В предишния ни урок за Hadoop , проучихме Hadoop Partitioner подробно. Сега ще обсъдим InputSplit в Hadoop MapReduce.
Тук ще покрием какво представлява Hadoop InputSplit, необходимостта от InputSplit в MapReduce. Ще обсъдим и как тези InputSplits се създават в Hadoop MapReduce с много подробности.
Въведение във InputSplit в Hadoop
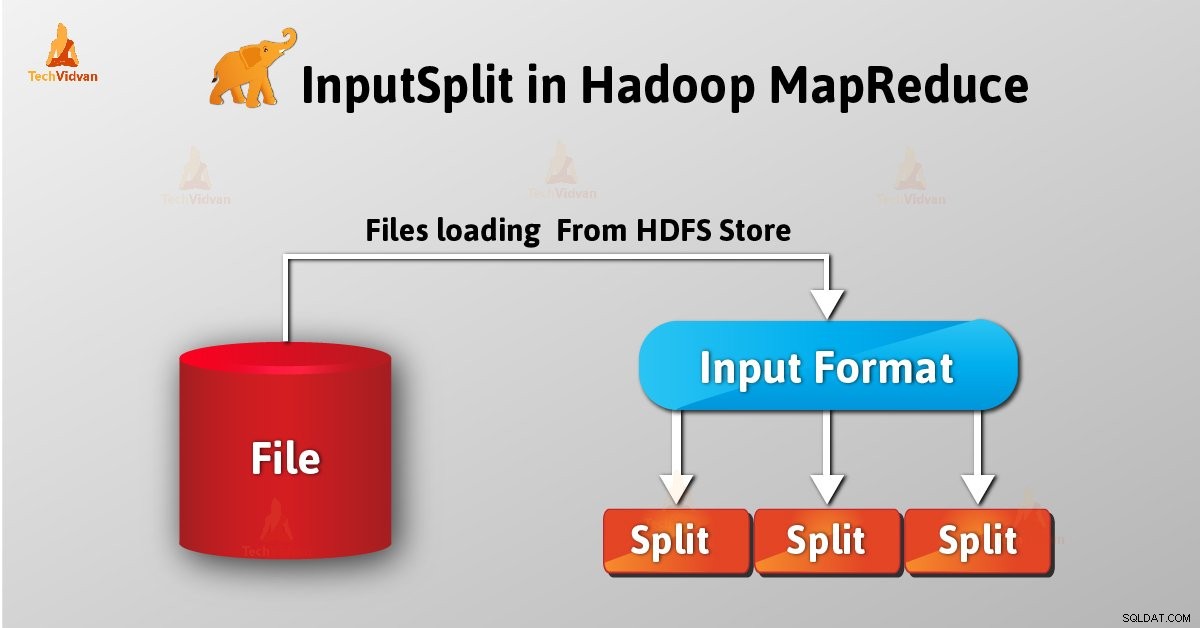
InputSplit е логическото представяне на данните в Hadoop MapReduce. Представлява данните кой отделна маппера процеси. По този начин броят на картографските задачи е равен на броя на InputSplits. Framework разделя разделяне на записи, които картографират обработващи.
Дължината на MapReduce InputSplit е измерена в байтове. Всеки InputSplit има места за съхранение (низове с име на хост). Местата за MapReduce системни Карта на задачи като в близост до данни на Сплит, колкото е възможно чрез използване на местата за съхранение.
Рамкови процеси Картирайте задачите в реда на размера на разделянето, така че най-големият да се обработва първи (алгоритъм за алчен апроксимационен алгоритъм). Това минимизира времето за изпълнение на заданието.
Основното нещо, на което трябва да се съсредоточите, е, че Inputsplit не съдържа входните данни; това е просто препратка към данните.
Как се създават InputSplits в Hadoop MapReduce?
Като потребител, ние не се занимаваме директно с InputSplit в Hadoop, като InputFormat (Като InputFormat е отговорен за създаването на Inputsplit и разделяне на записите) той създава. FileInputFormat разбива файл на 128MB парчета.
Също така, като зададетеmapred .мина .разделяне .размер параметър вmapred-site .xml потребителят може да промени стойността според изискването. Също така от това можем да замените параметъра в обекта на работа се използва за представяне на специално MapReduce работа.
Чрез написването на персонализиран InputFormat можем също да контролираме как файлът се разбива на разделяния.
InputSplit е дефиниран от потребителя. Потребителят може също да контролира размера на разделяне въз основа на размера на данните в програмата MapReduce. Следователно при изпълнение на задание MapReduce броят на задачите за карта е равен на броя на InputSplits.
Чрез извикване на ‘getSplit()’ , клиентът изчислява разделянето за заданието. След това се изпраща до главната програма на приложението, която използва местоположенията им за съхранение, за да планира задачите на картата, които ще ги обработват в клъстера.
След тази задача за карта предава разделянето на createRecordReader() метод. От това получава RecordReader за разделянето. След това RecordReader генерира запис (двойка ключ-стойност) , която предава на функцията map.
Заключение
В заключение можем да кажем, че InputSplit представлява данните, които отделният картограф обработва. За всяко разделяне се създава една задача за карта. Следователно InputFormat създава InputSplit.
Ако имате някакви въпроси относно InputSplit в MapReduce, така че, моля, оставете коментар в раздел, дадена по-долу.



