Това е част 2 от тази поредица от блогове. Можете да прочетете част 1, тук: Дигиталната трансформация е пътуване на данни от ръба до прозрението
Тази поредица от блогове проследява данните за производството, операциите и продажбите за свързан производител на превозни средства, тъй като данните преминават през етапи и трансформации, които обикновено се случват в голяма производствена компания на водещия ръб на съвременните технологии. Първият блог представи фалшива свързана компания за производство на превозни средства, The Electric Car Company (ECC), за да илюстрира пътя на производствените данни през жизнения цикъл на данните. За да постигне това, ECC използва платформата за данни Cloudera (CDP), за да прогнозира събития и да има изглед отгоре надолу върху производствения процес на автомобила в неговите фабрики, разположени по целия свят.
След като завършите стъпката за събиране на данни в предишния блог, следващата стъпка на ECC в жизнения цикъл на данните е обогатяването на данни. ECC ще обогати събраните данни и ще ги направи достъпни за използване при анализ и създаване на модели по-късно в жизнения цикъл на данните. По-долу е целият набор от стъпки в жизнения цикъл на данните и всяка стъпка в жизнения цикъл ще се поддържа от специална публикация в блог (вижте Фиг. 1):
- Събиране на данни – поглъщане на данни и наблюдение на ръба (независимо дали ръбът е индустриални сензори или хора в шоурум на превозни средства)
- Обогатяване на данни – обработка, агрегиране и управление на конвейера на данни за подготовка на данните за по-нататъшен анализ
- Отчитане – предоставяне на бизнес прозрения (анализ на продажбите и прогнозиране, бюджетиране като примери)
- Обслужване – контролиране и управление на основни бизнес операции (дилърски операции, наблюдение на производството)
- Предсказуем анализ – прогнозен анализ, базиран на AI и машинно обучение (предсказуема поддръжка, оптимизация на инвентара въз основа на търсенето като примери)
- Сигурност и управление – интегриран набор от технологии за сигурност, управление и управление през целия жизнен цикъл на данните

Фиг. 1 Жизненият цикъл на корпоративните данни
Предизвикателство за обогатяване на данни
ECC се нуждае от изчерпателен поглед и задълбочено разбиране на всички данни, свързани с производството, операциите на дилъра и доставката на техните превозни средства. Те също така ще трябва бързо да идентифицират проблеми с данните, като оперативни сензори, които предават данни, които могат да включват фалшиви температурни скокове, причинени от непланирани спирания на машината или внезапни стартирания. Данни, които нямат връзка с процеса, когато работниците по поддръжката премахват сензор от резервоар за потапяне на киселина, докато извършват рутинни проверки, например, не трябва да се вземат предвид при анализа.
Освен това, ECC е изправена пред следните предизвикателства, свързани с данните, които трябва да бъдат разгледани, за да се придвижи успешно производството на двигатели през неговата верига за доставки. Тези предизвикателства с данни включват следното:
- Извличане на данни в различни формати от различни източници: Конвейерите за инженеринг на данни изискват данни да бъдат въведени от различни източници и в много различни формати. Независимо дали данните се получават от сензори, разположени на производствената линия, поддържащи производствени операции, или ERP данни, контролиращи веригата за доставки, всички те трябва да бъдат събрани за по-нататъшен анализ.
- Филтриране на излишни или неподходящи данни: Премахването на дублиращи се или невалидни данни и гарантирането на точността на останалите данни е ключова стъпка в подготовката на данните за по-нататъшна употреба в усъвършенстван прогнозен анализ.
- Възможност за идентифициране на неефективни процеси: ECC изисква способността да се види кои процеси с данни отнемат най-много време и ресурси, което улеснява насочването към неефективни части от тръбопровода, за да се ускори цялостният процес.
- Възможност за наблюдение на всички процеси от един панел: ECC изисква централизирана система, която им позволява да наблюдават всички текущи процеси на данни, както и начин за разширяване на текущата си инфраструктура, като същевременно поддържат прозрачност.
