest:
mysql> CREATE USER 'sbtest'@'%' IDENTIFIED BY 'passw0rd';
mysql> GRANT ALL PRIVILEGES ON sbtest3.* TO 'sbtest'@'%';На mysql1 създайте първия дял на таблицата:
mysql> CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`,`k`)
)
PARTITION BY RANGE (k) (
PARTITION p1 VALUES LESS THAN (499999)
);За разлика от самостоятелното разделяне, ние дефинираме само условието за дял p1 в таблицата да съхранява всички редове със стойности на колона "k", вариращи от 0 до 499 999.
На mysql2 създайте друга разделена таблица:
mysql> CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`,`k`)
)
PARTITION BY RANGE (k) (
PARTITION p2 VALUES LESS THAN MAXVALUE
);На втория сървър той трябва да съхранява данните от втория дял, като съхранява останалите от очакваните стойности на колона "k".
Структурата на нашата таблица вече е готова за попълване с тестови данни.
Преди да можем да изпълним операцията само за вмъкване на Sysbench, трябва да инсталираме ProxySQL сървър като рутер за заявки и да действа като шлюз за нашите MySQL фрагменти. Разделянето на множество сървъри изисква връзките към базата данни, идващи от приложенията, да бъдат насочени към правилния шард. В противен случай ще видите следната грешка:
1526 (Table has no partition for value 503599)Инсталирайте ProxySQL с помощта на ClusterControl, добавете потребителя на базата данни sbtest в ProxySQL, добавете и двата MySQL сървъра в ProxySQL и конфигурирайте mysql1 като хостгрупа 11 и mysql2 като хостгрупа 12:
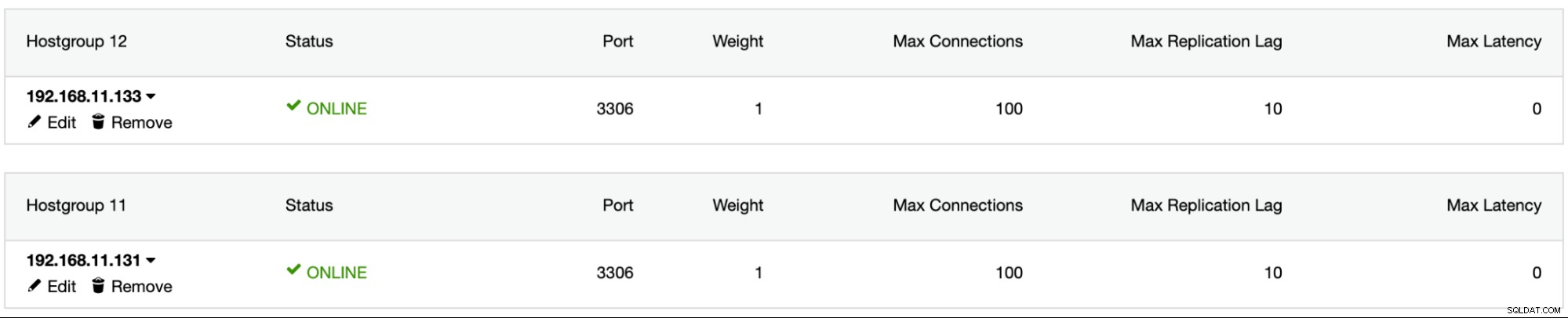
След това трябва да работим върху това как трябва да бъде насочена заявката. Примерна заявка INSERT, която ще бъде изпълнена от Sysbench, ще изглежда така:
INSERT INTO sbtest1 (id, k, c, pad)
VALUES (0, 503502, '88816935247-23939908973-66486617366-05744537902-39238746973-63226063145-55370375476-52424898049-93208870738-99260097520', '36669559817-75903498871-26800752374-15613997245-76119597989')Така че ще използваме следния регулярен израз за филтриране на INSERT заявката за "k" => 500000, за да изпълним условието за разделяне:
^INSERT INTO sbtest1 \(id, k, c, pad\) VALUES \([0-9]\d*, ([5-9]{1,}[0-9]{5}|[1-9]{1,}[0-9]{6,}).*Горният израз просто се опитва да филтрира следното:
-
[0-9]\d* - Тук очакваме цяло число с автоматично увеличение, така че съпоставяме с всяко цяло число.
