Този урок за Hadoop е всичко за разбъркване и сортиране на MapReduce. Тук ще ви предоставим подробно описание на фазата на размесване и сортиране на Hadoop.
Първо ще обсъдим какво представлява MapReduce Shuffling, следващо MapReduce Sorting, след което ще разгледаме подробно фазата на вторично сортиране на MapReduce.
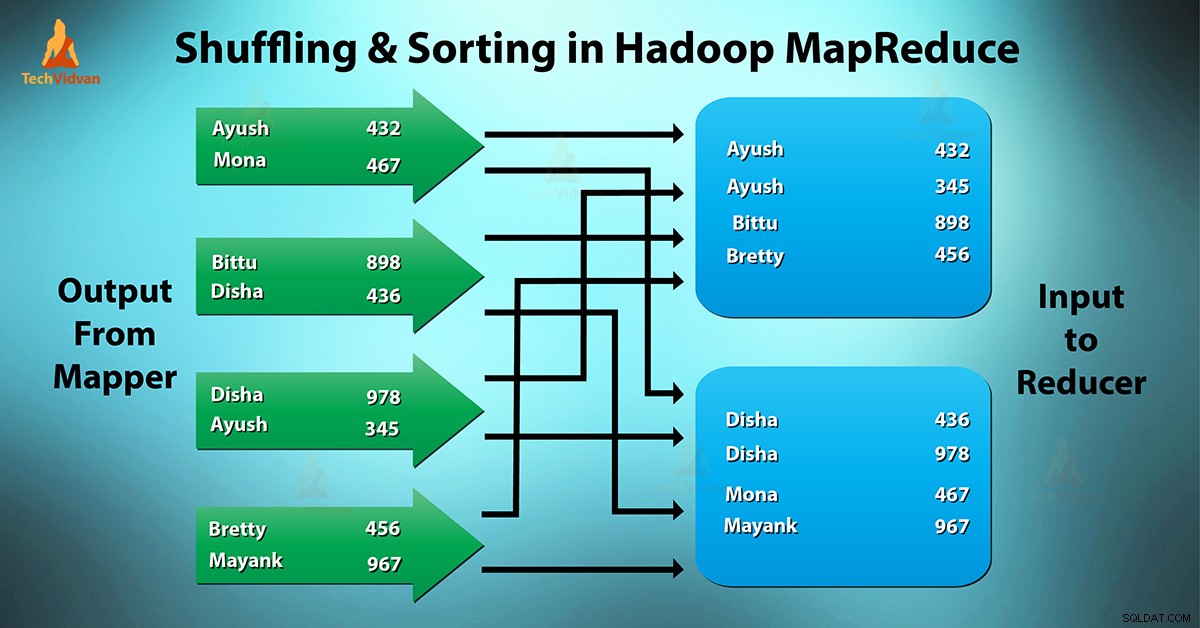
Какво е MapReduce разбъркване и сортиране?
Разбъркване е процесът, чрез който прехвърляmapperи междинен изход къмредуктор. Редукторът получава 1 или повече ключа и свързани стойности на базата на редукторите.
Междинният ключ – стойност, генерирана от мапера, се сортира автоматично по ключ. Във фазата на сортиране се извършва сливане и сортиране на изхода от карта.
Разбъркването и сортирането в Hadoop се извършват едновременно.
Разбъркване в MapReduce
Процесът на прехвърляне на данни от картографите към редукторите се разбърква. Това е и процесът, чрез който системата извършва сортирането. След това прехвърля изхода на картата към редуктор като вход. Това е причината фазата на разбъркване да е необходима за редукторите.
В противен случай те няма да имат никакъв вход (или вход от всеки картограф). Тъй като разбъркването може да започне дори преди да е приключила фазата на картата. Така че това спестява известно време и изпълнява задачите за по-малко време.
Сортиране в MapReduce
MapReduce Framework автоматично сортира ключовете, генерирани от картографа. По този начин, преди стартиране на редуктор, всички междинни двойки ключ-стойност се сортират по ключ, а не по стойност. Той не сортира стойностите, предадени на всеки редуктор. Те могат да бъдат в произволен ред.
Сортирането в задание на MapReduce помага на редуктора лесно да различи кога трябва да започне нова задача за намаляване.
Това спестява време на редуктора. Редукторът в MapReduce стартира нова задача за намаляване, когато следващият ключ в сортираните входни данни е различен от предишния. Всяка задача за намаляване приема двойки ключ-стойност като вход и генерира двойка ключ-стойност като изход.
Важното, което трябва да се отбележи, е, че разбъркването и сортирането в Hadoop MapReduce въобще няма да се осъществи, ако посочите нулеви редуктори (setNumReduceTasks(0)).
Ако редукторът е нула, тогава заданието MapReduce спира на фазата на картата. И фазата на картата не включва никакво сортиране (дори фазата на картата е по-бърза).
Вторично сортиране в MapReduce
Ако искаме да сортираме стойностите на редуктор, тогава използваме техника за вторично сортиране. Тази техника ни позволява да сортираме стойностите (във възходящ или низходящ ред), предавани на всеки редуктор.
Заключение
В заключение, разместването и сортирането на MapReduce се извършват едновременно, за да се обобщи междинния изход на Mapper. Hadoop Shuffling-Sorting няма да се осъществи, ако посочите нулеви редуктори (setNumReduceTasks (0)).
Framework сортира всички междинни двойки ключ-стойност по ключ, а не по стойност. Той използва вторично сортиране за сортиране по стойност. Ако имате някакво предложение или запитване, свързано с фазата на разбъркване и сортиране на MapReduce, моля, оставете коментар в полето за коментари.
Ще се радваме да ги разрешим.



