Разгледайте архитектурата на Hadoop, която е най-приетата рамка за съхранение и обработка на масивни данни.
В тази статия ще изучаваме архитектурата на Hadoop. Статията обяснява архитектурата на Hadoop и компонентите на архитектурата на Hadoop, които са HDFS, MapReduce и YARN. В статията ще разгледаме подробно архитектурата на Hadoop, заедно с диаграмата на архитектурата на Hadoop.
Нека сега започнем с Hadoop Architecture.
Архитектура на Hadoop
Целта на проектирането на Hadoop е да се разработи евтина, надеждна и мащабируема рамка, която съхранява и анализира нарастващите големи данни.
Apache Hadoop е софтуерна рамка, проектирана от Apache Software Foundation за съхранение и обработка на големи набори от данни с различни размери и формати.
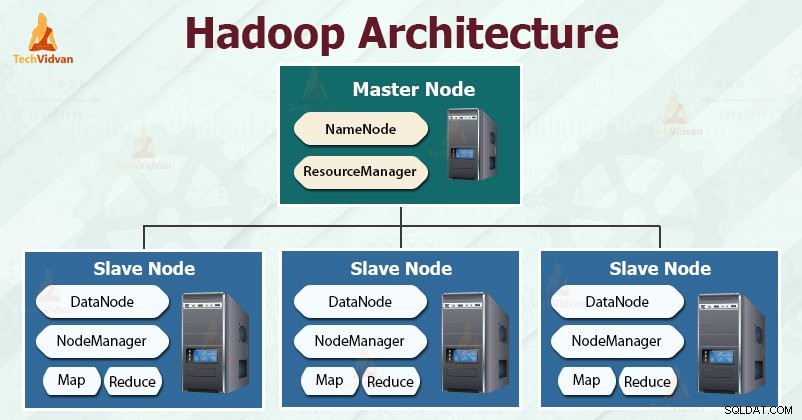
Hadoop следва главен роб архитектура за ефективно съхранение и обработка на огромни количества данни. Главните възли възлагат задачи на подчинените възли.
Подчинените възли са отговорни за съхраняването на действителните данни и извършването на действителното изчисление/обработка. Главните възли са отговорни за съхраняването на метаданните и управлението на ресурсите в клъстера.
Подчинените възли съхраняват действителните бизнес данни, докато главните съхраняват метаданните.
Архитектурата на Hadoop се състои от три слоя. Те са:
- Слой за съхранение (HDFS)
- Слой за управление на ресурси (YARN)
- Слой за обработка (MapReduce)
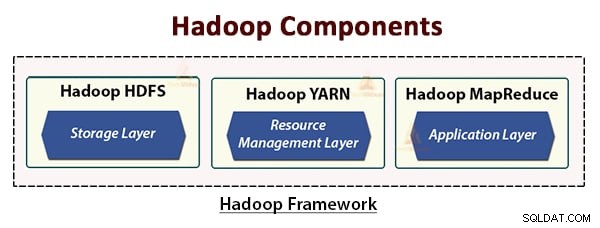
HDFS, YARN и MapReduce са основните компоненти на Hadoop Framework.
Нека сега да проучим тези три основни компонента в подробности.
1. HDFS
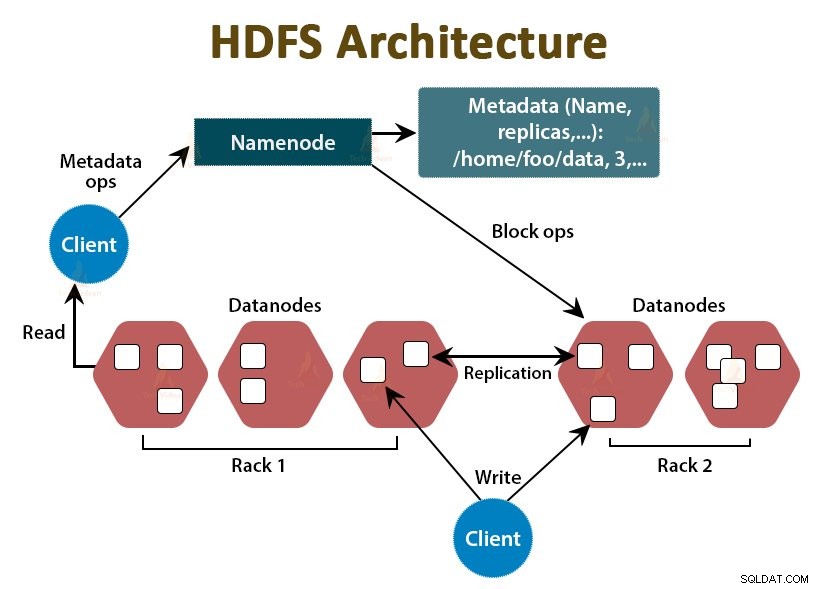
HDFS е разпределената файлова система на Hadoop , който работи с евтин стоков хардуер. Това е слоят за съхранение на Hadoop. Файловете в HDFS са разбити на блокове с размери, наречени блокове данни.
