ClusterControl 1.7.1 въведе нова функция, която ви позволява да архивирате вашия ClusterControl сървър и да го възстановите (заедно с метаданните за вашите управлявани бази данни) на друг сървър. Той архивира приложението ClusterControl, както и всички негови конфигурационни данни. Мигрирането на ClusterControl към нов сървър беше мъка, но вече не.
Тази публикация в блога ви превежда през тази нова функция.
Ще мигрираме ClusterControl от един сървър на друг, като запазим всички конфигурации и настройки.
Ще ви покажем също как да прехвърлите управлението на клъстер от един екземпляр на ClusterControl към друг.
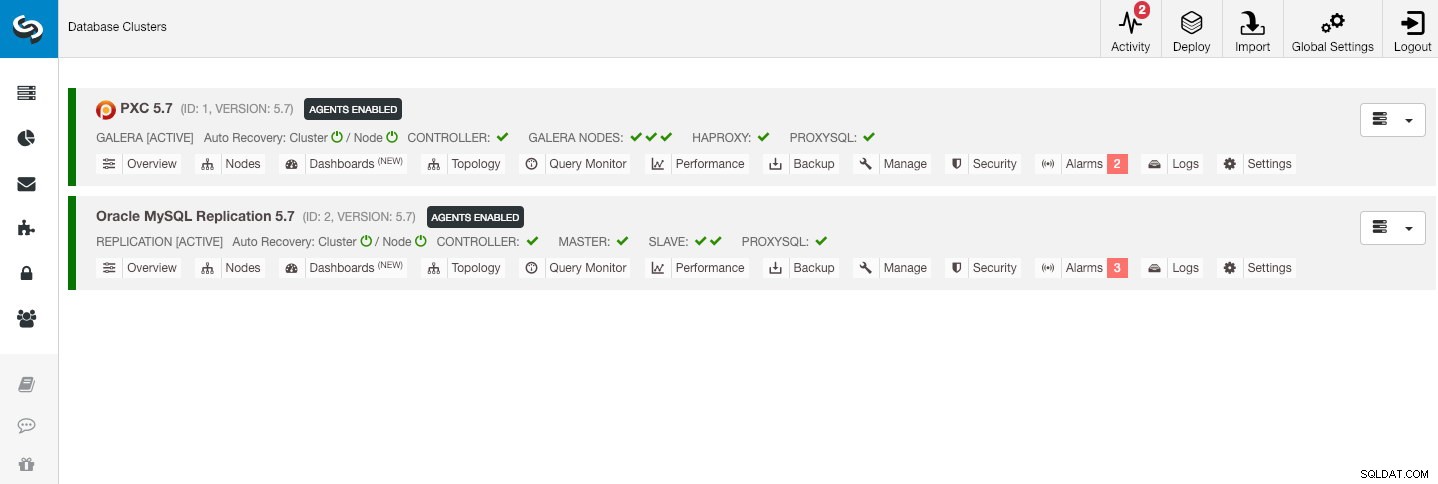
Нашата примерна архитектура започна с два производствени клъстера (показани на екранната снимка по-долу):
- Идентификатор на клъстер 1:3 възела Galera (PXC) + 1 HAProxy + 1 ProxySQL (5 възела)
- Идентификатор на клъстер 2:1 главен MySQL + 2 подчинени MySQL + 1 ProxySQL (4 възела)
Въведение
ClusterControl CLI (s9s) е инструмент за интерфейс на командния ред за взаимодействие, управление и управление на клъстери на база данни с помощта на платформата ClusterControl. Започвайки от версия 1.4.1, скриптът за инсталиране автоматично ще инсталира този пакет на възела ClusterControl.
Има основно 4 нови опции, въведени под командата "s9s backup", които могат да се използват за постигане на нашата цел:
| Флаг | Описание |
|---|---|
| --save-controller | Записва състоянието на контролера в tarball. |
| --restore-controller | Възстановява целия контролер от предварително създаден tarball (създаден с помощта на --save-controller |
| --save-cluster-info | Запазва информацията, която контролерът има за един клъстер. |
| --restore-cluster-info | Възстановява информацията, която контролерът има за клъстер от предварително създаден архивен файл. |
Тази публикация в блога ще обхване примерни случаи на употреба за това как да използвате тези опции. В момента те са в етап кандидат за пускане и са достъпни само чрез ClusterControl CLI инструмента.