-
[5-9]{1,}[0-9]{5} - Стойността съответства на всяко цяло число от 5 като първа цифра и 0-9 на последните 5 цифри, за да съответства на стойността на диапазона от 500 000 до 999 999.
-
[1-9]{1,}[0-9]{6,} - Стойността съответства на всяко цяло число от 1-9 като първа цифра и 0-9 на последните 6 или по-големи цифри, за да съответства на стойността от 1 000 000 и повече.
Ще създадем две подобни правила за заявка. Първото правило на заявката е отрицанието на горния регулярен израз. Даваме на това правило идентификатор 51 и целевата хостгрупа трябва да бъде хостгрупа 11, за да съответства на колона "k" <500 000 и да препраща заявките към първия дял. Трябва да изглежда така:
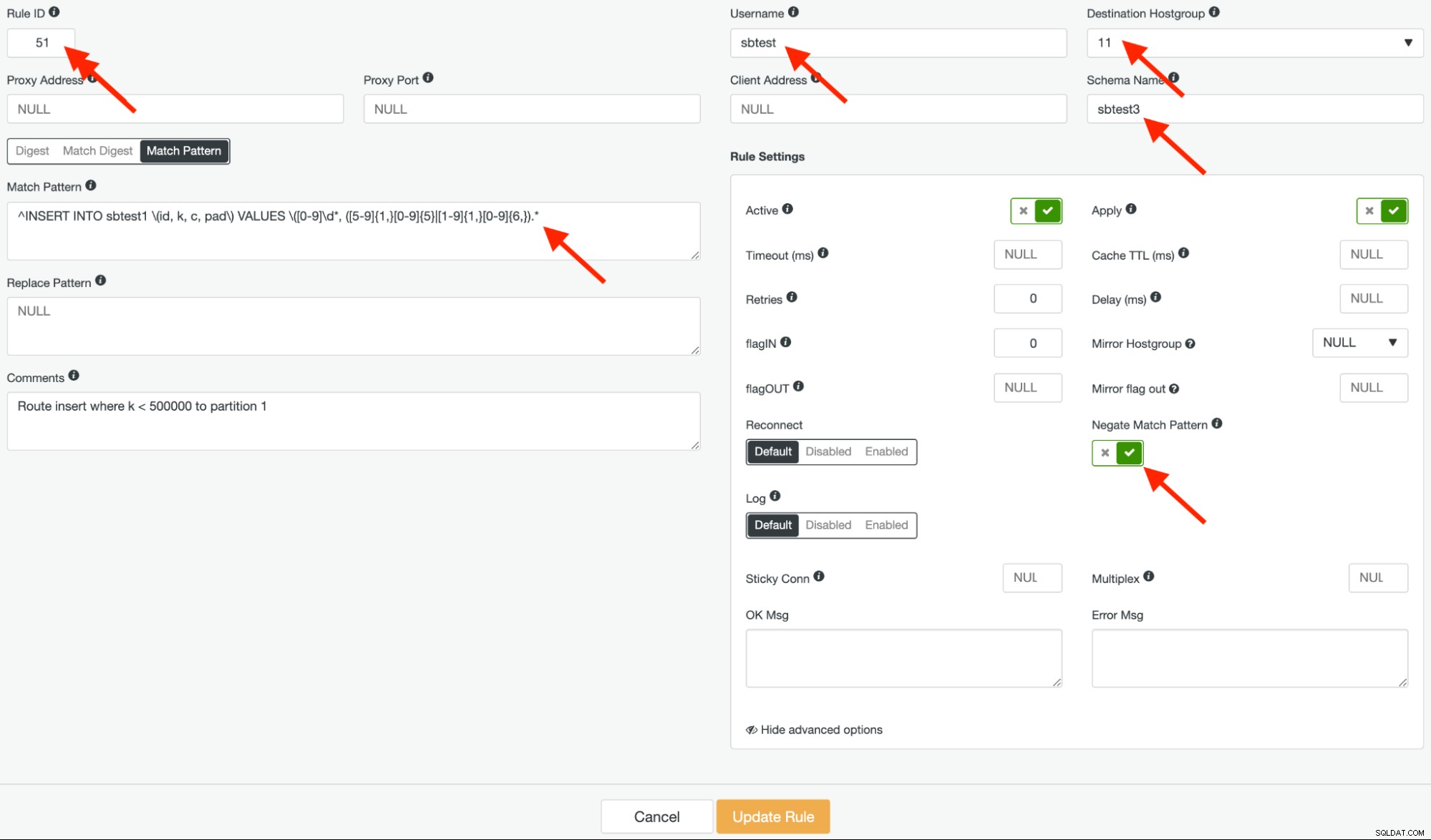
Обърнете внимание на "отрицание на модела на съвпадение" в горната екранна снимка. Тази опция е от решаващо значение за правилното маршрутизиране на това правило за заявка.
