Основната цел на този Hadoop урок е да ви предостави подробно описание на всеки компонент, който се използва в работата на Hadoop. В този урок ще разгледаме Partitioner в Hadoop.
Какво е Hadoop Partitioner, каква е нуждата от Partitioner в Hadoop, Какъв е разделителя по подразбиране в MapReduce, Колко MapReduce Partitioner се използват в Hadoop?
Ще отговорим на всички тези въпроси в този урок за MapReduce.
Какво е Hadoop Partitioner?
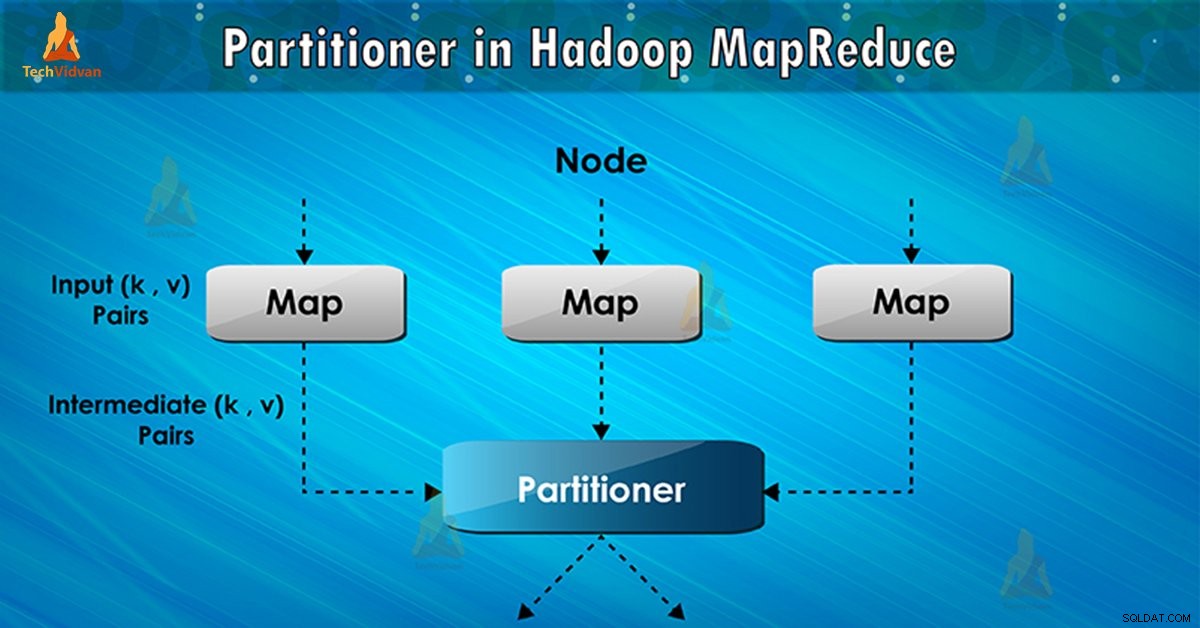
Partitioner в изпълнението на заданието MapReduce контролира разделянето на ключовете на междинните изходи за карта. С помощта на хеш функцията ключът (или подмножество от ключа) извлича дяла. Общият брой дялове е равен на броя на задачите за намаляване.
Въз основа на ключовата стойност , рамкови дялове, всекиmapper изход. Записите, които имат една и съща стойност на ключа, влизат в същия дял (във всеки мапер). След това всеки дял се изпраща вредуктор .
Класът на дял решава кой дял ще отиде дадена двойка (ключ, стойност). Фазата на разделяне в потока от данни MapReduce се извършва след фазата на картата и преди фазата на намаляване.
Необходим е MapReduce Partitioner в Hadoop
При изпълнение на задание MapReduce, той взима набор от входни данни и произвежда списък с двойка ключови стойности. Тази двойка ключ-стойност е резултат от фазата на карта. В който входните данни се разделят и всяка задача обработва разделянето и всяка карта, извежда списък с двойки ключови стойности.
След това рамката изпраща изхода на картата, за да намали задачата. Редуциране на процеси, дефинираната от потребителя функция за намаляване на изходите на картата. Преди фазата на намаляване, разделянето на изхода на картата се извършва въз основа на ключа.
Hadoop Partitioning указва, че всички стойности за всеки ключ са групирани заедно. Той също така гарантира, че всички стойности на един ключ отиват в един и същ редуктор. Това позволява равномерно разпределение на изхода на картата върху редуктора.
Partitioner в задание MapReduce пренасочва изхода на картографа към редуктор, като определя кой редуктор обработва конкретния ключ.
Разпределител по подразбиране на Hadoop
Hash Partitioner е разделителят по подразбиране. Той изчислява хеш стойност за ключа. Той също така присвоява дяла въз основа на този резултат.
Колко дялове в Hadoop?
Общият брой на Partitioner зависи от броя на редукторите. Hadoop Partitioner разделя данните според броя на редукторите. Задава се от JobConf.setNumReduceTasks() метод.
По този начин единичният редуктор обработва данните от единичен разделител. Важното, което трябва да забележите, е, че рамката създава разделител само когато има много редуктори.
Лошо разделяне в Hadoop MapReduce
Ако при въвеждане на данни в заданието MapReduce един ключ се появява повече от всеки друг ключ. В такъв случай, за да изпратим данни към дяла, използваме два механизма, които са както следва:
- Ключът, който се появява повече пъти, ще бъде изпратен до един дял.
- Всички останали ключове ще бъдат изпратени до дялове въз основа на техния hashCode() .
Ако hashCode() методът не разпределя други ключови данни в обхвата на дяловете. Тогава данните няма да се изпращат към редукторите.
Лошото разделяне на данните означава, че някои редуктори ще имат повече входни данни в сравнение с други. Те ще имат повече работа от другите редуктори. Така цялата работа трябва да изчака един редуктор да завърши своя изключително голям дял от натоварването.
Как да преодолеем лошото разделяне в MapReduce?
За да преодолеем лошия разделител в Hadoop MapReduce, можем да създадем персонализиран разделител. Това позволява споделяне на натоварването между различни редуктори.
Заключение
В заключение, Partitioner позволява равномерно разпределение на изхода на картата върху редуктора. В MapReducer Partitioner разделянето на изхода на карта се извършва въз основа на ключа и стойността.
Следователно ние разгледахме пълния преглед на Partitioner в този блог. Надявам се да ви е харесало. Ако имате някакви съмнения относно Hadoop Partitioner, не забравяйте да споделите с нас.