След това тези блокове се съхраняват на подчинените възли в клъстера. Размерът на блока е 128 MB по подразбиране, който можем да конфигурираме според нашите изисквания.
Подобно на Hadoop, HDFS също следва архитектурата master-slave. Състои се от два демона - NameNode и DataNode. NameNode е главният демон, който работи на главния възел. DataNodes са подчинения демон, който работи на подчинените възли.
NameNode
NameNode съхранява метаданните на файловата система, т.е. имена на файлове, информация за блокове на файл, блокирани местоположения, разрешения и т.н. Той управлява Datanodes.
DataNode
DataNodes са подчинените възли, които съхраняват действителните бизнес данни. Той обслужва заявки за четене/запис на клиента въз основа на инструкциите на NameNode.
DataNodes съхранява блоковете на файловете, а NameNode съхранява метаданните като местоположение на блокове, разрешение и т.н.
2. MapReduce
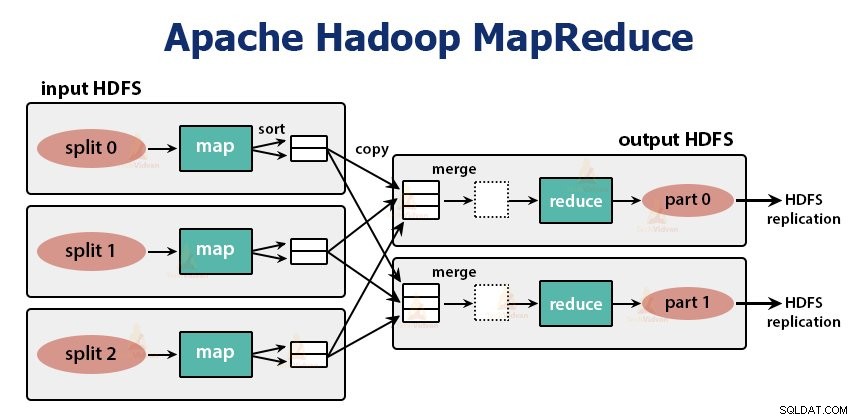
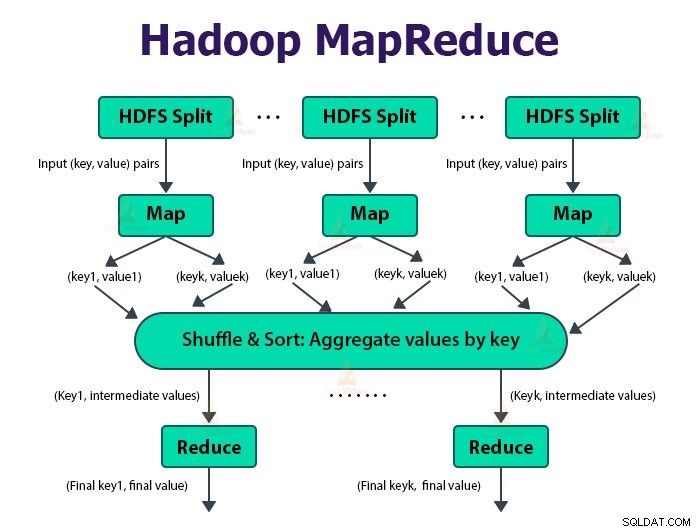
Това е слой за обработка на данни на Hadoop. Това е софтуерна рамка за писане на приложения, които обработват огромни количества данни (терабайти до петабайти в обхват) успоредно на клъстера от обикновен хардуер.
