Ако искате да знаете всичко за Hadoop MapReduce, вие сте попаднали на правилното място. Този урок за MapReduce ви предоставя пълно ръководство за всеки и всичко в Hadoop MapReduce.
В това въведение в MapReduce ще проучите какво представлява Hadoop MapReduce, как работи рамката MapReduce. Статията също така обхваща MapReduce DataFlow, различни фази в MapReduce, Mapper, Reducer, Partitioner, Cominer, Shuffling, Sorting, Data Locality и много други.
Ние също така включихме предимствата на рамката MapReduce.
Нека първо проучим защо имаме нужда от Hadoop MapReduce.
Защо MapReduce?
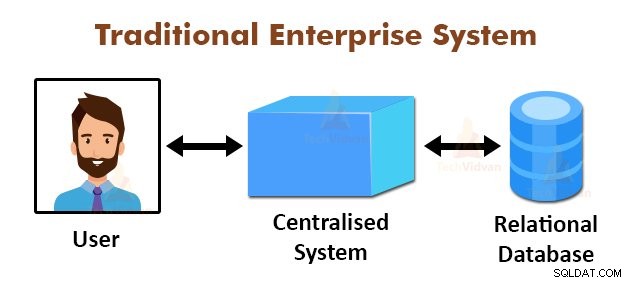
Горната фигура изобразява схематичния изглед на традиционните корпоративни системи. Традиционните системи обикновено имат централизиран сървър за съхранение и обработка на данни. Този модел не е подходящ за обработка на огромни количества мащабируеми данни.
Също така, този модел не може да бъде настанен от стандартните сървъри на бази данни. Освен това централизираната система създава твърде много тесни места, докато обработва няколко файла едновременно.
Използвайки алгоритъма MapReduce, Google разреши този проблем с тесни места. Рамката MapReduce разделя задачата на малки части и възлага задачи на много компютри.
По-късно резултатите се събират на едно място и след това се интегрират, за да формират набора от резултати.
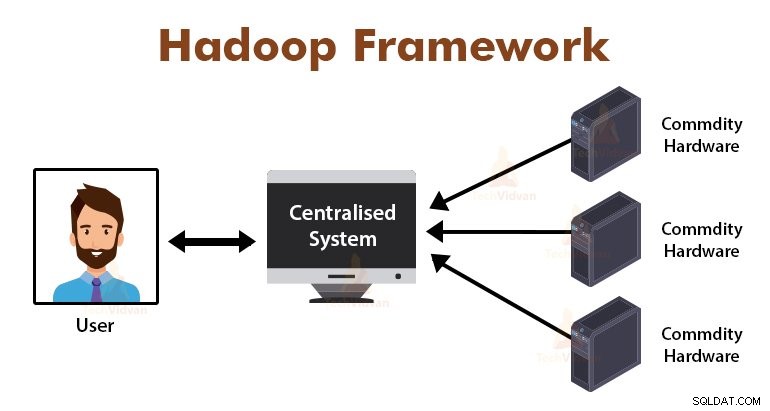
Въведение в MapReduce Framework
MapReduce е обработващият слой в Hadoop. Това е софтуерна рамка, предназначена за паралелна обработка на огромни обеми данни чрез разделяне на задачата на набор от независими задачи.
Просто трябва да поставим бизнес логиката в начина, по който MapReduce работи, а рамката ще се погрижи за останалите неща. Рамката MapReduce работи, като разделя заданието на малки задачи и възлага тези задачи на подчинените.
Програмите MapReduce са написани в определен стил, повлиян от функционалните програмни конструкции, специфични идиоми за обработка на списъците с данни.
В MapReduce входовете са под формата на списък, а изходът от рамката също е под формата на списък. MapReduce е сърцето на Hadoop. Ефективността и мощта на Hadoop се дължат на паралелната обработка на рамката MapReduce.
Нека сега да проучим как работи Hadoop MapReduce.
Как работи Hadoop MapReduce?
Рамката Hadoop MapReduce работи, като разделя заданието на независими задачи и изпълнява тези задачи на подчинени машини. Заданието MapReduce се изпълнява на два етапа, които са фаза на карта и фаза на намаляване.
Входът и изходът от двете фази са двойки ключ, стойност. Рамката MapReduce се основава на принципа за локализиране на данните (обсъден по-късно), което означава, че изпраща изчислението до възлите, където се намират данните.