Архивиране на ClusterControl
За да направите това, сървърът ClusterControl трябва да е поне на v1.7.1 и по-нова версия. За да архивирате контролера ClusterControl, просто изпълнете следната команда на възела ClusterControl като root потребител (или със sudo):
$ s9s backup \
--save-controller \
--backup-directory=$HOME/ccbackup \
--output-file=controller.tar.gz \
--log--output-file трябва да бъде име на файл или физически път (ако искате да пропуснете флага --backup-directory) и файлът не трябва да съществува предварително. ClusterControl няма да замени изходния файл, ако той вече съществува. Като посочи --log, той ще изчака, докато заданието се изпълни и дневниците на заданията ще бъдат показани в терминала. Същите регистрационни файлове могат да бъдат достъпни чрез потребителския интерфейс на ClusterControl под Дейност -> Работа -> Запазване на контролера :
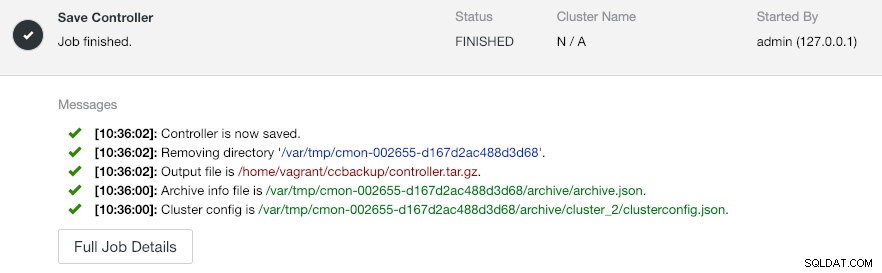
Заданието 'Save Controller' основно изпълнява следните процедури:
- Извлечете конфигурацията на контролера и я експортирайте в JSON
- Експортиране на база данни CMON като файл за дъмп на MySQL
- За всеки клъстер от база данни:
- Извлечете конфигурацията на клъстера и я експортирайте в JSON
В изхода може да забележите, че намерената работа е N + 1 клъстер, например „Намерени са 3 клъстера(а) за запазване“, въпреки че имаме само два клъстера от база данни. Това включва идентификатор на клъстер 0, който има специално значение в ClusterControl като глобален инициализиран клъстер. Той обаче не принадлежи към компонента CmonCluster, който е клъстерът на базата данни под управлението на ClusterControl.
Възстановяване на ClusterControl на нов ClusterControl сървър
Предполагаем, че ClusterControl вече е инсталиран на новия сървър, бихме искали да мигрираме клъстерите на базата данни, за да бъдат управлявани от новия сървър. Следната диаграма илюстрира нашето упражнение по миграция:
