Научете за архитектурата за поглъщане на данни в почти реално време за трансформиране и обогатяване на потоци от данни с помощта на Apache Flume, Apache Kafka и RocksDB в Santander UK.
Cloudera Professional Services работи със Santander UK за изграждането на система за транзакционен анализ в почти реално време (NRT) на Apache Hadoop. Целта е да се улови, трансформира, обогатява, преброява и съхранява транзакция в рамките на няколко секунди след покупката на карта. Системата получава транзакциите с карти за клиенти на дребно на банката и изчислява свързаната информация за тенденциите, обобщена от титуляра на сметката и по редица измерения и таксономии. След това тази информация се обслужва сигурно в приложението „Spendlytics“ на Santander (вижте по-долу), за да се даде възможност на клиентите да анализират най-новите си модели на разходи.
Apache HBase беше избран като основно решение за съхранение поради способността му да поддържа произволно записване с висока пропускателна способност и произволно четене с ниска латентност. Изискването за NRT обаче изключва извършването на трансформации и обогатяване на транзакциите в пакет, така че те трябва да се извършват, докато транзакциите се предават поточно в HBase. Това включва преобразуване на съобщения от XML в Avro и обогатяването им с информация за тенденциите, като например информация за марка и търговец.
Тази публикация описва как Santander използва Apache Flume, Apache Kafka и RocksDB за трансформиране, обогатяване и поточно предаване на транзакции в HBase. Това е реализация на Обработка на събития NRT с външен контекст модел на поточно предаване, описан от Тед Маласка в тази публикация.
Флафка
Първото решение, което Сантандер трябваше да вземе, беше как най-добре да предава данни в HBase. Flume почти винаги е най-добрият избор за поглъщане на поточно предаване в Hadoop, предвид неговата простота, надеждност, богат набор от източници и приемници и присъща мащабируемост.
Наскоро беше добавена отлична интеграция с Kafka, водеща до неизбежно наречения Flafka. Flume може изначално да осигури гарантирана доставка на събития чрез своя файлов канал, но възможността за възпроизвеждане на събития и допълнителната гъвкавост и надеждността на Kafka, които носи Kafka, бяха ключови двигатели за интеграцията.
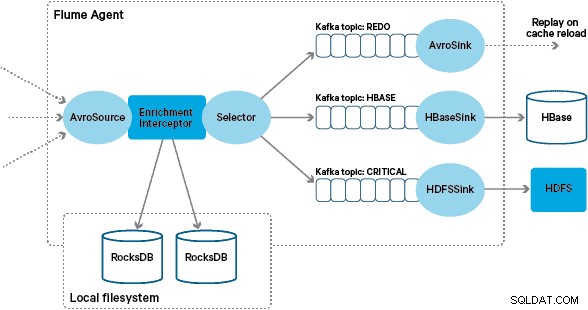
В тази архитектура Santander използва канали на Kafka, за да осигури надежден, самобалансиращ се и мащабируем буфер за поглъщане, в който всички трансформации и обработка са представени във верижни теми на Kafka. По-специално, ние широко използваме източника и мивката на Flafka, както и способността на Flume да извършва обработка по време на полет с помощта на Interceptors. Това ни попречи да кодираме нашия собствен производител и потребител на Kafka и позволи на Santander да се възползва напълно от Cloudera Manager за конфигуриране, внедряване и наблюдение на агентите и брокерите.
Трансформация
Транзакциите, заснети от основните банкови системи, се доставят на Flume като XML съобщения, след като са прочетени от изходната база данни чрез репликация на журнал. (Основяването на регистрационния файл на база данни в темите на Kafka по този начин е все по-често срещан модел и в комбинация с уплътняване на регистрационни файлове може да даде „най-нов изглед“ на базата данни за случаи на използване на улавяне на промени.)
Flume съхранява тези XML съобщения в „сурова“ тема на Kafka. Оттук нататък и като предшественик на всяка друга обработка, беше решено да се трансформира полуструктурираният XML в структурирани двоични записи, за да се улесни стандартизираната обработка надолу по веригата. Тази обработка се извършва от персонализиран Flume Interceptor, който трансформира XML съобщенията в генерично представяне на Avro, като прилага специфични типове, където е подходящо, и се връща обратно към низово представяне, когато не. Цялата последваща NRT обработка след това съхранява извлечените резултати в Avro в специални теми за Kafka, което улеснява включването в потока и получаването на емисия за събитие във всяка точка от веригата за обработка.