- Фаза на картата − Във фазата на картата, дефинираната от потребителя функция карта обработва входните данни. Във функцията map потребителят поставя бизнес логиката. Резултатът от фазата на картата е междинните изходи и се съхранява на локалния диск.
- Намаляване на фазата – Тази фаза е комбинация от фаза на разбъркване и фаза на намаляване. Във фазата Reduce изходът от етапа на картата се предава на Reducer, където се обобщава. Резултатът от фазата на намаляване е крайният изход. Във фазата Reduce, дефинираната от потребителя функция за намаляване обработва изхода на Mappers и генерира крайните резултати.
По време на заданието MapReduce, рамката Hadoop изпраща задачите за карта и задачите за намаляване на съответните машини в клъстера.
Самата рамка управлява всички подробности за предаването на данни, като например издаване на задачи, проверка на изпълнението на задачата и копиране на данни между възлите около клъстера. Задачите се изпълняват на възлите, където се намират данните, за да се намали мрежовият трафик.
MapReduce Data Flow
Всички може да искате да знаете как се генерират тези двойки ключови стойности и как MapReduce обработва входните данни. Този раздел отговаря на всички тези въпроси.
Нека видим как данните трябва да протичат от различни фази в Hadoop MapReduce, за да обработваме предстоящите данни по паралелен и разпределен начин.
1. Входни файлове
Входният набор от данни, който трябва да бъде обработен от програмата MapReduce, се съхранява във InputFile. Входният файл се съхранява в разпределената файлова система на Hadoop.
2. InputSplit
Записът във InputFiles се разделя на логическия модел. Размерът на разделяне обикновено е равен на размера на HDFS блока. Всяко разделяне се обработва от отделния Mapper.
3. InputFormat
InputFormat определя спецификацията за въвеждане на файла. Той дефинира пътя към RecordReader, при който записът от InputFile се преобразува в двойки ключ, стойност.
4. RecordReader
RecordReader чете данните от InputSplit и преобразува записи в двойки ключ, стойност и ги представя на Mappers.
5. Картографи
Картографите приемат двойки ключ, стойност като вход от RecordReader и ги обработват, като имплементират дефинирана от потребителя функция за карта. Във всеки Mapper в даден момент се обработва едно разделяне.
Разработчикът постави бизнес логиката във функцията map. Резултатът от всички картографи е междинният изход, който също е под формата на двойки ключ, стойност.
6. Разбъркване и сортиране
Междинният изход, генериран от Mappers, се сортира преди да премине към Reducer, за да се намали претоварването на мрежата. След това сортираните междинни изходи се прехвърлят към редуктора по мрежата.
7. Редуктор
Reducer обработва и агрегира изходите на Mapper чрез прилагане на дефинирана от потребителя функция за намаляване. Изходът на редукторите е крайният изход и се съхранява в разпределената файлова система на Hadoop (HDFS).
Нека сега проучим някои терминологии и предварителни концепции на рамката Hadoop MapReduce.
Двойки ключ-стойност в MapReduce
Рамката MapReduce работи върху двойки ключ, стойност, защото се занимава с нестатичната схема. Той приема данни под формата на двойка ключ, стойност, а генерираният изход също е под формата на двойки ключ, стойност.
Двойката стойност на ключ MapReduce е обект на запис, който се получава от заданието MapReduce за изпълнение. В двойка ключ-стойност:
- Ключът е отместването на реда от началото на реда във файла.
- Стойността е съдържанието на реда, с изключение на завършващите линии.
MapReduce Partitioner
Hadoop MapReduce Partitioner разделя ключовото пространство. Разделянето на ключовото пространство в MapReduce указва, че всички стойности на всеки ключ са групирани заедно и гарантира, че всички стойности на единичния ключ трябва да отидат в един и същ редуктор.
Това разделяне позволява равномерно разпределение на изхода на mapper върху Reducer, като гарантира, че правилният ключ отива към правилния Reducer.
Разпределителят на MapReducer по подразбиране е Hash Partitioner, който разделя ключовите пространства на базата на хеш стойността.
MapReduce Combiner
MapReduce Combiner е известен още като „Полуредуктор“. Той играе основна роля за намаляване на претоварването на мрежата. Рамката MapReduce предоставя функционалността за дефиниране на Combiner, който комбинира междинния изход от Mappers, преди да ги предаде на Reducer.