Рамката MapReduce работи върху двойките
Задачата MapReduce е единицата работа, която клиентът иска да изпълни. Задачата MapReduce се състои основно от входните данни, програмата MapReduce и информацията за конфигурацията. Hadoop изпълнява заданията MapReduce, като ги разделя на два типа задачи, които са задачи на карта инамаляване на задачите . Hadoop YARN планира тези задачи и се изпълняват на възлите в клъстера.
Поради някои неблагоприятни условия, ако задачите се провалят, те автоматично ще бъдат пренасрочени на друг възел.
Потребителят дефинира функцията карта и функцията занамаляване за изпълнение на заданието MapReduce.
Входът към функцията map и изходът от функцията за намаляване е двойката ключ, стойност.
Функцията на картографските задачи е да зареждат, анализират, филтрират и трансформират данните. Резултатът от задачата за карта е входът към задачата за намаляване. Задачата Reduce след това извършва групиране и агрегиране на изхода от задачата за карта.
Задачата MapReduce се извършва на две фази-
1. Фаза на карта
а. RecordReader
Hadoop разделя входните данни за заданието MapReduce на разделяния с фиксиран размер, наречени входни разделения или се разделя. RecordReader трансформира тези разделяния в записи и анализира данните в записи, но не анализира самите записи. RecordReader предоставя данните на функцията за картографиране в двойки ключ-стойност.
б. Картата
Във фазата на картата Hadoop създава една задача за карта, която изпълнява дефинирана от потребителя функция, наречена функция карта за всеки запис във входното разделяне. Той генерира нула или множество междинни двойки ключ-стойност като изходна задача за картографиране.
Задачата за карта записва изхода си на локалния диск. След това този междинен изход се обработва от задачите за намаляване, които изпълняват дефинирана от потребителя функция за намаляване, за да произведат крайния изход. След като задачата приключи, изходът на картата се изтрива.
в. Комбинатора
Входът към единичната задача за намаляване е изходът от всички Mappers, който се извежда от всички задачи на картата. Hadoop позволява на потребителя да дефинира функция за комбиниране, която се изпълнява на изхода на картата.
Комбинатор групира данните във фазата на картата, преди да ги предаде на Reducer. Той комбинира изхода на функцията map, който след това се предава като вход към функцията за намаляване.
г. Разпределитела
Когато има множество редуктори, тогава задачите на картата разделят изхода си, като всеки създава един дял за всяка задача за намаляване. Във всеки дял може да има много ключове и свързани с тях стойности, но записите за всеки даден ключ са всички в един дял.
Hadoop позволява на потребителите да контролират разделянето, като зададат дефинирана от потребителя функция за разделяне. По принцип има разделител по подразбиране, който събира ключовете с помощта на хеш функцията.
2. Намаляване на фазата:
Различните фази в задачата за намаляване са както следва:
а. Сортиране и разбъркване:
Задачата Reducer започва със стъпка за разбъркване и сортиране. Основната цел на тази фаза е да се съберат еквивалентните ключове заедно. Фазата на сортиране и разбъркване изтегля данните, записани от разделителя, към възела, където работи Reducer.
Той сортира всяка част от данни в голям списък с данни. Рамката MapReduce извършва това сортиране и размесва, така че да можем лесно да я повторим в задачата за намаляване.
Сортиране и разместване се изпълняват от рамката автоматично. Разработчикът чрез обекта за сравнение може да има контрол върху това как ключовете се сортират и групират.
б. Намаляване:
Редукторът, който е дефинирана от потребителя функция за намаляване, изпълнява веднъж за групиране на ключове. Редукторът филтрира, обобщава и комбинира данни по няколко различни начина. След като задачата за намаляване е завършена, тя дава нула или повече двойки ключ-стойност на OutputFormat. Изходът на задачата за намаляване се съхранява в Hadoop HDFS.
