Цел за време за възстановяване (RTO) е периодът от време, в рамките на който дадена услуга трябва да бъде възстановена, за да се избегнат неприемливи последици. Изчислявайки колко време може да отнеме възстановяването от повреда на базата данни, можем да разберем какво ниво на подготовка е необходимо. Ако RTO е няколко минути, тогава са необходими значителни инвестиции в отказ. RTO от 36 часа изисква значително по-ниска инвестиция. Това е мястото, където идва автоматизацията при отказ.
В предишните ни блогове обсъждахме отказоустойчивост за MongoDB, MySQL/MariaDB/Percona, PostgreSQL или TimeScaleDB. За да обобщим, „Failover " е способността на системата да продължи да функционира, дори ако възникне някаква повреда. Това предполага, че функциите на системата се поемат от вторичните компоненти, ако първичните компоненти се повредят. Отказът е естествена част от всяка система с висока наличност и в някои случаи , дори трябва да се автоматизира. Ръчното превключване на отказ отнема твърде много време, но има случаи, в които автоматизацията няма да работи добре - например в случай на разделен мозък, когато репликацията на базата данни е нарушена и двете „половини“ продължават да получават актуализации, ефективно което води до различни набори от данни и непоследователност.
По-рано писахме за ръководните принципи зад процедурите за автоматично преодоляване на отказ на ClusterControl. Където е възможно, автоматичното преминаване при отказ осигурява ефективност, тъй като позволява бързо възстановяване от повреди. В този блог ще разгледаме как да постигнем автоматично преминаване при отказ при настройка на репликация главен-подчинен (или първичен режим на готовност) с помощта на ClusterControl.
Изисквания за технологичния стек
Стек може да бъде сглобен от компонентите на софтуера с отворен код и има редица налични опции - някои по-подходящи от други в зависимост от характеристиките на отказ, както и нивото на експертен опит за управление и поддръжка на решението. Хардуерът и работата в мрежа също са важни аспекти.
Софтуер
Има много опции, налични в екосистемата с отворен код, които можете да използвате за прилагане на отказ. За MySQL можете да се възползвате от MHA, MMM, Maxscale/MRM, mysqlfailover или Orchestrator. Този предишен блог сравнява MaxScale с MHA с Maxscale/MRM. PostgreSQL има repmgr, Patroni, PostgreSQL Automatic Failover (PAF), pglookout, pgPool-II или stolon. Тези различни опции за висока наличност бяха разгледани по-рано. MongoDB има набори от реплики с поддръжка за автоматично преминаване при отказ.
ClusterControl осигурява автоматична функционалност при отказ за MySQL, MariaDB, PostgreSQL и MongoDB, които ще разгледаме по-долу. Струва си да се отбележи, че има и функционалност за автоматично възстановяване на повредени възли или клъстери.
Хардуер
Автоматичното преминаване на отказ обикновено се извършва от отделен сървър на демон, който е настроен на собствен хардуер - отделно от възлите на базата данни. Той наблюдава състоянието на базите данни и използва информацията, за да взема решения как да реагира в случай на повреда.
Сървърите за стоки могат да работят добре, освен ако сървърът не наблюдава огромен брой случаи. Обикновено системните проверки и здравния анализ са леки по отношение на обработката. Въпреки това, ако имате голям брой възли за проверка, големият процесор и памет са задължителни, особено когато проверките трябва да бъдат наредени на опашка, тъй като се опитва да ping и събира информация от сървърите. Възлите, които се наблюдават и контролират, може да спрат понякога поради проблеми с мрежата, голямо натоварване или в по-лошия случай, те може да не работят поради хардуерна повреда или някаква повреда на хоста на VM. Така че сървърът, който изпълнява проверките на здравето и системата, трябва да може да издържи на такива спирания, тъй като има вероятност обработката на опашките да се увеличи, тъй като отговорите на всеки от наблюдаваните възли може да отнеме време, докато се потвърди, че вече не е наличен или изтече времето за изчакване достигнат.
За облачно-базирани среди има услуги, които предлагат автоматично преминаване при отказ. Например, Amazon RDS използва DRBD за репликиране на хранилище към възел в режим на готовност. Или ако съхранявате вашите томове в EBS, те се репликират в множество зони.
Мрежа
Софтуерът за автоматичен отказ често разчита на агенти, които са настроени на възлите на базата данни. Агентът събира информация локално от екземпляра на базата данни и я изпраща на сървъра, когато бъде поискано.
