В предишния ни Hadoop блогове проучихме всекикомпонент на Hadoop MapReduce процес в детайли. В това ще обсъдим много интересната тема, т.е. работа само за карти в Hadoop.
Първо, ще направим кратко въведение на Картата и Намаляване фаза в Hadoop Mapreduce, след което ще обсъдим какво е задача само за карта в Hadoop MapReduce.
Най-накрая ще обсъдим и предимствата и недостатъците на работата само с Hadoop Map в този урок.
Какво е Hadoop Map Only Job?
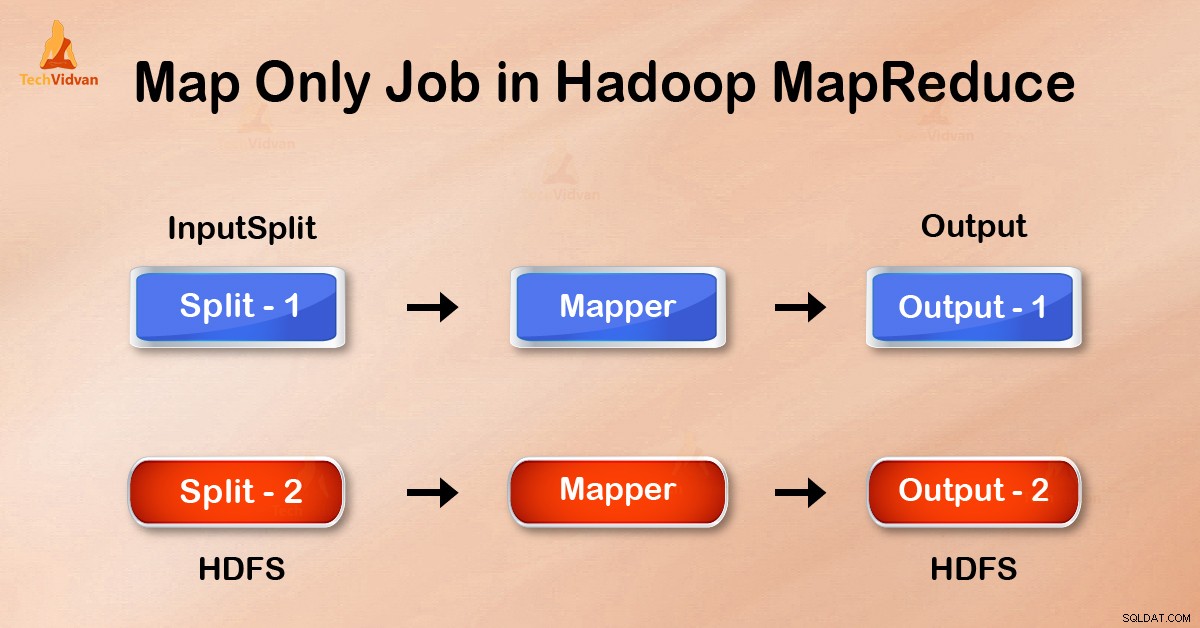
Задание само за карта в Hadoop е процесът, в койтоmapper изпълнява всички задачи. Нито една задача не се изпълнява отредуктора . Резултатът на Mapper е крайният изход.
MapReduce е слой за обработка на данни на Hadoop. Той обработва големи структурирани и неструктурирани данни, съхранявани в HDFS . MapReduce също обработва огромно количество данни паралелно.
Той прави това чрез разделяне на заданието (подадено задание) на набор от независими задачи (подзадача). В Hadoop MapReduce работи, като разделя обработката на фази:Карта и Намаляване .
- Карта: Това е първата фаза на обработка, където ние определяме целия сложен логически код. Той взема набор от данни и се преобразува в друг набор от данни. Той разделя всеки отделен елемент на кортежи (двойки ключ-стойност ).
- Намаляване: Това е втората фаза на обработка. Тук ние определяме лека обработка като агрегиране/сумиране. Той приема изхода от картата като вход. След това комбинира тези кортежи въз основа на ключа.
От този пример за броене на думи можем да кажем, че има два набора от паралелни процеси, карта и намаляване. В процеса на картографиране първият вход се разделя, за да се разпредели работата между всички възли на картата, както е показано по-горе.
След това рамката идентифицира всяка дума и съпоставя с числото 1. Така тя създава двойки, наречени двойки кортежи (ключ-стойност).
В първия възел за картографиране той предава три думи лъв, тигър и река. По този начин той произвежда 3 двойки ключ-стойност като изход на възела. Три различни ключа и стойност са зададени на 1 и същият процес се повтаря за всички възли.
След това предава тези кортежи на редукционните възли. Разпределителят извършваразместване така че всички кортежи с един и същи ключ отиват към един и същ възел.
В процеса на намаляване това, което основно се случва, е агрегиране на стойности или по-скоро операция върху стойности, които споделят един и същ ключ.
Сега нека разгледаме сценарий, при който просто трябва да извършим операцията. Нямаме нужда от агрегиране, в такъв случай ще предпочетем „Работа само за карта “.
При работа само за карта картата изпълнява всички задачи със своя InputSplit . Редукторът не върши работа. Изходът на Mappers е крайният изход.
Как да избегнем Reduce Phase в MapReduce?
Като зададете job.setNumreduceTasks(0) в конфигурацията в драйвер можем да избегнем намаляване на фазата. Това ще направи редуктор като 0 . Така единственият картограф ще изпълнява цялата задача.
Предимства на работата само за карти в Hadoop
В изпълнението на заданието MapReduce между фазите на картата и намаляването има фаза на ключ, сортиране и разбъркване. Разбъркване – сортиране отговарят за сортирането на ключовете във възходящ ред. След това групиране на стойности въз основа на същите ключове. Тази фаза е много скъпа.
Ако фазата на намаляване не е необходима, трябва да я избягваме. Тъй като избягването на фазата на намаляване би елиминирало и фазата на сортиране и разбъркване. Следователно това също ще спести претоварване на мрежата.
Причината е, че при разбъркване изходът на картографа пътува за намаляване. И когато размерът на данните е огромен, големи данни трябва да пътуват до редуктор.
Резултатът от картографа се записва на локалния диск, преди да бъде изпратен за намаляване. Но в задача само за карта този изход се записва директно в HDFS. Това допълнително спестява време, както и намалява разходите.
Заключение
Следователно, ние видяхме, че работата само за карта намалява претоварването на мрежата, като избягва фазата на разбъркване, сортиране и намаляване. Картата сама се грижи за цялостната обработка и произвежда изхода. С помощта на job.setNumreduceTasks(0) това се постига.
Надявам се, че сте разбрали задачата само за карта на Hadoop и тя е важна, защото сме обхванали всичко за работата само за карта в Hadoop. Но ако имате някакви запитвания, можете да споделите с нас в секцията за коментари.