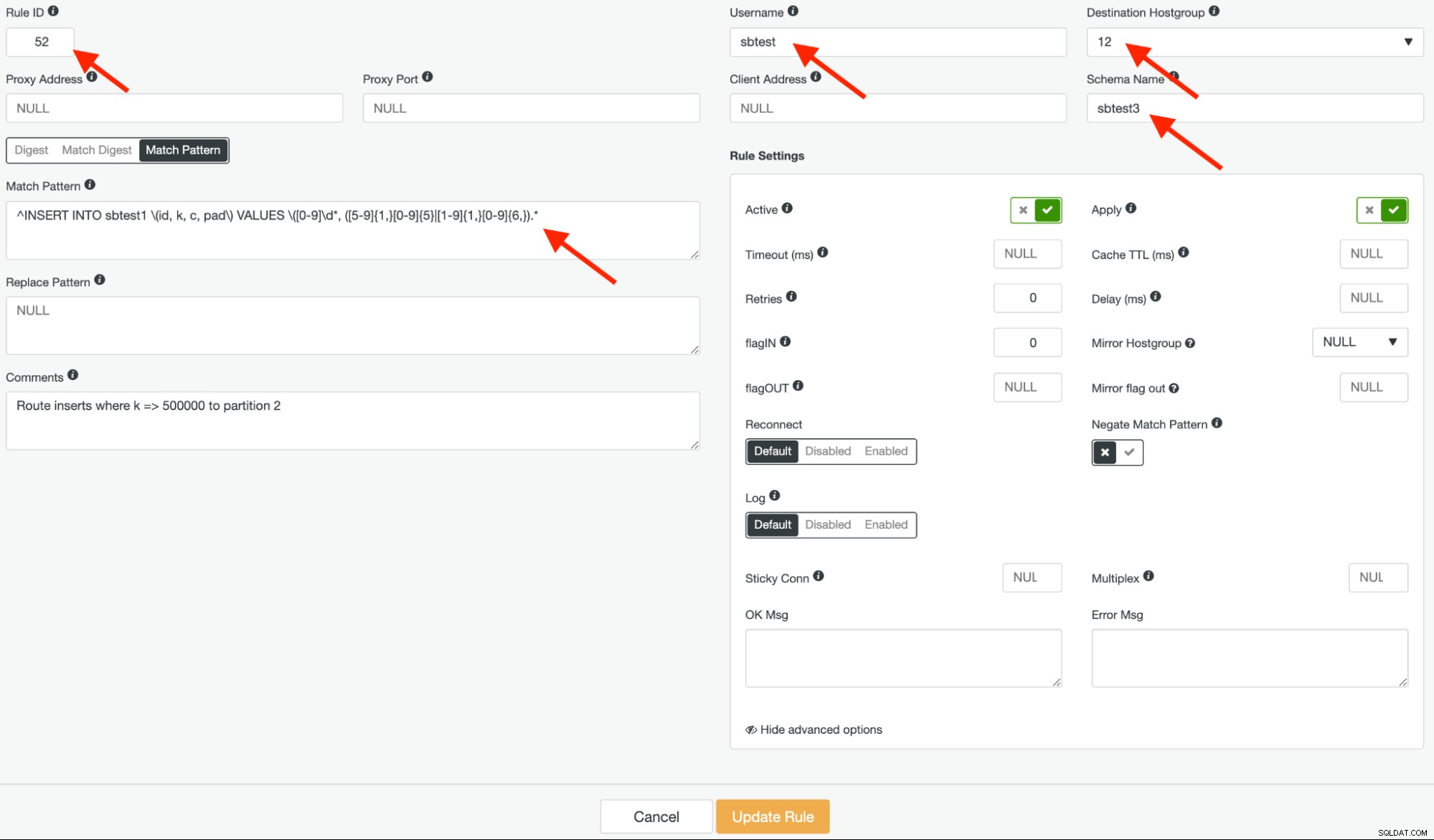
След това създайте друго правило за заявка с идентификатор на правило 52, като използвате същия регулярен израз и целевата хостгрупа трябва да бъде 12, но този път оставете „Негатиран модел на съвпадение“ като false, както е показано по-долу:
След това можем да започнем операция само за вмъкване с помощта на Sysbench за генериране на тестови данни . Информацията, свързана с достъпа до MySQL, трябва да бъде хостът на ProxySQL (192.168.11.130 на порт 6033):
$ sysbench \
/usr/share/sysbench/oltp_insert.lua \
--report-interval=2 \
--threads=4 \
--rate=20 \
--time=9999 \
--db-driver=mysql \
--mysql-host=192.168.11.130 \
--mysql-port=6033 \
--mysql-user=sbtest \
--mysql-db=sbtest3 \
--mysql-password=passw0rd \
--tables=1 \
--table-size=1000000 \
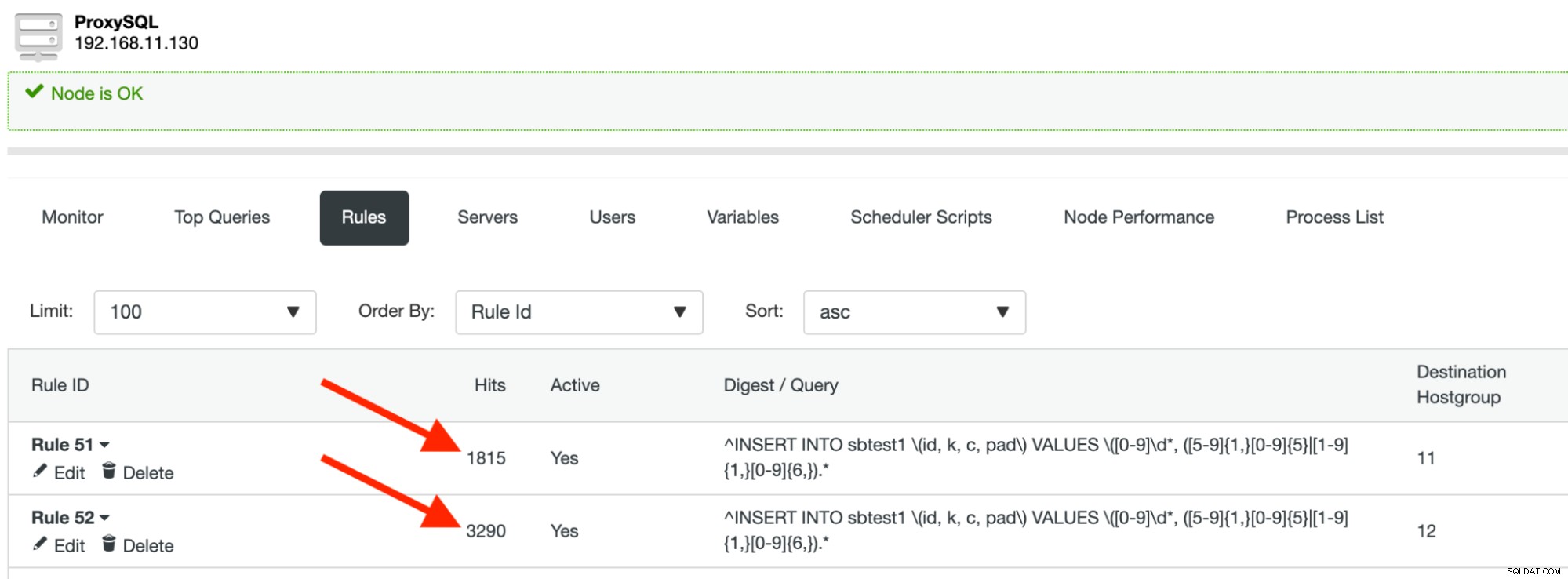
runАко не виждате грешка, това означава, че ProxySQL е насочил нашите заявки към правилния шард/дял. Трябва да видите, че посещенията на правилото за заявка се увеличават, докато процесът на Sysbench работи:
