Архивиране - едно от най-важните неща, за които трябва да се грижите, докато управлявате бази данни. Казва се, че има два типа хора - тези, които архивират своите данни и тези, които ще архивират данните си. В тази публикация в блога ще обсъдим добри практики за архивиране и ще ви покажем как можете да изградите надеждна система за архивиране с помощта на ClusterControl.
Ще видим как ClusterControl’s ви предоставя централизирано управление на архивиране за MySQL, MariaDB, MongoDB и PostgreSQL. Той ви предоставя горещи архиви на големи набори от данни, възстановяване в момента, криптиране на данни в състояние на покой и по време на пренос, целостта на данните чрез автоматична проверка за възстановяване, облачни архиви (AWS, Google и Azure) за възстановяване след бедствие, правила за запазване, за да се гарантира съответствие и автоматизирани сигнали и отчитане.
Типове архивиране
Има два основни типа архивиране, които можем да направим в ClusterControl:
- Логически архивиране – архивирането на данни се съхранява в четим от човека формат като SQL
- Физическо архивиране – архивирането съдържа двоични данни
И двете се допълват взаимно - логическото архивиране ви позволява (повече или по-малко лесно) да извлечете до един ред данни. Физическите архиви ще изискват повече време, за да се постигне това, но, от друга страна, те ви позволяват да възстановите цял хост много бързо (нещо, което може да отнеме часове или дори дни, когато използвате логическо архивиране).
ClusterControl поддържа архивиране за MySQL/MariaDB/Percona Server, PostgreSQL и MongoDB.