Обединяването на изходите на Mapper преди преминаване към Reducer помага на рамката да разбърква малки количества данни, което води до ниско претоварване на мрежата.
Основната функция на Combiner е да обобщава изхода на Mappers със същия ключ и да го предава на Reducer. Класът Combiner се използва между класовете Mapper и Reducer.
Местоположение на данните в MapReduce
Локалността на данните се отнася до „Преместване на изчисление по-близо до данните, вместо преместване на данни към изчислението.“ Много по-ефективно е, ако изчислението, поискано от приложението, се изпълнява на машината, където се намират исканите данни.
Това е много вярно в случай, когато размерът на данните е огромен. Това е така, защото свежда до минимум претоварването на мрежата и увеличава общата пропускателна способност на системата.
Единственото предположение зад това е, че е по-добре да преместите изчисленията по-близо до машината, където има данни, вместо да преместите данни към машината, където се изпълнява приложението.
Apache Hadoop работи с огромен обем данни, така че не е ефективно да премествате такива огромни данни по мрежата. Следователно рамката излезе с най-иновативния принцип, който е локалност на данните, който премества изчислителната логика към данни вместо преместване на данни към изчислителни алгоритми. Това се нарича локализиране на данни.
Предимства на MapReduce
1. Мащабируемост: Рамката MapReduce е силно мащабируема. Той позволява на организациите да стартират приложения от големи набори от машини, което може да включва използването на хиляди терабайти данни.
2. Гъвкавост: Рамката MapReduce предоставя гъвкавост на организацията да обработва данни от всякакъв размер и всякакъв формат, структурирани, полуструктурирани или неструктурирани.
3. Сигурност и удостоверяване: Моделът за програмиране MapReduce осигурява висока сигурност. Той защитава всеки неоторизиран достъп до данните и подобрява сигурността на клъстера.
4. Икономичен: Рамката обработва данни в клъстера от стоков хардуер, които са евтини машини. По този начин е много рентабилен.
5. Бързо: MapReduce обработва данни паралелно, поради което е много бърз. Обработката на терабайти данни отнема само минути.
6. Прост модел за програмиране: Програмите MapReduce могат да бъдат написани на всеки език като Java, Python, Perl, R и т.н. Така всеки може лесно да научи и пише програми за MapReduce и да отговори на нуждите си от обработка на данни.
Използване на MapReduce
1. Анализ на журнала: MapReduce се използва основно за анализиране на лог файлове. Рамката разделя големите регистрационни файлове на разделяне и картографско търсене на различните уеб страници, до които е бил достъпен.
Всеки път, когато се намери уеб страница в дневника, тогава двойка ключ, стойност се предава на редуктор, където ключът е уеб страницата, а стойността е „1“. След като изпратят двойка ключ, стойност към Reducer, редукторите обобщават броя на за определени уеб страници.
Крайният резултат ще бъде общият брой посещения за всяка уеб страница.
2. Индексиране на пълен текст: MapReduce се използва и за извършване на индексиране на пълен текст. Картографът в MapReduce ще съпоставя всяка фраза или дума в един документ с документа. Редукторът ще запише тези съпоставяния в индекс.
3. Google използва MapReduce за изчисляване на техния Pagerank.
4. Графика на обратната уеб връзка: MapReduce се използва и в Reverse Web-Link GRAph. Функцията Map извежда целта на URL адреса и източника, вземайки вход от уеб страницата (източник).
След това функцията за намаляване обединява списъка с всички изходни URL адреси, които са свързани с дадения целеви URL адрес, и връща целта и списъка с източници.
5. Брой думи в документ: MapReduce рамката може да се използва за преброяване на броя на появяването на думата в документ.
Резюме
Това е всичко за урока за Hadoop MapReduce. Рамката обработва огромни обеми от данни успоредно в клъстера от стоков хардуер. Той разделя заданието на независими задачи и ги изпълнява паралелно на различни възли в клъстера.
MapReduce преодолява тесното място на традиционната корпоративна система. Рамката работи върху двойки ключ, стойност. Потребителят дефинира двете функции, които са функция за карта и функция за намаляване.
Бизнес логиката е поставена във функцията map. Статията обясняваше различни усъвършенствани концепции на рамката MapReduce.



