Вземете знанията за бъдещето на незаменимата рамка, Apache Hadoop.
Без анализ на Big Data компаниите са слепи и глухи, лутайки се в мрежата като елени по магистрала. – от Джефри Мур, американски консултант по управление и автор.
В тази статия ще видим бъдещето на Hadoop в анализа на големи данни. Статията показва прогнозите на експертите, свързани с възможностите за работа в Hadoop. Ще видите също списъка на компаниите, които приемат Hadoop и различни домейни като финансови сектори, сектори на здравеопазването, използващи Hadoop.
Статията включва различните работни профили, предлагани в Big Data Hadoop.
Нека първо видим нарастването на големите данни, което кара компаниите да приемат Hadoop.
Нарастващи големи данни
Прогнозите казват, че до 2025 г. всеки ден в световен мащаб ще се създават 463 екзабайта данни, което е еквивалентно на 212 765 957 DVD-та на ден!
Всеки ден се изпращат 500 милиона туитове, 294 милиарда имейла, 4 петабайта данни се създават във Facebook, 4 терабайта данни се създават от всяка свързана кола, 65 милиарда съобщения се изпращат в WhatsApp и много други. Така през 2020 г. всеки човек генерира 1,7 мегабайта само за секунда.
Можете ли да си представите, че всеки ден генерираме 2,5 квинтилиона байта данни!
Тези големи данни без информация са безсмислени. Стартъпите и компаниите от Fortune 500 приемат Big Data за постигане на експоненциален растеж.
Организациите вече осъзнаха предимствата на анализа на големи данни, който им помогна да получат бизнес прозрения, което подобрява възможностите им за вземане на решения.
Предвижда се пазарът на големи данни до 2023 г. да достигне $103 млрд.
През 2020 г., според прогнозите, обемът на глобалната сфера от данни, предмет на анализ на данни, ще нарасне до 40 зетабайта.
Традиционните бази данни не са достатъчно способни да обработват и анализират толкова голям обем неструктурирани данни. Компаниите приемат Hadoop за анализиране на големи данни.
Нека сега да видим какво точно представлява Hadoop и защо е възникнала нуждата от Hadoop, преди да проучим бъдещето на Hadoop.
Какво е Hadoop и защо възникна необходимостта от него?
С възхода на света на големите данни се появи нужда от безупречни системи, които могат да обработват, анализират, съхраняват и извличат такива нарастващи големи данни.
Традиционните бази данни не са достатъчно способни да съхраняват данните, генерирани в текущото време от разнородни източници. Освен това те не са в състояние бързо да обработват тези огромни количества данни.
Hadoop излиза като светлина в света на анализа на големи данни.
През 2008 г. Apache Software Foundation разработи Hadoop като софтуерна рамка с отворен код за съхранение и обработка на огромни количества данни. Той има огромна мощност на обработка, заедно с възможността за паралелна обработка и обработка на неограничен брой задачи/задания.
Поради уникалните функции на Hadoop , като способността му да съхранява големи данни, неговата бърза обработка, устойчивост на грешки, мащабируемост и рентабилност, привличат компаниите да приемат Hadoop.
Освен това Hadoop не е една дума; това е цялостна екосистема, известна като Екосистема Hadoop това носи допълнителна точка за Hadoop, която да се използва от организациите за обработка на големи данни. Hadoop предоставя всичко, от което имат нужда, под един чадър.
Така пазарът на Hadoop се разраства всеки ден и има светло бъдеще.
Бъдещ обхват на Hadoop
Според доклада на Forbes, пазарът на Hadoop и Big Data ще достигне 99,31 милиарда долара през 2022 г., достигайки 28,5% CAGR.
Изображението по-долу описва размера на Hadoop и пазара на големи данни в световен мащаб от 2017 до 2022 г.
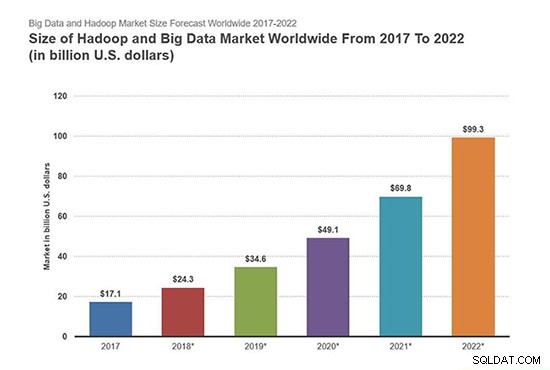
Източник на изображението – Forbes
От горното изображение можем лесно да видим възхода на Hadoop и пазара на големи данни. По този начин изучаването на Hadoop е крайъгълен камък за насърчаване на кариерата в ИТ секторите, както и в много други области.