По отношение на мрежовите изисквания, уверете се, че имате добра честотна лента и стабилна мрежова връзка. Проверките трябва да се правят често, а пропуснатите сърдечни удари поради нестабилна мрежа могат да доведат до софтуерът за преодоляване на срива (погрешно) да заключи, че възел не работи.
ClusterControl не изисква агент, инсталиран на възлите на базата данни, тъй като ще SSH във всеки възел на базата данни на редовни интервали и ще извършва редица проверки.
Автоматично отказване с ClusterControl
ClusterControl предлага възможност за извършване на ръчни, както и автоматизирани откази. Нека видим как може да се направи това.
Отказът в ClusterControl може да бъде конфигуриран да бъде автоматично или не. Ако предпочитате да се погрижите за преминаването при отказ ръчно, можете да деактивирате автоматичното възстановяване на клъстера. Когато извършвате ръчно преминаване на отказ, можете да отидете на Клъстер → Топология в ClusterControl. Вижте екранната снимка по-долу:
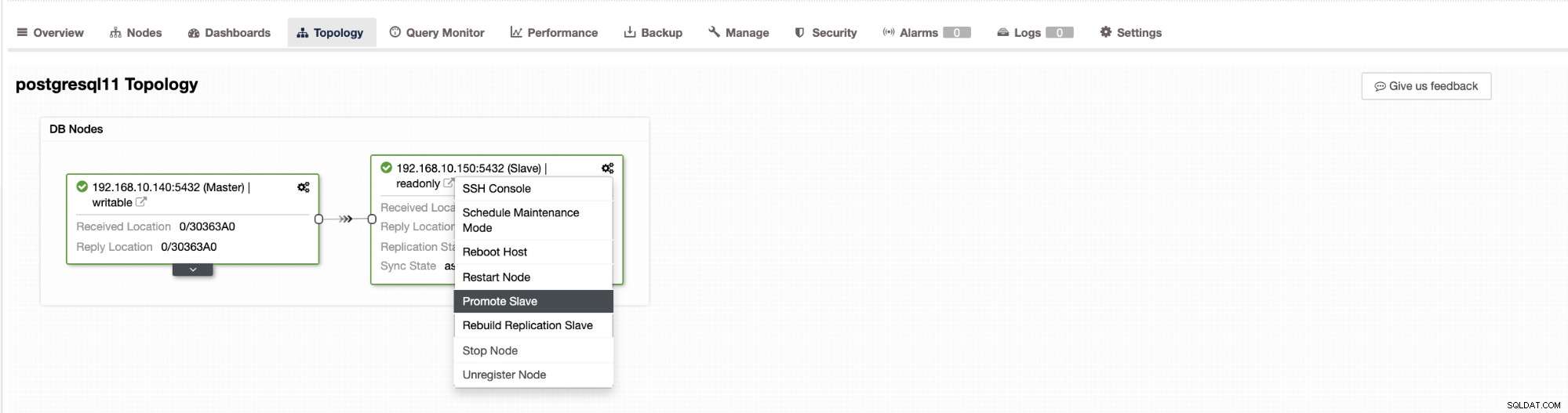
По подразбиране възстановяването на клъстера е активирано и се използва автоматично преминаване при отказ. След като направите промени в потребителския интерфейс, конфигурацията по време на изпълнение се променя. Ако искате настройката да оцелее след рестартиране на контролера, тогава се уверете, че сте направили промяната и в конфигурацията на cmon, т.е. /etc/cmon.d/cmon_

В MySQL/MariaDB/Percona сървър, автоматичното преминаване към отказ се инициира от ClusterControl, когато открие, че няма хост с read_only флагът е деактивиран. Това може да се случи, защото master (който има read_only зададен на 0) не е наличен или може да бъде задействан от потребител или външен софтуер, който е променил този флаг на главния. Ако правите ръчни промени на възлите на базата данни или имате софтуер, който може да се занимава с настройките само за четене, тогава трябва да деактивирате автоматичното преминаване при отказ. Автоматизираното преминаване на отказ на ClusterControl се опитва само веднъж, следователно неуспешно преминаване на отказ няма да бъде последвано отново от последващо превключване на отказ - не докато cmon не бъде рестартиран.
За PostgreSQL ClusterControl ще избере най-модерния подчинен, използвайки за тази цел pg_current_xlog_location (PostgreSQL 9+) или pg_current_wal_lsn (PostgreSQL 10+) в зависимост от версията на нашата база данни. ClusterControl също така извършва няколко проверки на процеса на отказ, за да избегне някои често срещани грешки. Един пример е, че ако успеем да възстановим стария си неуспешен господар, той ще „не " да бъде въведен отново автоматично в клъстера, нито като главен, нито като подчинен. Трябва да го направим ръчно. Това ще избегне възможността за загуба на данни или несъответствие в случай, че нашият подчинен (който поощряхме) е бил забавен в момента на неуспеха. Може също да искаме да анализираме проблема подробно, преди да го въведем отново в настройката за репликация, така че бихме искали да запазим диагностичната информация.