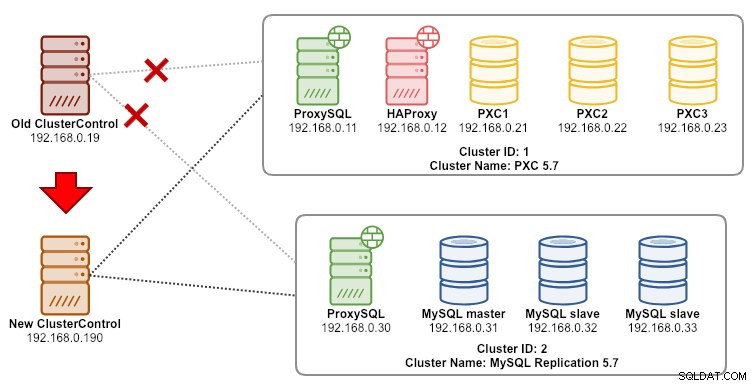
Първо, прехвърлете архива от стария сървър на новия сървър:
$ scp $HOME/ccbackup/controller.tar.gz 192.168.0.190:~Преди да извършим възстановяването, трябва да настроим SSH без парола към всички възли от новия сървър ClusterControl:
$ ssh-copy-id 192.168.0.11 #proxysql cluster 1
$ ssh-copy-id 192.168.0.12 #proxysql cluster 1
$ ssh-copy-id 192.168.0.21 #pxc cluster 1
$ ssh-copy-id 192.168.0.22 #pxc cluster 1
$ ssh-copy-id 192.168.0.23 #pxc cluster 1
$ ssh-copy-id 192.168.0.30 #proxysql cluster 2
$ ssh-copy-id 192.168.0.31 #mysql cluster 2
$ ssh-copy-id 192.168.0.32 #mysql cluster 2
$ ssh-copy-id 192.168.0.33 #mysql cluster 2След това на новия сървър извършете възстановяването:
$ s9s backup \
--restore-controller \
--input-file=$HOME/controller.tar.gz \
--debug \
--logСлед това трябва да синхронизираме клъстера в потребителския интерфейс, като отидем на Глобални настройки -> Регистрации на клъстери -> Синхронизиране на клъстер . След това, ако се върнете към главното табло за управление на ClusterControl, ще видите следното:
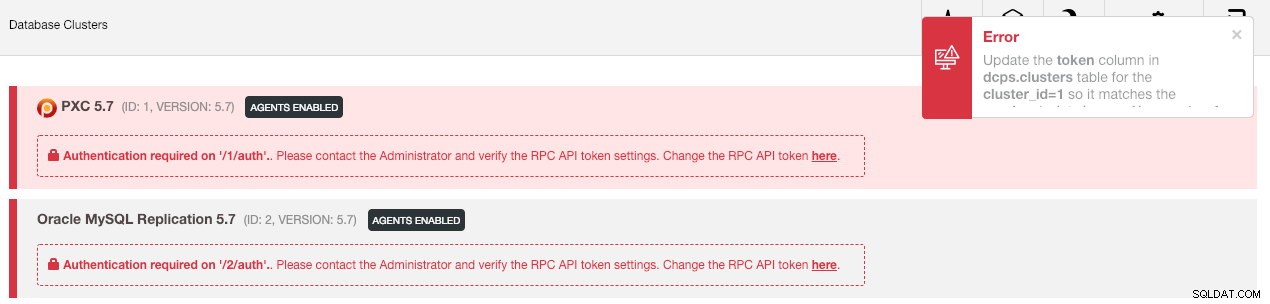
Не изпадайте в паника. Новият потребителски интерфейс на ClusterControl не може да извлече данните за наблюдение и управление поради неправилен RPC API маркер. Просто трябва да го актуализираме съответно. Първо, извлечете стойността на rpc_key за съответните клъстери:
$ cat /etc/cmon.d/cmon_*.cnf | egrep 'cluster_id|rpc_key'
cluster_id=1
rpc_key=8fgkzdW8gAm2pL4L
cluster_id=2
rpc_key=tAnvKME53N1n8vCCВ потребителския интерфейс щракнете върху връзката „тук“ в края на реда „Промяна на токена на RPC API тук“. Ще се появи следният диалогов прозорец:
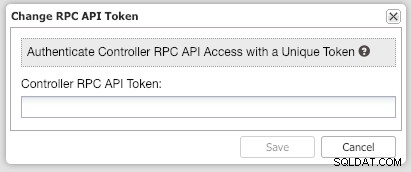
Поставете съответната стойност rpc_key в текстовото поле и щракнете върху Запиши. Повторете за следващия клъстер. Изчакайте малко и списъкът с клъстери трябва да се обнови автоматично.