Курирани, качествени набори от данни са гръбнакът на всяка инициатива за напреднали анализи. За да се постигне това, трябва да се използва рамка за инженеринг на данни, за да се позволи изграждането на всички тръбопроводи и водопроводи, необходими за придвижване, манипулиране и управление на данни на различните части на превозното средство в жизнения цикъл на данните.
Изграждане на тръбопровод с помощта на Cloudera Data Engineering
Преди данните да бъдат обогатени и обсъдени в първия блог, потоците от ИТ и ОТ данни, събрани от фабриката, ще бъдат почистени, манипулирани и модифицирани. Фабричен идентификатор, идентификатор на машината, времеви печат, номер на част и сериен номер могат да бъдат заснети от QR-код, отпечатан върху електрическия мотор. Когато двигателят се сглобява в свързаното превозно средство, се улавят данни като тип модел, VIN и базова цена на превозното средство.
След като превозното средство бъде продадено, информацията за продажбите като име на клиента, информация за контакт, крайна продажна цена и местоположение на клиента се записват отделно. Тези данни ще бъдат от решаващо значение за свързване с клиента за евентуално изтегляне или целенасочена превантивна поддръжка. Данните за геолокация също се съхраняват, което ще помогне да се картографират местоположенията на клиентите спрямо географските ширини и дължини, за да се разбере по-добре къде се намират тези двигатели, след като са били продадени в превозно средство.
ECC ще използва Cloudera Data Engineering (CDE) за справяне с горните предизвикателства с данните (виж Фиг. 2). След това CDE ще предостави данните на Cloudera Data Warehouse (CDW), където ще бъдат предоставени за разширени анализи и отчети за бизнес разузнаване. Стъпките на CDE са описани по-долу.
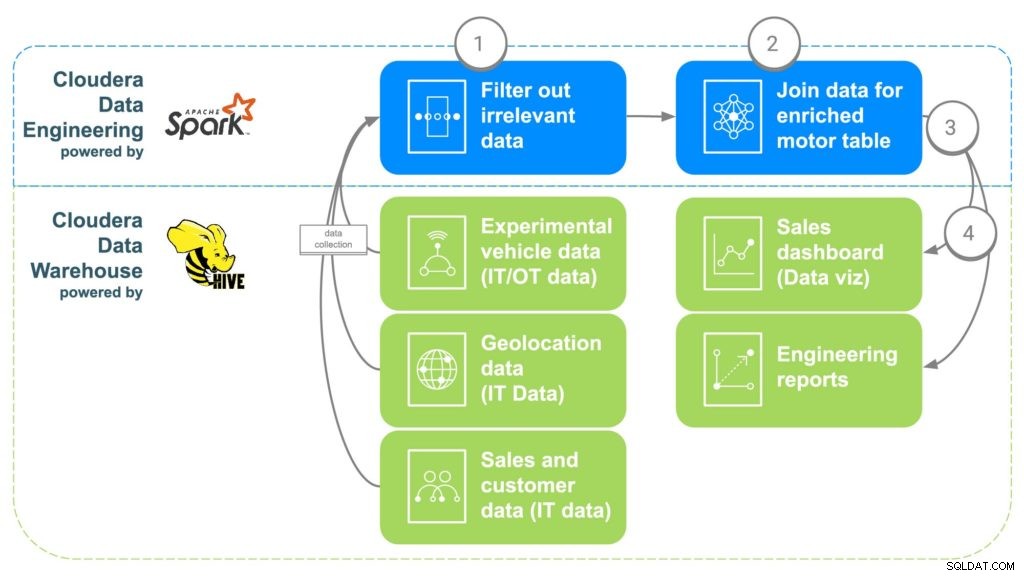
Фиг. 2 ECC конвейер за обогатяване на данни
СТЪПКА 1:Филтрирайте и отделете данните
Първата стъпка в използването на CDE е да се създаде задание на PySpark, което въвежда данните от тези различни „сурови“ източници от стъпка 1. Това е възможност за филтриране на всякакви неподходящи данни, като например клиенти под 16 години, тъй като това обикновено е минималната възраст за шофиране. Дублиращи се данни и други неподходящи данни също могат да бъдат филтрирани или отделени.