Освен това, ако преминаването при отказ не успее, не се правят допълнителни опити (това се отнася както за PostgreSQL, така и за базираните на MySQL клъстери), е необходима ръчна намеса за анализ на проблема и извършване на съответните действия. Това е, за да се избегне ситуацията, при която ClusterControl, който се справя с автоматичното преминаване на отказ, се опитва да промотира следващия подчинен и следващия. Възможно е да има проблем и ние не искаме да влошаваме нещата, като се опитваме да превключваме на множество откази.
ClusterControl предлага бели и черни списъци на набор от сървъри, които искате да участвате в преодоляването на отказ или да изключите като кандидат.
За клъстери от тип MySQL, ClusterControl изгражда списък от подчинени устройства, които могат да бъдат повишени в главен. През повечето време той ще съдържа всички подчинени устройства в топологията, но потребителят има допълнителен контрол върху него. Има две променливи, които можете да зададете в конфигурацията на cmon:
replication_failover_whitelistи
replication_failover_blacklistЗа конфигурационната променлива replication_failover_whitelist, тя съдържа списък с IP адреси или имена на хостове на подчинени устройства, които трябва да се използват като потенциални кандидати за главни. Ако тази променлива е зададена, ще бъдат взети предвид само тези хостове. За променлива replication_failover_blacklist, той съдържа списък с хостове, които никога няма да се считат за главен кандидат. Можете да го използвате, за да изброите подчинени устройства, които се използват за архивиране или аналитични заявки. Ако хардуерът варира между подчинените, може да искате да поставите тук подчинените, които използват по-бавен хардуер.
replication_failover_whitelist има предимство, което означава, че replication_failover_blacklist се игнорира, ако replication_failover_whitelist е зададен.
След като списъкът на подчинените, които могат да бъдат повишени в главен, е готов, ClusterControl започва да сравнява тяхното състояние, търсейки най-актуалния подчинен. Тук обработката на базираните на MariaDB и MySQL настройки се различава. За настройките на MariaDB, ClusterControl избира подчинен, който има най-ниското забавяне на репликация от всички налични подчинени устройства. За настройките на MySQL ClusterControl също избира такъв подчинен, но след това проверява за допълнителни, липсващи транзакции, които биха могли да бъдат изпълнени на някои от останалите подчинени устройства. Ако бъде открита такава транзакция, ClusterControl подчинява главния кандидат от този хост, за да извлече всички липсващи транзакции. Можете да пропуснете този процес и просто да използвате най-модерния подчинен, като зададете променлива replication_skip_apply_missing_txs във вашата CMON конфигурация:
напр.
replication_skip_apply_missing_txs=1Вижте нашата документация тук за повече информация с променливи.
Предупреждението е, че трябва да зададете това само ако знаете какво правите, тъй като може да има грешни транзакции. Това може да доведе до прекъсване на репликацията, както и несъответствие на данните в клъстера. Ако грешната транзакция се е случила в миналото, тя може вече да не е налична в двоичните регистрационни файлове. В този случай репликацията ще се счупи, защото подчинените няма да могат да извлекат липсващите данни. Следователно ClusterControl по подразбиране проверява за всякакви грешни транзакции, преди да повиши главен кандидат да стане главен. Ако се открие такъв проблем, главният превключвател се прекратява и ClusterControl позволява на потребителя да отстрани проблема ръчно.
Ако искате да сте 100% сигурни, че ClusterControl ще популяризира нов главен код, дори ако бъдат открити някои проблеми, можете да направите това с помощта на променливата replication_stop_on_error. Вижте по-долу:
напр.
replication_stop_on_error=0Задайте тази променлива във вашия конфигурационен файл cmon. Както бе споменато по-рано, това може да доведе до проблеми с репликацията, тъй като подчинените могат да започнат да искат двоичен дневник, който вече не е наличен. За да се справим с такива случаи, добавихме експериментална поддръжка за възстановяване на подчинени устройства. Ако зададете променливата
replication_auto_rebuild_slave=1в конфигурацията на cmon и ако вашият подчинен е маркиран като надолу със следната грешка в MySQL:
Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'ClusterControl ще се опита да възстанови подчинения, използвайки данни от главния. Такава настройка може да не винаги е подходяща, тъй като процесът на възстановяване ще предизвика повишено натоварване на главния. Възможно е също така наборът ви от данни да е много голям и редовното възстановяване не е опция – ето защо това поведение е деактивирано по подразбиране.
