В този урок за Hadoop , ще ви предоставим пълно въведение в двойката стойности на ключове MapReduce.
На първо място ще обсъдим какво е двойка стойности на ключове в Hadoop, как се генерира двойка стойности на ключове в MapReduce. Най-накрая ще обясним генерирането на двойки ключови стойности на MapReduce с примери.
Какво е двойка ключови стойности в Hadoop?
Двойка ключ-стойност в MapReduce е записът, който Hadoop MapReduce приема за изпълнение.
Ние използваме Hadoop основно за анализ на данни. Той се занимава със структурирани, неструктурирани и полуструктурирани данни. С Hadoop, ако схемата е статична, можем директно да работим върху колоната вместо стойност на ключа. Но ако схемата не е статична, ще работим върху ключова стойност.
Стойността на ключовете не е присъщите свойства на данните. Но те се избират, като потребителят анализира данните.
MapReduce е основният компонент на Hadoop, който осигурява обработка на данни. Той извършва обработка, като разделя заданието на две фази:Фаза на карта и Намаляване на фазата . Всяка фаза има ключ-стойност като вход и изход.
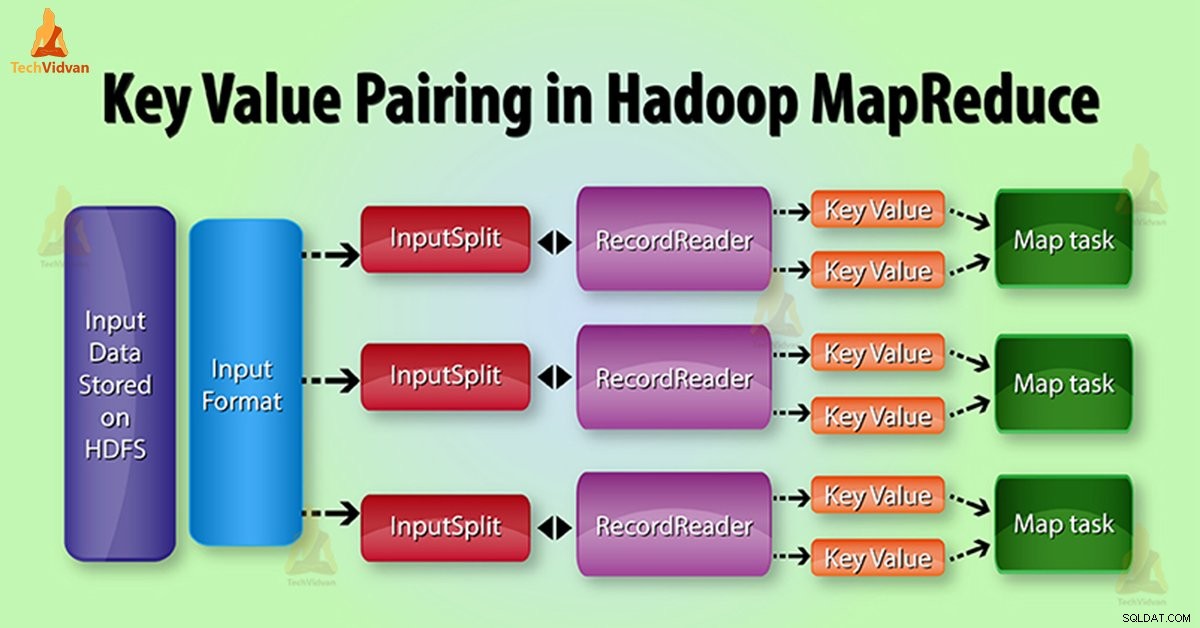
Генериране на двойки стойности на ключ MapReduce в Hadoop
При изпълнение на задание MapReduce, преди изпращане на данни към mapperа , първо го преобразувайте в двойки ключ-стойност. Тъй като картографът само двойки ключ-стойност данни.
Двойка ключ-стойност в MapReduce се генерира по следния начин:
InputSplit – Това е логическото представяне на данни, които InputFormat генерира. В програмата MapReduce той описва единица работа, която съдържа една задача за карта.
RecordReader – Той комуникира с InputSplit. След това преобразува данните в двойки ключови стойности, подходящи за четене от Mapper. RecordReader по подразбиране използва TextInputFormat за преобразуване на данни в двойки ключови стойности.
При изпълнение на задание MapReduce, функцията map обработва определена двойка ключ-стойност. След това излъчва определен брой двойки ключ-стойност. Функцията Reduce обработва стойностите, групирани от същия ключ.
След това излъчва друг набор от двойки ключ-стойност като изход. Изходните типове карта трябва да съвпадат с входните типове на Reduce, както е показано по-долу:
- Карта: (K1, V1) -> списък (K2, V2)
- Намаляване: {(K2, списък (V2}) -> списък (K3, V3)
На каква основа се генерира двойка ключ-стойност в Hadoop?
MapReduce Генерирането на двойки ключ-стойност изцяло зависи от набора от данни. Също така зависи от необходимия изход. Framework определя двойка ключ-стойност на 4 места:Карта вход/изход, Намаляване на вход/изход.
1. Въвеждане на карта
Map Input по подразбиране приема изместването на линията като ключ. Съдържанието на реда е стойност като текст. Можем да ги модифицираме; като използвате персонализирания формат за въвеждане.
2. Изход на карта
Картата е отговорна за филтрирането на данните. Освен това предоставя среда за групиране на данните въз основа на ключ.
- Ключ – Това е поле/текст/обект, върху който данните се групират и агрегират в редуктор .
- Стойност– Това е полето/текстът/обектът, който всеки отделно намалява метода.
3. Намалете въвеждане
Изходът на картата се въвежда за намаляване. Така че е същото като Map-Output.
4. Намаляване на изхода
Напълно зависи от необходимия изход.
Пример за двойка ключ-стойност на MapReduce
Например съдържанието на файла, който HDFS магазините са Чандлър е Джоуи Марк е Джон . И така, сега, използвайки InputFormat, ще дефинираме как този файл ще се раздели и чете. По подразбиране RecordReader използва TextInputFormat, за да преобразува този файл в двойка ключ-стойност.
- Клавиш – Той е изместен от началото на реда във файла.
- Стойност – Това е съдържанието на реда, с изключение на терминаторите на реда.
Тук,Ключ е 0 и Стойност е Чандлър е Джоуи Марк е Джон.
Заключение
В заключение можем да кажем, че ключ-стойност е просто запис, който MapReduce приема за изпълнение. InputSplit и RecordReader генерират двойка ключ-стойност. Следователно, ключът е отместване на байта, а стойността е съдържанието на реда.
Надявам се този блог да ви е харесал. Ако имате някакво предложение или запитване, свързано с двойката ключови стойности MapReduce, моля, оставете коментар в раздел, даден по-долу.