Ако се изискваше по-сложна обработка на събития – например агрегиране със Spark Streaming – би било тривиален въпрос да се използва една или повече от тези теми и да се публикуват в нови извлечени теми. (Apache Avro е естествен избор за този формат:това е компактен двоичен протокол, поддържащ еволюцията на схемата, има гъвкава дефиниция на схемата и се поддържа в целия стек на Hadoop. Avro бързо се превръща в де факто стандарт за междинно и общо съхранение на данни в корпоративен център за данни и е идеално разположен за трансформиране в Apache Parquet за аналитични натоварвания.)
Обогатяване
Вдъхновението за дизайна на решението за обогатяване на поточно предаване дойде от публикация на O’Reilly Radar, написана от Джей Крепс. В публикацията си Джей описва ползите от използването на локално хранилище, за да даде възможност на поточния процесор да запитва или променя локално състояние в отговор на неговото въвеждане, за разлика от извършването на отдалечени повиквания към разпределена база данни.
В Santander адаптирахме този модел, за да предоставим локални референтни магазини, които се използват за запитване и обогатяване на транзакции, докато те преминават през Flume. Защо просто не използвате HBase като референтно хранилище? Е, типичен модел за този тип проблеми е просто да съхранявате състоянието в HBase и да накарате механизма за обогатяване да го запита директно. Ние се отказахме от този подход поради няколко причини. Първо, референтните данни са сравнително малки и биха се побрали в един HBase регион, вероятно причинявайки гореща точка на региона. Второ, HBase обслужва насоченото към клиента приложение Spendlytics и Santander не искаше допълнителното натоварване да повлияе на латентността на приложението или обратно. Това е и причината, поради която решихме да не използваме HBase дори за стартиране на локалните магазини при стартиране.
Така че, предоставяйки на всеки агент на Flume бърз локален магазин за обогатяване на събития по време на полет, Santander е в състояние да даде по-добри гаранции за ефективност както за обогатяването по време на полет, така и за приложението Spendlytics. Решихме да използваме RocksDB за внедряване на локалните магазини, защото е в състояние да осигури бърз достъп до големи количества данни извън купчина (елиминира тежестта върху GC) и факта, че има Java API, за да го направи по-лесен за използване от персонализиран Flume Interceptor. Този подход ни спести от необходимостта да кодираме нашия собствен магазин извън купчина. RocksDB може лесно да бъде заменен с друга реализация на локален магазин, но в този случай той беше идеален за случая на използване на Santander.
Персонализираната реализация на Interceptor за обогатяване на Flume обработва събития от „преобразуваната“ тема нагоре по веригата, отправя запитвания към локалното си хранилище, за да ги обогати, и записва резултатите в темите на Kafka надолу по веригата в зависимост от резултата. Този процес е илюстриран по-подробно по-долу.
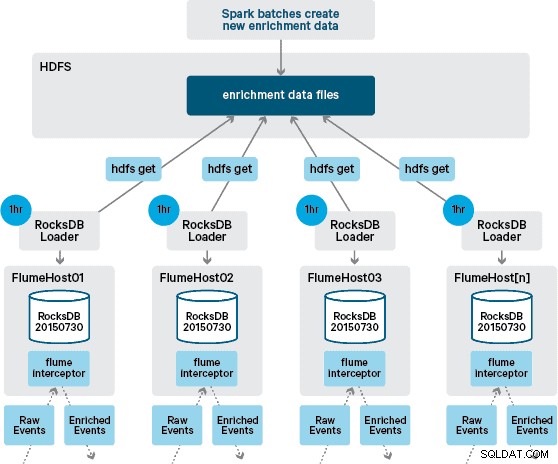
В този момент може да се чудите:При липса на постоянство, предоставено от HBase, как се генерират локалните магазини? Референтните данни включват редица различни набори от данни, които трябва да бъдат обединени. Тези набори от данни се обновяват в HDFS на дневна база и формират вход за планирано приложение Apache Spark, което генерира хранилищата на RocksDB. Новогенерираните хранилища на RocksDB се поставят в HDFS, докато не бъдат изтеглени от агентите на Flume, за да се гарантира, че потокът от събития се обогатява с най-новата информация.