Последната стъпка е да коригирате потребителските привилегии на MySQL cmon за новите промени в IP адреса на ClusterControl, 192.168.0.190. Влезте в един от PXC възела и изпълнете следното:
$ mysql -uroot -p -e 'GRANT ALL PRIVILEGES ON *.* TO example@sqldat.com"192.168.0.190" IDENTIFIED BY "<password>" WITH GRANT OPTION';
** Заменете
След като привилегията е настроена, трябва да видите списъка с клъстери в зелено, подобно на стария:
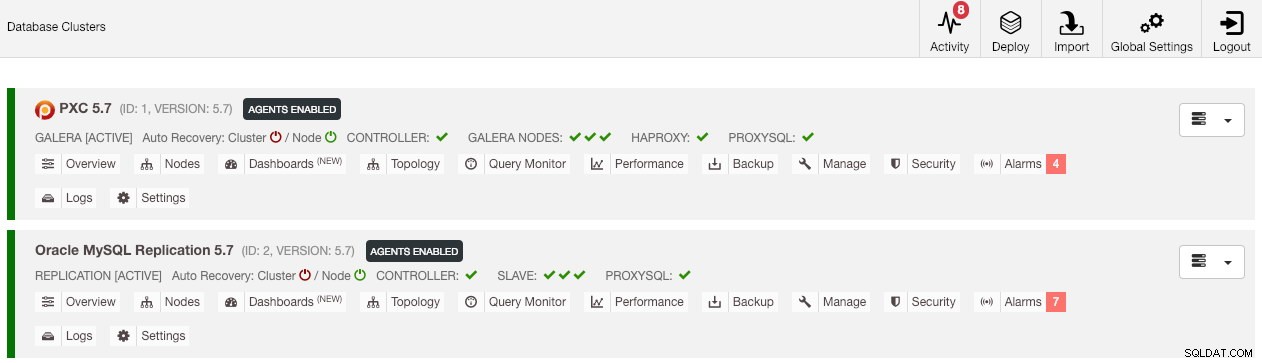
Струва си да се спомене, че по подразбиране ClusterControl ще деактивира автоматичното възстановяване на клъстера (както можете да видите червената икона до думата „Клъстер“), за да избегне състояние на състезание с друг екземпляр на ClusterControl. Препоръчително е да активирате тази функция (като щракнете върху иконата до зелена), след като старият сървър бъде изведен от експлоатация.
Нашата миграция е завършена. Всички конфигурации и настройки от стария сървър се запазват и се прехвърлят на новия сървър.
Мигриране на управлението на клъстер към друг ClusterControl сървър
Архивиране на информация за клъстера
Става дума за архивиране на метаданни и информация на клъстера, за да можем да ги прехвърлим на друг сървър на ClusterControl, известен също като частично архивиране. В противен случай трябва да извършим „Импортиране на съществуващ сървър/клъстер“, за да ги импортираме отново в новия ClusterControl, което означава, че ще загубите данните за наблюдение от стария сървър. Ако имате балансьори на натоварване или асинхронни подчинени екземпляри, това ще трябва да бъде импортирано, след като клъстерът бъде импортиран, един възел в даден момент. Така че е малко неприятно, ако имате пълен набор от производствени настройки.
Упражнението за миграция на клъстер „мениджър“ е илюстрирано на следната диаграма:
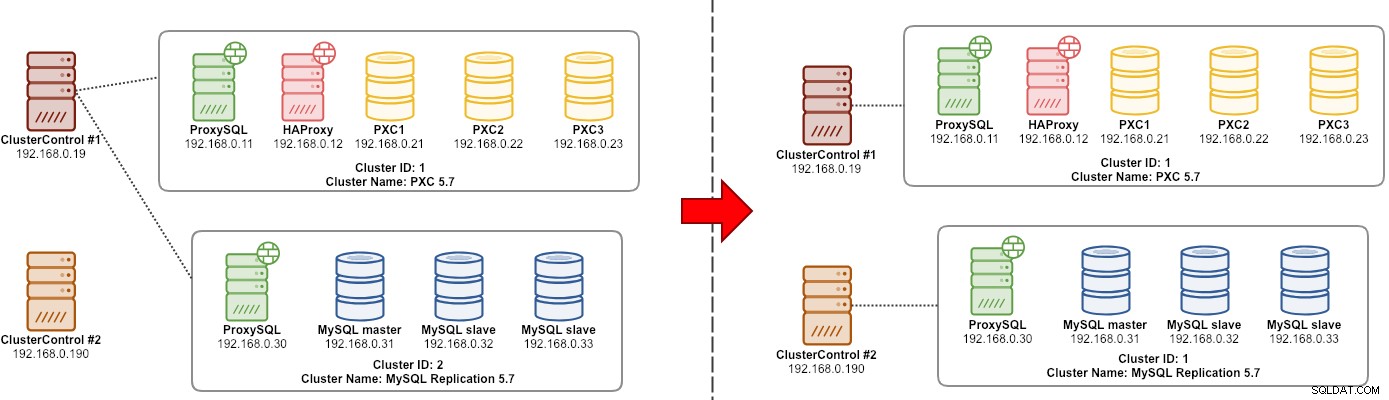
По принцип искаме да мигрираме нашата MySQL репликация (идентификатор на клъстер:2), за да бъде управлявана от друг екземпляр на ClusterControl. Ще използваме опции --save-cluster-info и --restore-cluster-info за това. Опцията --save-cluster-info ще експортира съответната информация за клъстера, за да бъде запазена някъде другаде. Нека експортираме нашия MySQL репликационен клъстер (идентификатор на клъстера:2). На текущия сървър ClusterControl направете:
$ s9s backup \
--save-cluster-info \
--cluster-id=2 \
--backup-directory=$HOME/ccbackup \
--output-file=cc-replication-2.tar.gz \
--logЩе видите куп нови редове, отпечатани в терминала, което показва, че заданието за архивиране се изпълнява (изходът е достъпен и чрез ClusterControl -> Activity -> Jobs ):
Ако погледнете отблизо регистрите на заданията, ще забележите, че заданието се опитва да експортира цялата свързана информация и метаданни за идентификатор на клъстер 2. Резултатът се съхранява като компресиран файл и се намира под път, който сме посочили с помощта на --backup - флаг на директория. Ако този флаг се игнорира, ClusterControl ще запише изхода в директорията за архивиране по подразбиране, която е домашната директория на SSH потребителя, под $HOME/backups.
Възстановяване на информация за клъстера
Стъпките, обяснени тук, са подобни със стъпките за възстановяване за пълно архивиране на ClusterControl. Прехвърлете архива от текущия сървър към другия сървър на ClusterControl:
$ scp $HOME/ccbackup/cc-replication-2.tar.gz 192.168.0.190:~Преди да извършим възстановяването, трябва да настроим SSH без парола към всички възли от новия сървър ClusterControl:
$ ssh-copy-id 192.168.0.30 #proxysql cluster 2
$ ssh-copy-id 192.168.0.31 #mysql cluster 2
$ ssh-copy-id 192.168.0.32 #mysql cluster 2
$ ssh-copy-id 192.168.0.33 #mysql cluster 2
$ ssh-copy-id 192.168.0.19 #prometheus cluster 2След това на новия сървър извършете възстановяването на информация за клъстера за нашата MySQL репликация:
$ s9s backup \
--restore-cluster-info \
--input-file=$HOME/cc-replication-2.tar.gz \
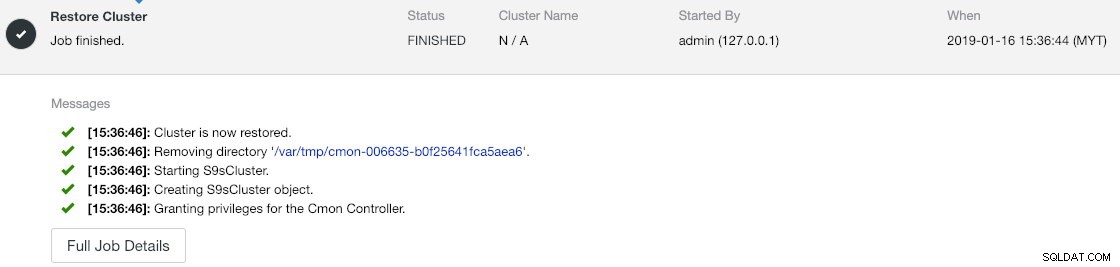
--logМожете да проверите напредъка в Дейност -> Задачи -> Възстановяване на клъстер :
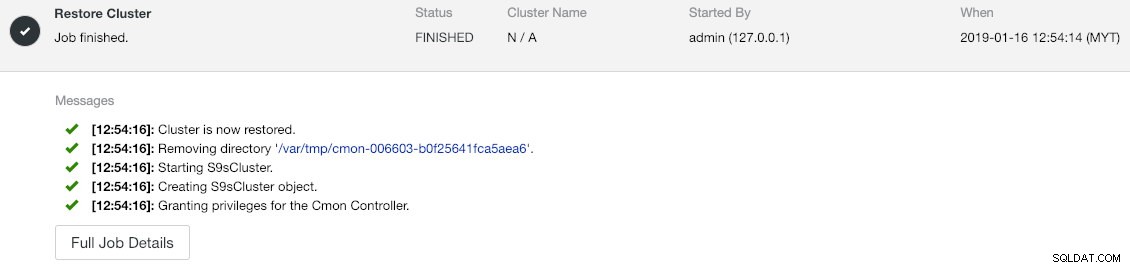
Ако погледнете внимателно съобщенията за задание, можете да видите, че ClusterControl автоматично преназначава идентификатор на клъстер на 1 на този нов екземпляр (той беше идентификатор на клъстер 2 на стария екземпляр).