Компаниите, използващи Hadoop
Изследването показва, че Hadoop има добри пазарни перспективи в много индустрии. С идването на дигиталната вселена се справяме с експлозията на данните. С течение на времето непрекъснато се появяват нови технологии, които допринасят за масив от данни.
Hadoop се очертава като пионерско решение за обработка и съхранение на големи количества данни. Пазарът на Hadoop е разпределен в различни отраслови вертикали.
Можем да кажем, че нито една индустрия не е изоставена да бъде част от пазара на Hadoop. От индустрии в компютърния ИТ сектор до индустрии като болници и здравеопазване, образование, финанси, телекомуникации, търговия на дребно и т.н., всички те имат Hadoop приложения, работещи на тях.
С осъзнаването на предимствата на анализа на големи данни, приемането на Hadoop става все по-експоненциално.
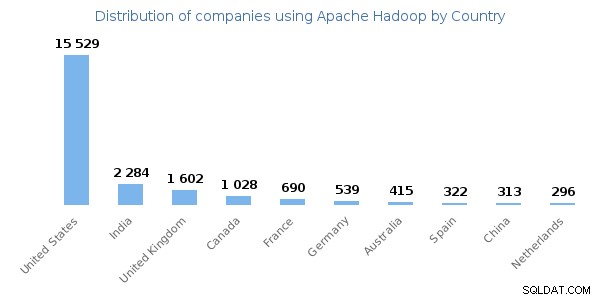
Източник на изображението – enlyft
Изображението по-горе показва разпределението на компаниите, използващи Hadoop по държави. Съединените щати са основният потребител на технологията Hadoop.
Причината за нарастващия пазар на Hadoop е неговата рентабилност, висока наличност, толерантност на грешки и бърз анализ на данни.
Въпреки че има много други инструменти за анализ на големи данни като Apache Spark , Flink и др. се развиват, за да се справят с предизвикателствата с големи данни, но никой не може да замени Hadoop през следващите години, тъй като нямат собствено хранилище, за това зависят от Hadoop.
Дори след повече от 20 години, вероятно все още, няма да има технология, която да съответства на навлизането на Big Data, освен Hadoop.
Големите данни и Hadoop в различни домейни
Нека сега да видим как Hadoop помага на бизнеса да решава проблемите си и в кои различни домейни се изпълняват Hadoop приложения.
a. Банков и финансов сектор
Банковият и финансовият бранш са изправени пред някои от предизвикателствата като картови измами, анализ на отметки, архивиране на одиторска пътека, отчитане на кредитния риск на предприятието и др.
Те използват Hadoop, за да получат ранно предупреждение за измами със сигурността и видимост на търговията. Те използват Hadoop за трансформиране и анализиране на клиентски данни за по-добри прозрения, анализи за подкрепа на решения преди търговия и др.
б. Комуникации, медии и развлечения
Комуникационните, медийните и развлекателните индустрии са изправени пред някои предизвикателства като събиране и анализиране на потребителски данни за прозрения, намиране на модели в използването на медиите в реално време, използване на социални медии и мобилно съдържание.
Използвайки Hadoop, тези компании анализират данните на клиентите за по-добра представа, създават съдържание за различни целеви аудитории.
Например, Wimbledon Championships използва големи данни, за да предостави на потребителите подробен анализ на настроенията относно тенис мачовете в реално време.
в. Доставчици на здравни услуги
Секторите на здравеопазването с помощта на Hadoop анализират неструктурирания формат на данни, който включва история на пациентите, истории на случаи на заболяване. Това им помага да лекуват ефективно пациентите въз основа на предишни случаи.
Освен това, чрез идентифициране на заболяването, което е често срещано в определен район, могат да се вземат предпазни мерки и лекарствата могат да бъдат предоставени на тези области.
Университетът на Флорида използва безплатни данни за общественото здраве и Google Maps, за да визуализира данни, които позволяват по-бързо идентифициране на разпространението на хронично заболяване.
г. Образование
Секторът на образованието използва значително големи данни. Университет на Тасмания с 26 000 студенти е внедрил LMS (система за управление на обучението), която проследява времето в дневника, колко време студентите прекарват на различни страници и цялостния напредък на студента с течение на времето.