График за архивиране
Стартирането на архивиране в ClusterControl е лесно и ефективно с помощта на съветник. Планирането на архивиране предлага удобство за потребителя и достъпност до други функции като криптиране, автоматичен тест/проверка на архивиране или архивиране в облак.
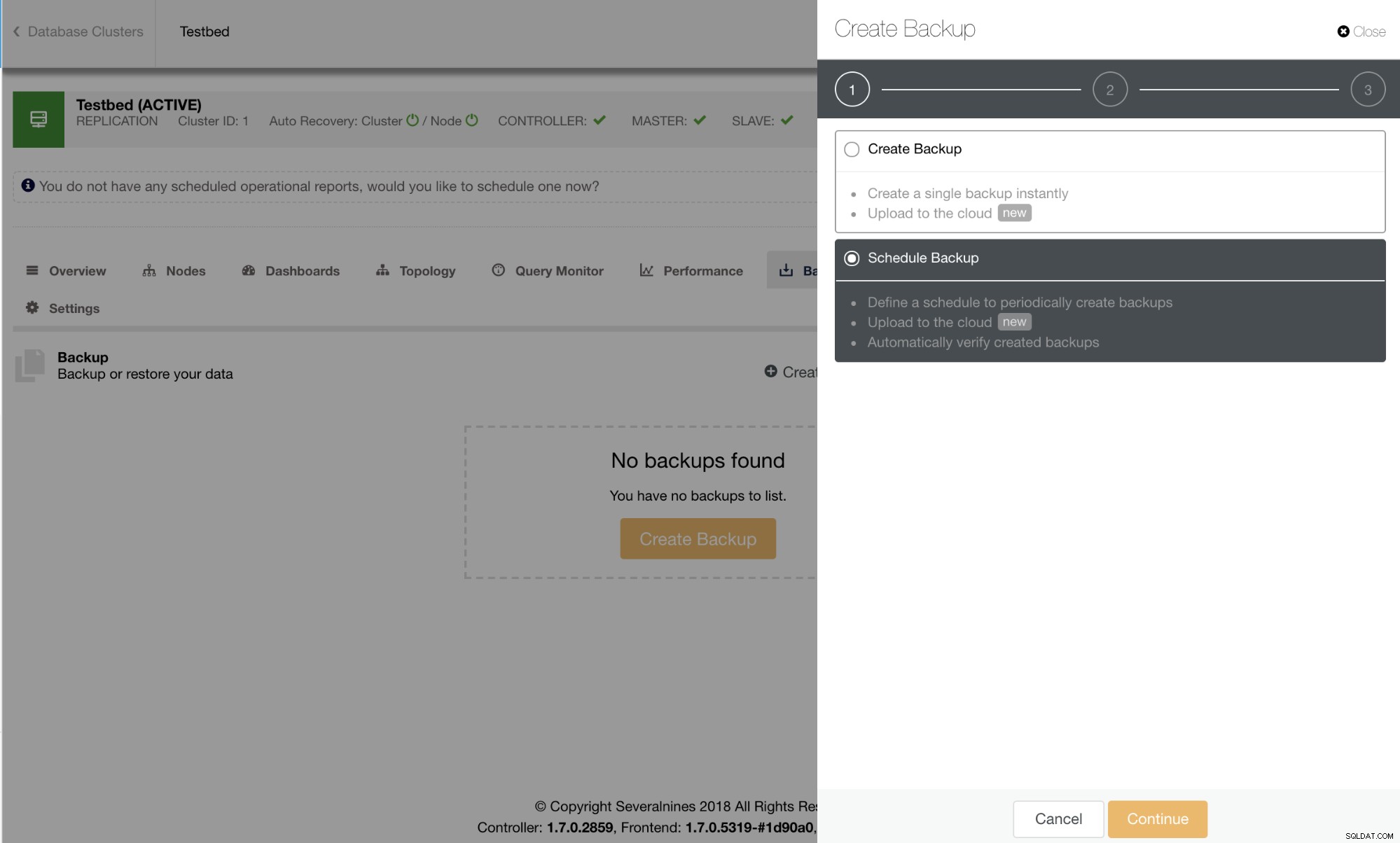
Наличните по график архивиране ще бъдат изброени в раздела Планирани архиви, както се вижда на изображението по-долу:
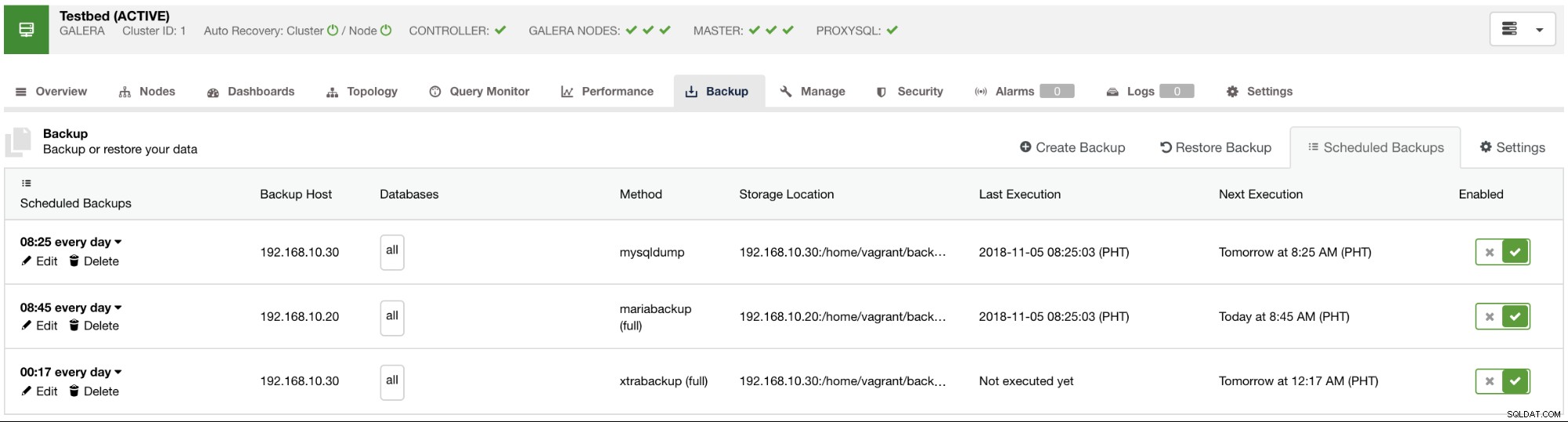
Като добра практика за планиране на архивиране, трябва да имате вече дефинирано запазване на резервно копие и се препоръчва ежедневно архивиране. Въпреки това, това също зависи от данните, от които се нуждаете, трафика, който може да очаквате, и наличността на данните, когато имате нужда от тях, особено по време на възстановяване на данни, когато данните са били случайно изтрити или повреда на диска - които са неизбежни. Има ситуации също така, че загубата на данни е възпроизводима или може да бъде дублирана ръчно, като например генериране на отчети, миниатюри или кеширани данни. Въпреки че въпросът се основава на това колко незабавно се нуждаете от тях, когато се случи бедствие; когато е възможно, бихте искали да правите както mysqldump, така и xtrabackup резервни копия на дневна база за MySQL, използвайки логическото и физическото архивиране. За да покриете още повече бази, може да искате да планирате няколко инкрементални екстрабекъпни стартирания на ден. Това може да спести малко дисково пространство, дисков I/O или дори CPU I/O, отколкото да направите пълно архивиране.