След това синхронизирайте клъстера в потребителския интерфейс, като отидете на Глобални настройки -> Регистрации на клъстери -> Синхронизиране на клъстер . Ако се върнете към главното табло за управление на ClusterControl, ще видите следното:

Грешката означава, че новият потребителски интерфейс на ClusterControl не може да извлече данните за наблюдение и управление поради неправилен RPC API маркер. Просто трябва да го актуализираме съответно. Първо, извлечете стойността на rpc_key за нашия клъстер ID 1:
$ cat /etc/cmon.d/cmon_1.cnf | egrep 'cluster_id|rpc_key'
cluster_id=1
rpc_key=tAnvKME53N1n8vCCВ потребителския интерфейс щракнете върху връзката „тук“ в края на реда „Промяна на токена на RPC API тук“. Ще се появи следният диалогов прозорец:
Поставете съответната стойност rpc_key в текстовото поле и щракнете върху Запиши. Изчакайте малко и списъкът с клъстери трябва да се обнови автоматично.
Последната стъпка е да коригирате потребителските привилегии на MySQL cmon за новите промени в IP адреса на ClusterControl, 192.168.0.190. Влезте в главния възел (192.168.0.31) и изпълнете следното изявление:
$ mysql -uroot -p -e 'GRANT ALL PRIVILEGES ON *.* TO example@sqldat.com"192.168.0.190" IDENTIFIED BY "<password>" WITH GRANT OPTION';
** Заменете
Можете също да отмените старите потребителски привилегии (revoke няма да изтрие потребителя) или просто да премахнете стария потребител:
$ mysql -uroot -p -e 'DROP USER example@sqldat.com"192.168.0.19"'След като привилегията е настроена, трябва да видите, че всичко е зелено:

В този момент нашата архитектура изглежда така:
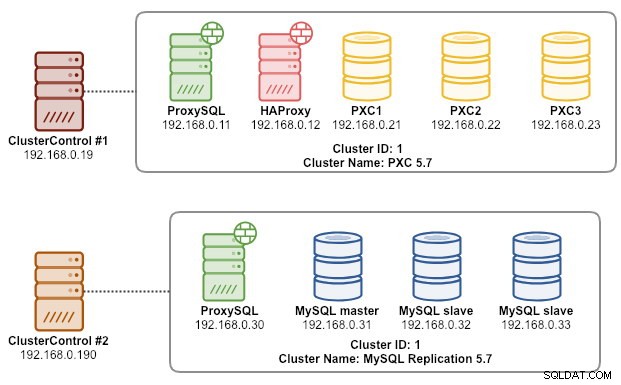
Упражнението ни по миграция вече е завършено.
Последни мисли
Вече е възможно да извършвате пълно и частично архивиране на вашите екземпляри на ClusterControl и клъстерите, които те управляват, което ви позволява да ги премествате свободно между хостове с малко усилия. Предложенията и отзивите са добре дошли.