д. Правителството
Има различни правителствени схеми, които се изпълняват и генерират огромно количество данни. Администрацията по храните и лекарствата (FDA) използва Big Data за откриване и изследване на моделите на заболявания, свързани с храните, което позволява по-бърз отговор на лечението
Прогнози за работа в анализа на големи данни
До 2023 г. пазарът за анализ на големи данни ще достигне 103 милиарда долара според прогнозите. IBM прогнозира, че търсенето на специалист по данни ще се повиши с 28%.
Над 97,2% от организациите инвестират в големи данни и AI.
Според доклада на PwC до 2022 г. само в САЩ ще има около 2,7 милиона свободни работни места за анализ на данни и наука за данни. Най-големите компании като Cisco, Dell, EY, IBM, Google, Siemens, Twitter, OCBC bank търсят професионалисти от Hadoop, които да обработват и печелят от морето от налични данни.
Особено във финансовата индустрия, застрахователната индустрия и ИТ индустриите изискват 59% от всички работни места на учени по данни.
Изображението по-долу показва средните заплати за професионалисти със съответните аналитични умения. 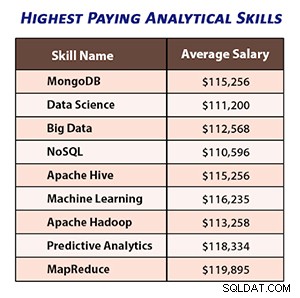
Източник на изображението – наистина
Според скорошния доклад на IBM, специалистите по Data Science и Data Analytics, които имат умения MapReduce, печелят средно $115 907 годишно, което прави MapReduce най-търсеното умение.
Наука за данни и специалисти по анализи с опит в Apache Hadoop, Hive и Pig се състезават за работни места, плащащи над $100 000.
Заплати и длъжности за анализ на големи данни
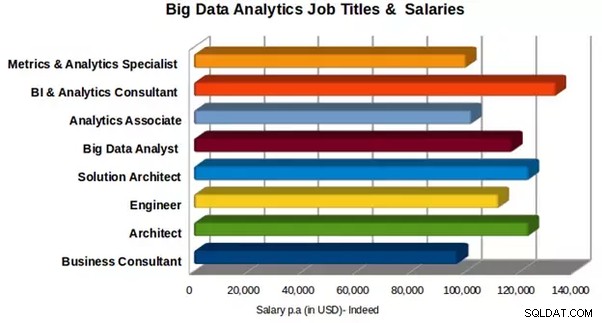
Средната годишна заплата в Обединеното кралство е £66,250-£66,750 за работни места в Hadoop и $92,512 до $102,679 за Hadoop разработчици, според Indeed.
Има различни профили на работа, които се харесват на човека, който има подходящи умения в Hadoop. Някои от тях са:
Администратор на Hadoop
Администраторът на Hadoop настройва Hadoop клъстер и го наблюдава с инструменти за наблюдение. Той следи свързаността и сигурността на клъстера.
Предлаганата заплата е между 10-15 INR LPA .
Hadoop Architect
Hadoop Architect е този, който планира и проектира архитектурата на Big Data Hadoop. Той създава анализ на изискванията и управлява разработката и внедряването в Hadoop приложения. Предлаганият диапазон на заплатите е между 9-11 INR LPA .
Аналитик на големи данни
Big Data Analyst анализира големи данни, за да оцени техническата производителност на компаниите и да даде препоръки за подобряване на системата. Те изпълняват процеси на големи данни като текстови анотации, синтактичен анализ, обогатяване с филтриране. Предварителната заплата е 7-10 INR LPA .
Разработчик на Hadoop
Основната задача на разработчика на Hadoop е да разработва Hadoop технологии, използвайки Java, HQL и скриптови езици. Предлаганата заплата е между 5-10 INR LPA в зависимост от профилите на работа в Индия.
Hadoop Тестер
Тестерът на Hadoop за грешки и бъгове и коригира грешките. Той гарантира, че MapReduce jobs, HiveQL скриптове и Pig Latin скриптове работят правилно. Заплатата на Hadoop Tester е между INR 5-10 LPA .
Резюме
Надявам се, че след като прочетете тази статия, вече сте добре наясно с бъдещето на Hadoop. Нито една технология дори след 20 години няма да замени Apache Hadoop. Така човек, който търси кариерата си в сферата, която никога не излиза от мода, Hadoop е най-добрият избор за тях.
Изумени ли сте от бъдещето на Hadoop?
И така, какво чакате? Започнете да изучавате Hadoop и намерете мечтаната работа и пакет в любимите си страни.
Следвайте лявата странична лента на TechVidvan и започнете да изучавате Hadoop.
Продължавайте да учите!!