В ClusterControl можете лесно да планирате тези различни видове архивиране. Има няколко настройки, за които да вземете решение. Можете да съхранявате резервно копие на контролера или локално, на възела на базата данни, където се прави архивирането. Трябва да решите къде да се съхранява архивът и кои бази данни искате да архивирате – целия набор от данни или отделни схеми? Вижте изображението по-долу:
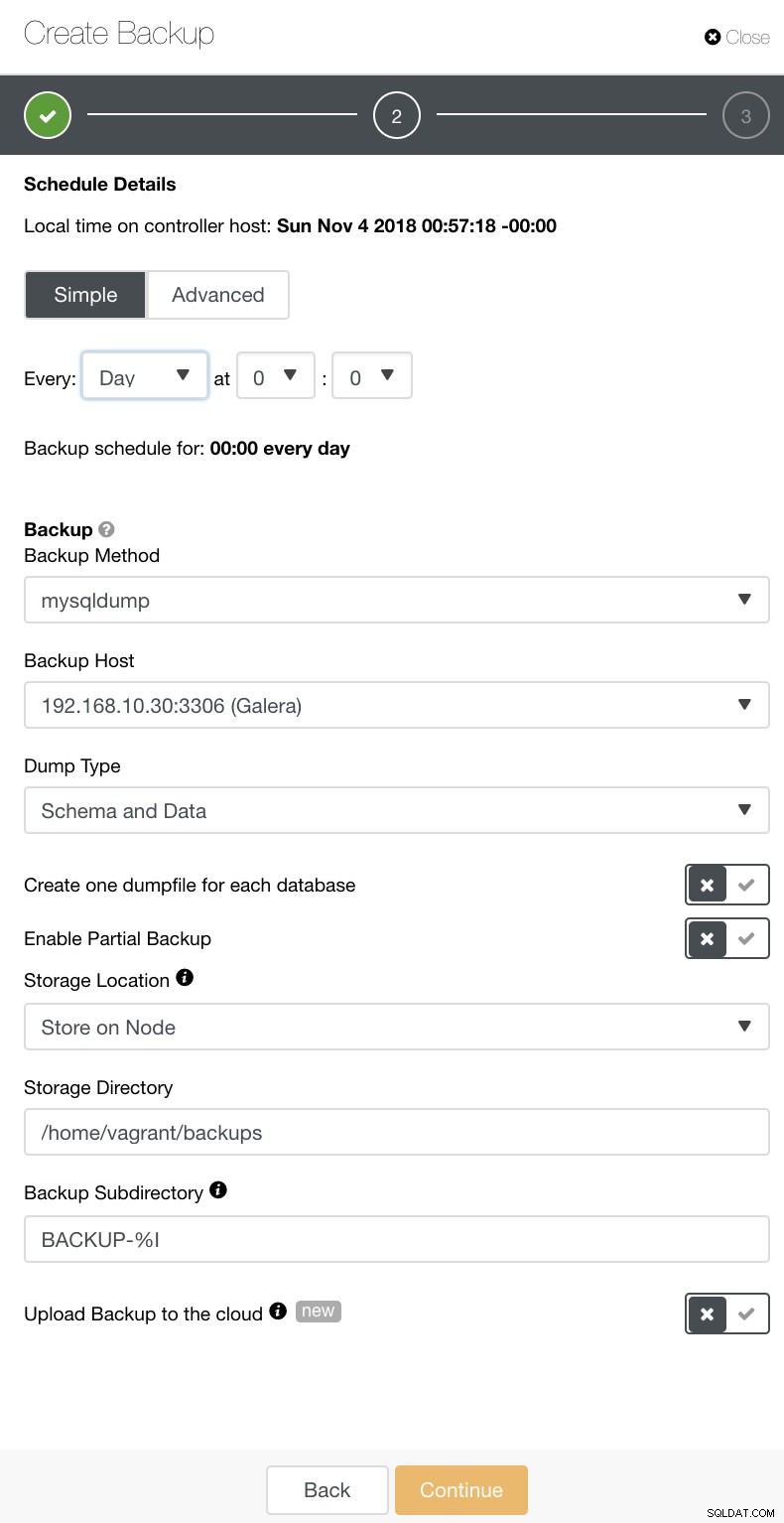
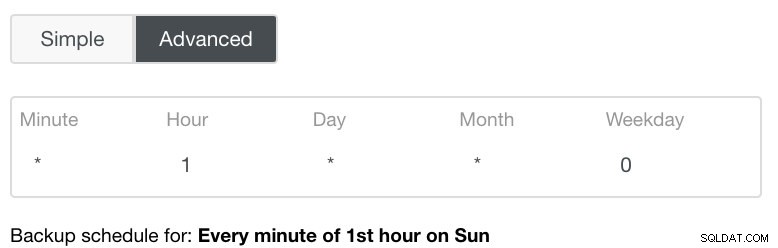
Разширената настройка ще се възползва от конфигурация, подобна на cron, за по-голяма детайлност. Вижте изображението по-долу:
Всеки път, когато възникне повреда, ClusterControl се справя ефективно с тези проблеми и създава регистрационни файлове за по-нататъшна диагностика на грешката при архивирането.
В зависимост от типа архивиране, който сте избрали, има отделни настройки за конфигуриране. За Xtrabackup и Galera Cluster може да имате опциите да изберете какви настройки да приложи физическото ви архивиране при стартиране. Вижте по-долу:
- Използвайте компресия
- Ниво на компресия
- Десинхронизиране на възел по време на архивиране
- Резервни ключалки
- Заключване на DDL за таблица
- Xtrabackup паралелни нишки за копиране
- Скорост на мрежовото поточно предаване (MB/s)
- Използвайте PIGZ за паралелен gzip
- Активиране на шифроването
- Задържане
Можете да видите на изображението по-долу как бихте могли да маркирате опциите съответно и има икони на подсказки, които предоставят повече информация за опциите, които искате да използвате за вашата политика за архивиране.
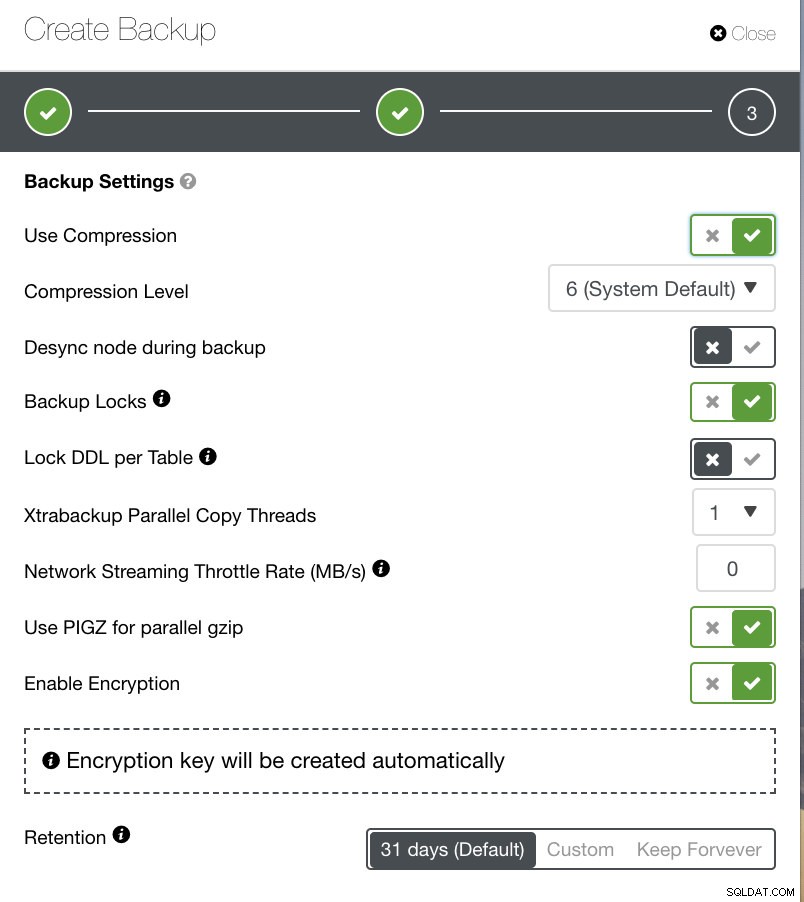
В зависимост от вашата политика за архивиране, ClusterControl може да бъде настроен в съответствие с най-добрите практики за вземане на вашите резервни копия, които са налични, актуални. След дефинирането на вашата политика за архивиране се очаква, че трябва да имате налична необходимата ви настройка от хардуер до софтуер до облак, издръжливост, висока наличност или мащабируемост.