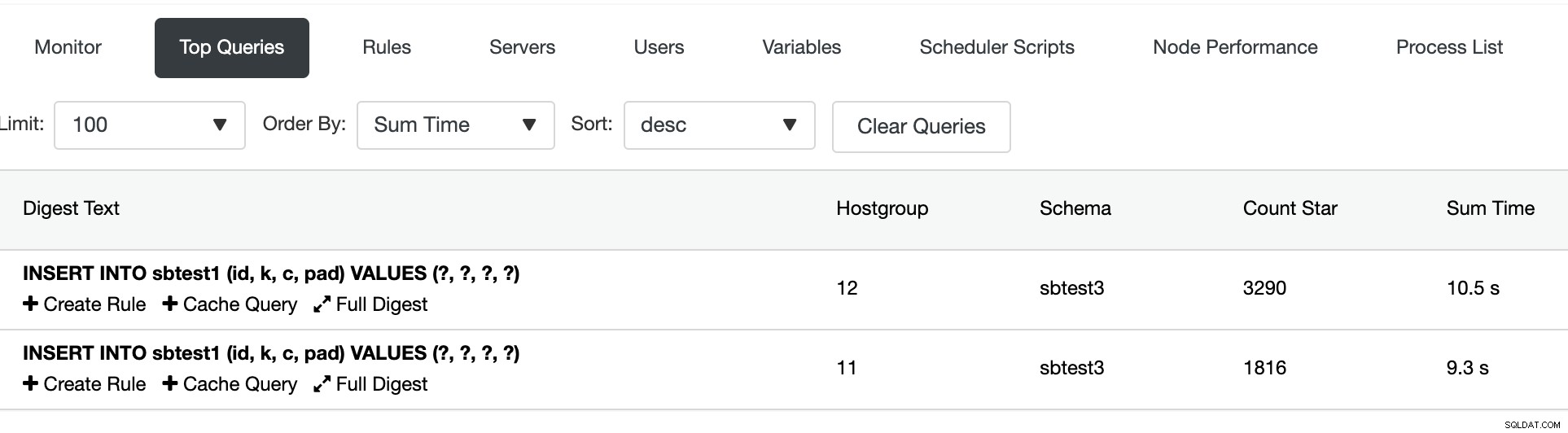
Под секцията Най-популярни заявки можем да видим обобщението на маршрутизирането на заявката:
За да проверите отново, влезте в mysql1, за да потърсите първия дял и проверете минималната и максималната стойност на колона 'k' в таблица sbtest1:
mysql> USE sbtest3;
mysql> SELECT min(k), max(k) FROM sbtest1;
+--------+--------+
| min(k) | max(k) |
+--------+--------+
| 232185 | 499998 |
+--------+--------+Изглежда страхотно. Максималната стойност на колона "k" не надвишава границата от 499 999. Нека проверим броя на редовете, които съхранява за този дял:
mysql> SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA='sbtest3'
AND TABLE_NAME='sbtest1';
+--------------+------------+----------------+------------+
| TABLE_SCHEMA | TABLE_NAME | PARTITION_NAME | TABLE_ROWS |
+--------------+------------+----------------+------------+
| sbtest3 | sbtest1 | p1 | 1815 |
+--------------+------------+----------------+------------+Сега нека проверим другия MySQL сървър (mysql2):
mysql> USE sbtest3;
mysql> SELECT min(k), max(k) FROM sbtest1;
+--------+--------+
| min(k) | max(k) |
+--------+--------+
| 500003 | 794952 |
+--------+--------+Нека проверим броя на редовете, които съхранява за този дял:
mysql> SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA='sbtest3'
AND TABLE_NAME='sbtest1';
+--------------+------------+----------------+------------+
| TABLE_SCHEMA | TABLE_NAME | PARTITION_NAME | TABLE_ROWS |
+--------------+------------+----------------+------------+
| sbtest3 | sbtest1 | p2 | 3247 |
+--------------+------------+----------------+------------+Страхотно! Имаме разчленена тестова настройка на MySQL с правилно разделяне на данни, използвайки Sysbench, с която да си играем. Честит сравнителен анализ!