В идеалния случай не би трябвало да чакаме всички тези набори от данни да бъдат налични в HDFS, преди да могат да бъдат обработени. Ако случаят беше такъв, актуализациите на референтните данни биха могли да се предават поточно през тръбопровода Flafka, за да се поддържа непрекъснато състоянието на локалните референтни данни.
В първоначалния ни дизайн планирахме да напишем и планираме чрез cron скрипт за анкета на HDFS, за да проверим за нови версии на магазините на RocksDB, като ги изтеглим от HDFS, когато са налични. Въпреки че поради вътрешния контрол и управлението на производствените среди на Santander, този механизъм трябваше да бъде включен в същия Flume Interceptor, който се използва за извършване на обогатяването (той проверява за актуализации веднъж на час, така че не е скъпа операция). Когато е налична нова версия на магазина, към работна нишка се изпраща задача да изтегли новия магазин от HDFS и да го зареди в RocksDB. Този процес се случва на заден план, докато Interceptor за обогатяване продължава да обработва потока. След като новата версия на магазина се зареди в RocksDB, Interceptor преминава към най-новата версия и изтеклият магазин се изтрива. Същият механизъм се използва за стартиране на хранилищата на RocksDB от студено стартиране, преди Interceptor да започне да се опитва да обогатява събитията.
Успешно обогатените съобщения се записват в тема на Kafka, за да бъдат идемпотентно записани в HBase с помощта на HBaseEventSerializer.
Докато потокът от събития се обработва непрекъснато, нови версии на локалния магазин могат да се генерират само ежедневно. Веднага след като нова версия на местния магазин бъде заредена от Flume, тя се счита за свежа,” въпреки че става все по-стара преди наличността на нова версия. Следователно броят на „пропуските в кеша“ се увеличава, докато не бъде налична по-нова версия на локалния магазин. Например, нова и актуализирана информация за марка и търговец може да бъде добавена към референтните данни, но докато не бъде предоставена на Flume за обогатяване Interceptor транзакциите може да не успеят да бъдат обогатени или да бъдат обогатени с неактуална информация, която по-късно трябва да бъде съгласувано, след като е било запазено в HBase.
За да се справи с този случай, пропуските в кеша (събития, които не могат да бъдат обогатени) се записват в „повторна“ тема на Kafka с помощта на Flume Selector. След това темата за повторно изпълнение се възпроизвежда обратно в изходната тема на Interceptor за обогатяване, когато е наличен нов локален магазин.
За да предотвратим „отровни съобщения“ (събития, които непрекъснато не успяват да обогатяват), решихме да добавим брояч към заглавката на събитие, преди да го добавим към темата за повторно изпълнение. Събитията, които се появяват многократно по тази тема, в крайна сметка се пренасочват към „критична“ тема, която се записва в HDFS за по-късна проверка и отстраняване. Този подход е илюстриран на първата диаграма.
Заключение
За да обобщим основните изводи от тази публикация:
- Използването на верига от теми на Kafka за съхраняване на междинни споделени данни като част от вашия тръбопровод за поглъщане е ефективен модел.
- Имате множество опции за запазване и заявка за състояние или референтни данни във вашия тръбопровод за поглъщане на NRT. Предпочитайте HBase за тази цел като често срещан модел, когато допълнителните данни са големи, но помислете за използването на вградени локални магазини (като RocksDB) или JVM памет, когато използвате HBase, не е практично.
- Обработването на неизправности е важно. (Вижте № 1 за помощ по въпроса.)
В последваща публикация ще опишем как използваме копроцесорите HBase за предоставяне на агрегирани данни на клиент за исторически тенденции при закупуване и как офлайн транзакциите се обработват пакетно (проект Cloudera Labs) SparkOnHBase (който наскоро беше ангажиран в багажник HBase). Ще опишем също как решението е проектирано, за да отговори на изискванията на клиента за кръстосани центрове за данни и висока наличност.
Джеймс Кинли, Иън Бъс и Роб Сивики са архитекти на решения в Cloudera.