Когато правите резервни копия на клъстер Galera, добра практика е да настроите възела на Galera wsrep_desync=ON, докато архивирането се изпълнява. Това ще премахне възела от участие в контрола на потока и ще защити целия клъстер от забавяне на репликацията, особено ако данните ви, които трябва да бъдат архивирани, са големи. В ClusterControl, моля, имайте предвид, че това може също да премахне целевия резервен възел от комплекта за балансиране на натоварването. Това е особено вярно, ако използвате прокси сървъри HAProxy, ProxySQL илиMaxScale. Ако сте настроили мениджъра на сигнали, в случай че възелът е десинхронизиран, можете да изключите през този период, когато архивирането е задействано.
Друг популярен начин за минимизиране на въздействието на архивиране върху клъстер Galera или главен главен файл на репликация е разгръщането на подчинен сървър за репликация и след това да се използва като източник на архиви - по този начин Galera Cluster няма да бъде засегнат в нито един момент, тъй като архивирането на slave е отделен от клъстера.
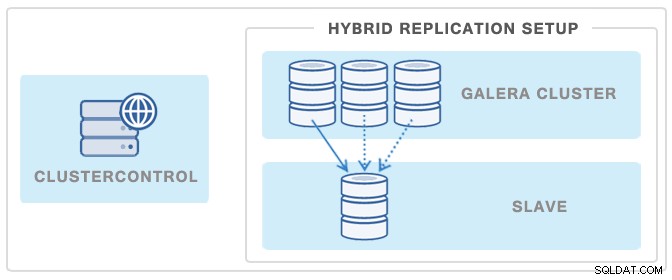
Можете да разположите такъв подчинен само с няколко щраквания с помощта на ClusterControl. Вижте изображението по-долу:
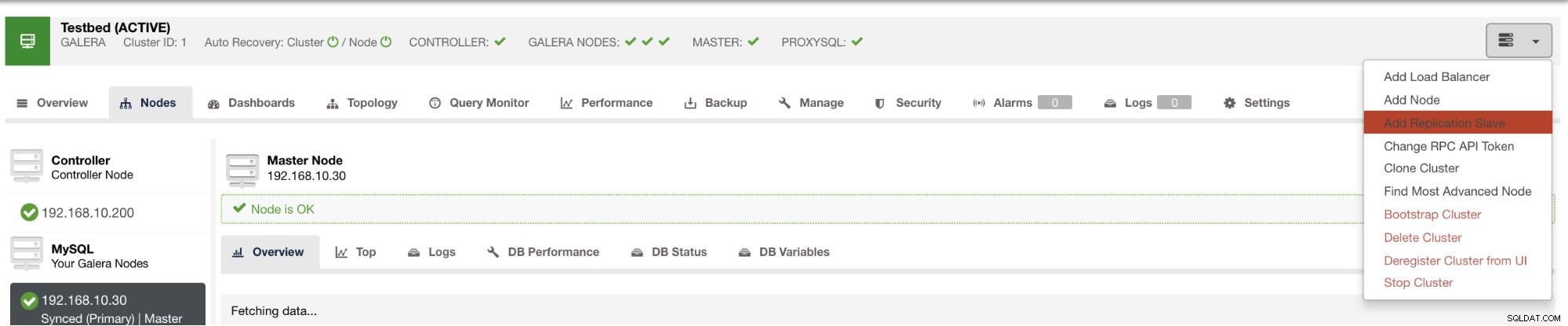