в. Изходен формат
Той взема изхода на редуктор и го записва в HDFS файла от RecordWriter. По подразбиране той разделя ключа, стойността с табулатор и всеки запис със знак за нов ред.
3. ПРЕЖДА
YARN означава Още друг преговарящ за ресурси . Това е слой за управление на ресурсите на Hadoop. Той беше въведен в Hadoop 2.
YARN е проектиран с идеята за разделяне на функционалностите на планирането на работни места и управлението на ресурсите на отделни демони. Основната идея е да има глобален ResourceManager и главен кадър на приложение за приложение, където приложението може да бъде едно задание или DAG от задачи.
YARN се състои от ResourceManager, NodeManager и ApplicationMaster за всяко приложение.
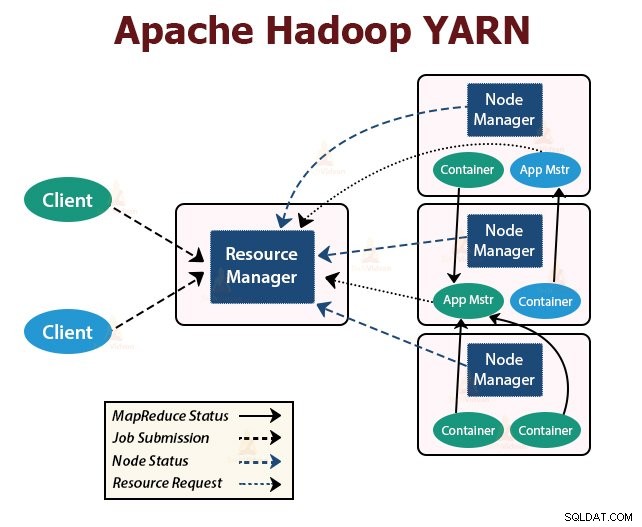
1. Resource Manager
Той арбитрира ресурсите между всички приложения в клъстера.
Той има два основни компонента, които са Scheduler и ApplicationManager.
а. Планировчика
- Пластировчикът разпределя ресурси за различните приложения, работещи в клъстера, като се има предвид капацитета, опашките и т.н.
- Това е чист планировчик. Той не следи и не проследява състоянието на приложението.
- Scheduler не гарантира рестартирането на неуспешните задачи, които са неуспешни поради повреда на приложението или хардуерна повреда.
- Извършва планиране въз основа на ресурсните изисквания на приложенията.
б. Мениджър на приложенията
- Те са отговорни за приемането на заявките за работа.
- ApplicationManager договаря първия контейнер за изпълнение на специфично приложение ApplicationMaster.
- Те предоставят услуга за рестартиране на контейнера ApplicationMaster при неуспех.
- Мастерът на приложението за всяко приложение е отговорен за договарянето на контейнери от Планировчика. Той проследява и следи тяхното състояние и напредък.
2. NodeManager:
NodeManager работи на подчинените възли. Той отговаря за контейнерите, наблюдава използването на ресурсите на машината, което е процесор, памет, диск, използване на мрежата, и отчита същото на ResourceManager или Scheduler.
3. ApplicationMaster:
ApplicationMaster за приложение е специфична за рамка библиотека. Той отговаря за договарянето на ресурси от ResourceManager. Работи с NodeManager(ите) за изпълнение и наблюдение на задачите.
Резюме
В тази статия изучавахме архитектурата на Hadoop. Hadoop следва топологията главен-подчинен. Главните възли възлагат задачи на подчинените възли. Архитектурата се състои от три слоя, които са HDFS, YARN и MapReduce.
HDFS е разпределената файлова система в Hadoop за съхранение на големи данни. MapReduce е рамката за обработка за обработка на огромни данни в клъстера Hadoop по разпределен начин. YARN отговаря за управлението на ресурсите между приложенията в клъстера.
Демонът HDFS NameNode и демонът YARN ResourceManager работят на главния възел в клъстера Hadoop. Демонът на HDFS DataNode и YARN NodeManager работят на подчинените възли.
HDFS и MapReduce рамка работят на един и същи набор от възли, което води до много висока обща честотна лента в клъстера.
Продължавайте да учите!!