След като се уверим, че няма грешна транзакция и сме готови, има още един проблем, с който трябва да се справим по някакъв начин – може да се случи, че всички подчинени устройства изостават от главния.
Както вероятно знаете, репликацията в MySQL работи по доста прост начин. Главният магазин записва в двоични регистрационни файлове. I/O нишката на подчинения се свързва с главната и изтегля всички двоични регистрационни събития, които липсват. След това ги съхранява под формата на релейни регистрационни файлове. SQL нишката ги анализира и прилага събития. Подчинено забавяне е състояние, при което SQL нишката (или нишките) не може да се справи с броя на събитията и не е в състояние да ги приложи веднага щом бъдат изтеглени от главната от I/O нишката. Такава ситуация може да се случи, независимо какъв тип репликация използвате. Дори ако използвате полу-синхронизирана репликация, това може само да гарантира, че всички събития от главната машина се съхраняват на един от подчинените в регистрационния файл на релето. Не се казва нищо за прилагането на тези събития към роб.
Проблемът тук е, че ако подчинен бъде повишен в главен, регистрите на релето ще бъдат изтрити. Ако подчинено устройство изостава и не е приложило всички транзакции, то ще загуби данни - събития, които все още не са приложени от регистрационните файлове на релето, ще бъдат загубени завинаги.
Няма универсален начин за разрешаване на тази ситуация. ClusterControl дава на потребителите контрол върху това как трябва да се направи, като поддържа безопасни настройки по подразбиране. Извършва се в cmon конфигурация, като се използва следната настройка:
replication_failover_wait_to_apply_timeout=-1По подразбиране той приема стойност „-1“, което означава, че преминаването при отказ няма да се случи веднага, ако главен кандидат изостава, така че е настроен да чака завинаги, освен ако кандидатът не е наваксвал. ClusterControl ще чака неограничено време, докато приложи всички липсващи транзакции от своите релейни регистрационни файлове. Това е безопасно, но ако по някаква причина най-актуалното подчинено устройство изостава силно, преминаването при отказ може да отнеме часове. От другата страна на спектъра го настройвате на „0“ – това означава, че преодоляването на срив се случва незабавно, без значение дали главният кандидат изостава или не. Можете също да отидете по средния път и да го зададете на някаква стойност. Това ще зададе време в секунди, например 30 секунди, така че задайте променливата на,
replication_failover_wait_to_apply_timeout=30Когато е зададен на> 0, ClusterControl ще изчака главен кандидат да приложи липсващи транзакции от своите релейни регистрационни файлове, докато стойността не бъде изпълнена (което е 30 секунди в примера). Отказът се случва след определеното време или когато главният кандидат ще настигне репликацията, което от двете се случи първо. Това може да е добър избор, ако приложението ви има специфични изисквания по отношение на престоя и трябва да изберете нов главен в рамките на кратък период от време.
За повече подробности относно това как ClusterControl работи с автоматично преминаване на отказ в PostgreSQL и MySQL, разгледайте предишните ни блогове, озаглавени „Failover for PostgreSQL Replication 101“ и „Автоматично преминаване на отказ на MySQL репликация – Ново в ClusterControl 1.4“.
Заключение
Автоматизираното отказване е ценна функция, особено за бизнеси, които изискват 24/7 операции с минимално време на престой. Бизнесът трябва да определи колко контрол се предоставя на процеса на автоматизация по време на непланирани прекъсвания. Решение с висока наличност като ClusterControl предлага персонализирано ниво на взаимодействие при обработка на отказ. За някои организации автоматичното преминаване на отказ може да не е опция, въпреки че взаимодействието на потребителя по време на отказ може да изяде време и да повлияе на RTO. Предположението е, че е твърде рисковано в случай, че автоматизираното преминаване на отказ не работи правилно или, още по-лошо, това води до объркани и частично липсващи данни (въпреки че може да се твърди, че човек също може да направи катастрофални грешки, водещи до подобни последици). Тези, които предпочитат да поддържат строг контрол върху своята база данни, могат да изберат да пропуснат автоматичното преминаване при отказ и вместо това да използват ръчен процес. Такъв процес отнема повече време, но позволява на опитен администратор да оцени състоянието на системата и да предприеме коригиращи действия въз основа на случилото се.