HBase записва данни на множество сървъри, наречени Регионални сървъри .
Всеки регионален сървър съдържа един или няколко региона и данните се разпределят за тези региони; Hbase ще контролира кой регион сървър контролира кой регион(и).
Номерът на регионите може да бъде дефиниран на ниво създаване на таблица :
[hbase@gw vagrant]$ kinit -kt /etc/security/keytabs/hbase.headless.keytab hbase
[hbase@gw vagrant]$ hbase shell
hbase(main):001:0> create 'table2', 'columnfamily1', {NUMREGIONS => 5, SPLITALGO => 'HexStringSplit'}По-рано дефинирахме, че 5 региона биха били точни по отношение на броя на сървърите на региона и желания размер на регионите и предоставят се 2 основни алгоритма, HexStringSplit и UniformSplit (но можете да добавите своя).
Можете да предоставите свои собствени разделяния :
hbase(main):001:0> create 'table2', 'columnfamily1', {NUMREGIONS => 5, SPLITS=> ['a', 'b', 'c']}
Така че тази таблица2 е създаден с нашите 5 региона, нека отидем в HBase webUI, за да видим как изглежда:
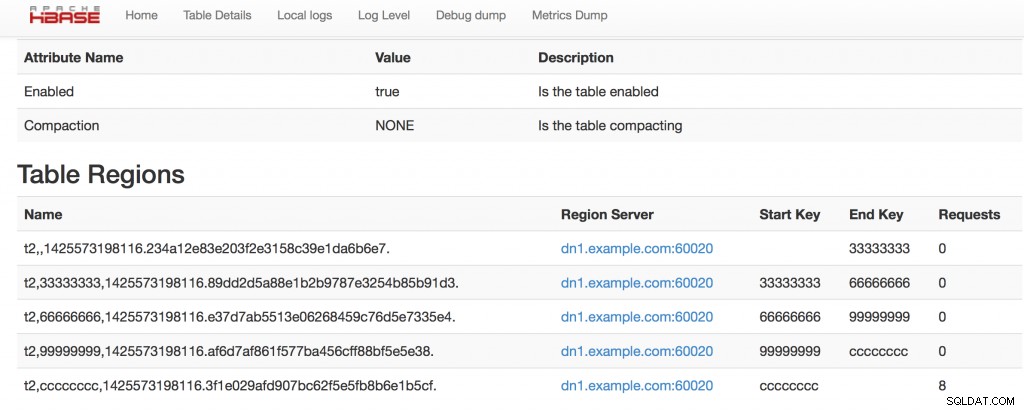 Имаме нашите 5 региона, вижте преразпределението на ключовете и можем да видим имената на регионите:table_name, start_key,end_key,timestamp.ENCODED_REGIONNAME.
Имаме нашите 5 региона, вижте преразпределението на ключовете и можем да видим имената на регионите:table_name, start_key,end_key,timestamp.ENCODED_REGIONNAME.
Така че сега, ако искаме да обединим региони, можем да използваме merge_region в hbase shell.
Регионите трябва да са съседни.
hbase(main):010:0> merge_region '234a12e83e203f2e3158c39e1da6b6e7', '89dd2d5a88e1b2b9787e3254b85b91d3'
0 row(s) in 0.0140 secondsДа.
Забележете, че ENCODED_REGIONNAME на резултатния регион е нов.
hbase(main):012:0> merge_region 'bfad503057fca37bd60b5a83109f7dc6','e37d7ab5513e06268459c76d5e7335e4'
0 row(s) in 0.0040 secondsНека всички региони да се слеят в крайна сметка!
hbase(main):013:0> merge_region '0f5fc22bf0beacbf83c1ad562324c778','af6d7af861f577ba456cff88bf5e5e38','3f1e029afd907bc62f5e5fb8b6e1b5cf','3f1e029afd907bc62f5e5fb8b6e1b5cf'
0 row(s) in 0.0290 secondsТогава можем да видим, че остава само един регион :

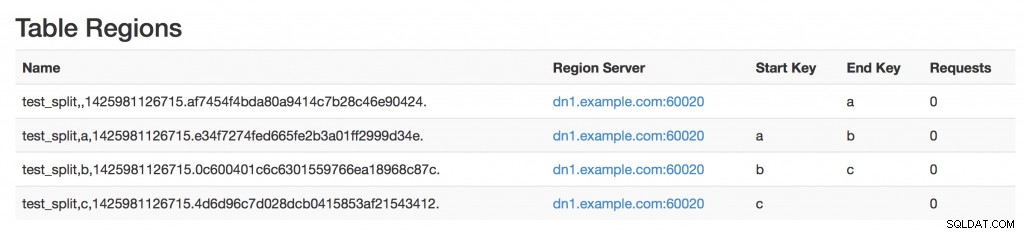
За протокола можете да създадете HBase таблица, предварително разделена, ако знаете повторното разделяне на вашите ключове:или чрез предаване на SPLITS, или чрез предоставяне на SPLITS_FILE, който съдържа точките на разделяне (така че редове номер =региони -1)
Имайте предвид поръчката, SPLITS_FILE преди {…} няма да работи.
[hbase@gw vagrant]$ echo "a\nb\nc" > /tmp/splits.txt;
[hbase@gw vagrant]$ kinit -kt /etc/security/keytabs/hbase.headless.keytab hbase
[hbase@gw vagrant]$ hbase shell
hbase(main):011:0> create 'test_split', { NAME=> 'cf', VERSIONS => 1, TTL => 69200 }, SPLITS_FILE => '/tmp/splits.txt'И резултатът :