СТЪПКА 2:Комбинирайте данните
За да комбинира всички данни, CDE ще съпостави общите връзки заедно. Първо, данните за продажбите на автомобил ще бъдат свързани с клиента, закупил колата, за да се получат метаданните на клиента, като информация за контакт, възраст, заплата и т.н. Данните за геолокация след това ще бъдат използвани за получаване на по-точна информация за местоположението на клиента , което ще помогне за картографирането на двигателите по-късно. Данните за инсталиране на част ще бъдат използвани за идентифициране на серийните номера за всеки двигател, който е бил инсталиран в автомобила на клиента. И накрая, фабричните данни ще бъдат подравнени, за да съответстват на серийния номер на двигателя, който ще идентифицира коя фабрика, машина и кога е създаден всеки конкретен двигател.
СТЪПКА 3:Изпратете данни до Cloudera Data Warehouse
След като всички данни бъдат събрани в обогатена таблица, проста команда на Apache Spark ще запише данните в нова таблица в Cloudera Data Warehouse. Това ще направи данните достъпни за всички специалисти по данни, които биха искали да получат достъп до тях, за да направят допълнителен анализ.
СТЪПКА 4:Генерирайте табла и отчети за визуализация на данни
С всички данни на едно място, вече могат да се създават отчети, които ще позволят на служителите да вземат по-добре информирани решения и да отворят възможности, които не са съществували. Могат да бъдат направени топлинни карти за проследяване на местоположението на двигателя и корелация на проблеми с потенциални географски местоположения, като например повреда поради силен студ или топлина. Тези данни могат да се използват и за проследяване точно какви клиенти могат да бъдат засегнати, ако има проблем в определена фабрика за определен период от време, което улеснява проследяването на клиенти, които може да се нуждаят от изтегляне или превантивна поддръжка.
Заключение
Cloudera Data Engineering позволява на ECC да изгради тръбопровод, който може да съпостави производствените данни и данните за части, вида на употреба от клиента, условията на околната среда, информацията за продажбите и други, за да подобри удовлетвореността на клиентите и надеждността на превозното средство. ECC постигна целите си и се справи с техните предизвикателства, като проследи данните, свързани с производството на неговите двигатели, и се възползва по следните начини:
- ECC ускори времето за оценяване чрез организиране и автоматизиране на тръбопроводи от данни за предоставяне на подбрани, качествени набори от данни сигурно и прозрачно от различни източници на данни.
- ECC успя да идентифицира подходящи данни и да филтрира всички излишни и дублиращи се данни.
- ECC успя да постигне мониторинг на тръбопровода от данни от един панел, като същевременно беше в състояние да бъде предупреден за ранно откриване на проблеми чрез визуално отстраняване на неизправности за бързо разрешаване на проблемите, преди бизнесът да бъде засегнат.
Потърсете следващия блог, който ще се задълбочи в Reporting, който ще покаже как инженерите на ECC изпълняват ad-hoc заявки в CDW срещу тези курирани данни, както и ще присъединят данните към други подходящи източници в хранилище за корпоративни данни. CDW улеснява обединяването на всички данни и предоставя вграден инструмент за визуализация на данни за преминаване от заявени резултати към табла за управление. Очаквайте следващия!
Още ресурси за събиране на данни
За да видите всичко това в действие, моля, кликнете върху свързаните връзки по-долу, за да научите повече за обогатяване на данни:
- Видео – Ако искате да видите и чуете как е построено, вижте видеоклипа на връзката.
- Уроци – Ако искате да правите това със свое собствено темпо, вижте подробно ръководство с екранни снимки и инструкции ред по ред за това как да настроите и изпълните това.
- Среща – Ако искате да говорите директно с експерти от Cloudera, моля, присъединете се към виртуална среща, за да видите презентация на живо. В края ще има време за директни въпроси и отговори.
- Потребители – За да видите повече техническо съдържание, специфично за потребителите, щракнете върху връзката.