и след като щракнете върху този бутон, можете да изберете на кои възли да настроите подчинен. Уверете се, че двоичното регистриране на възлите е активирано. Активирането на двоичния дневник може да стане и чрез ClusterControl, което добавя повече възможности за администриране на желания от вас главен файл. Вижте изображението по-долу:
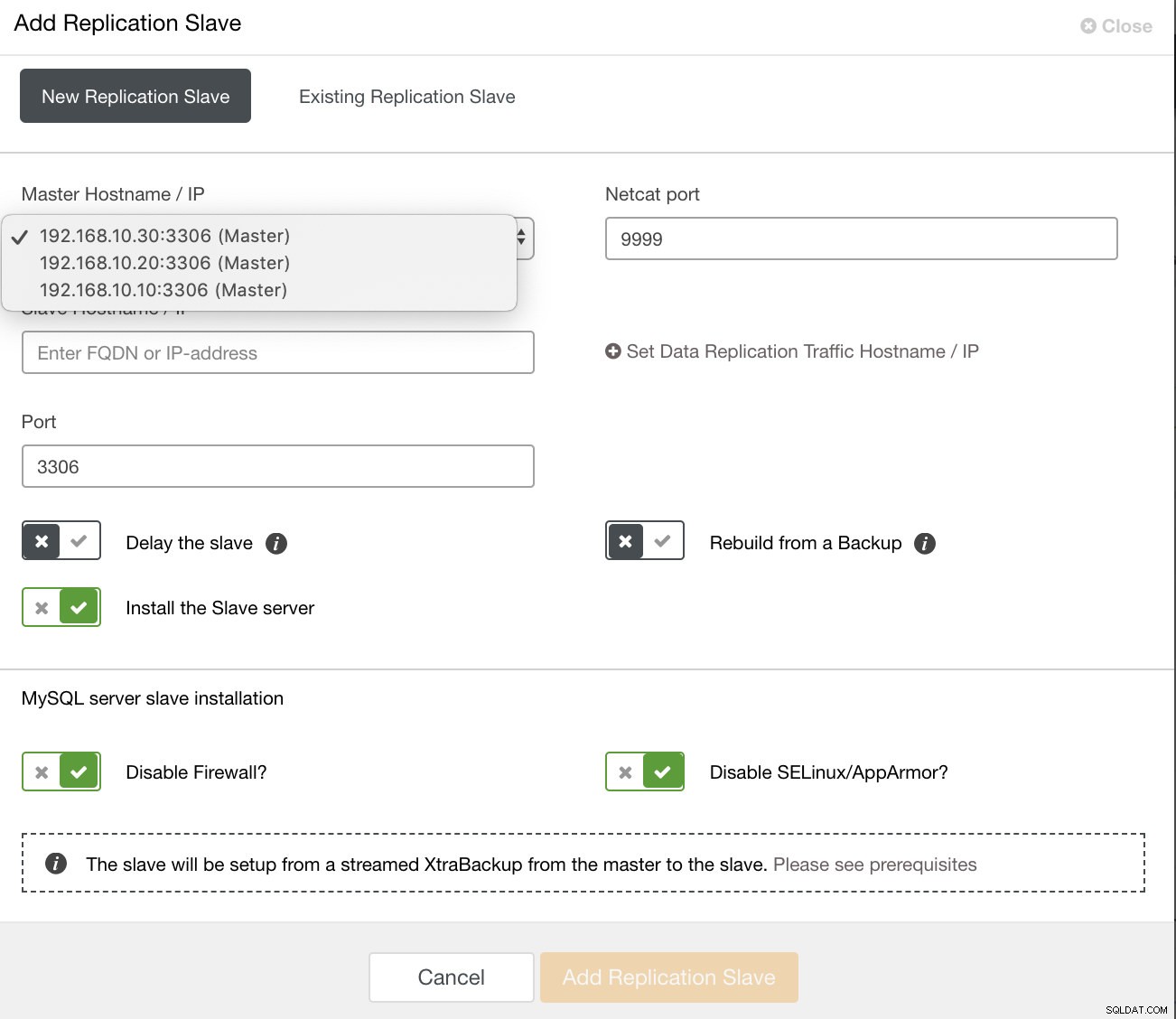
и можете също така да настроите съществуващ подчинен за репликация,
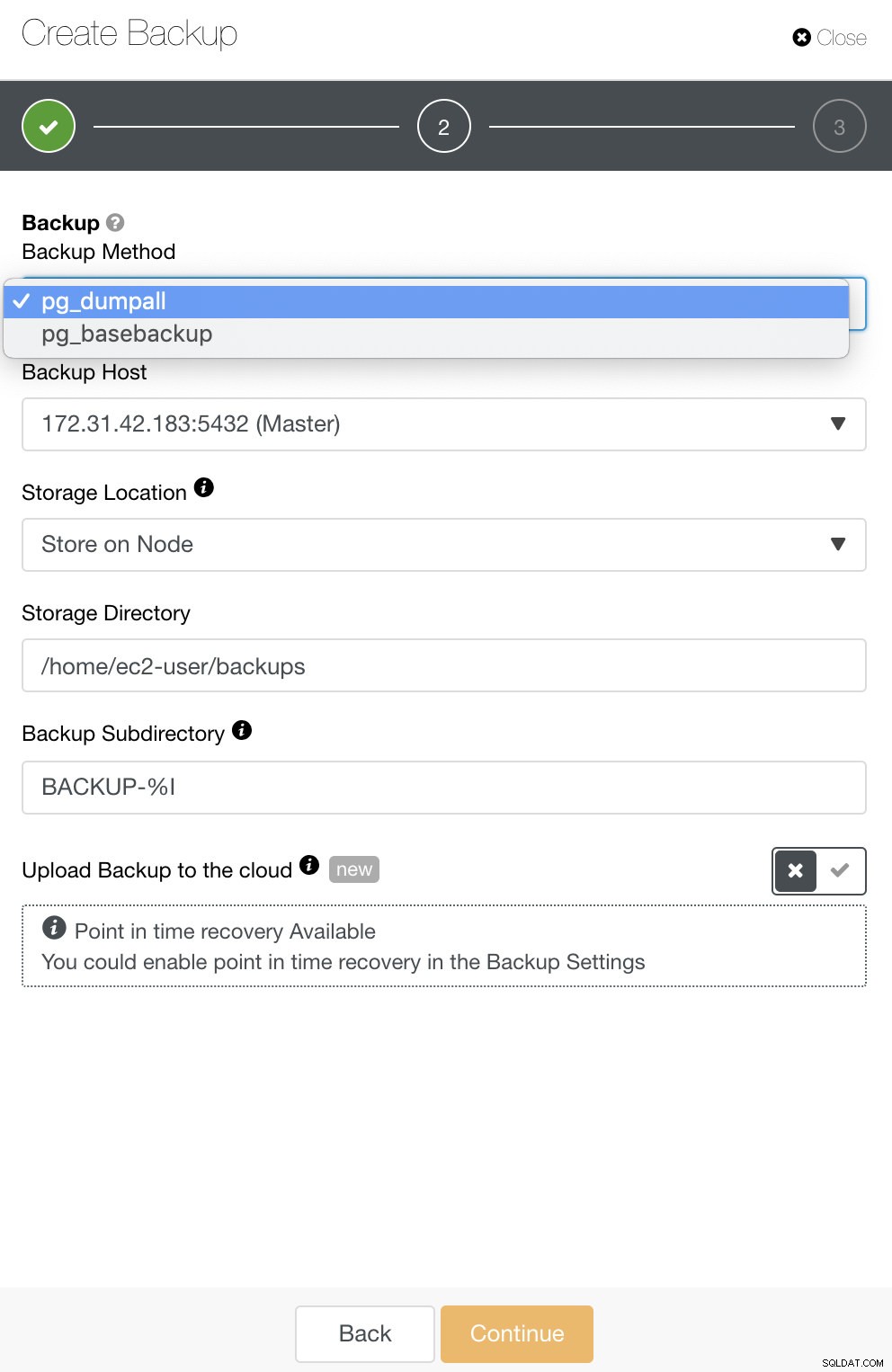
За PostgreSQL имате опции за архивиране на логически или физически архиви. В ClusterControl можете да използвате вашите резервни копия на PostgreSQL, като изберете pg_dump или pg_basebackup. pg_basebackup няма да работи за версии, по-стари от 9.3.
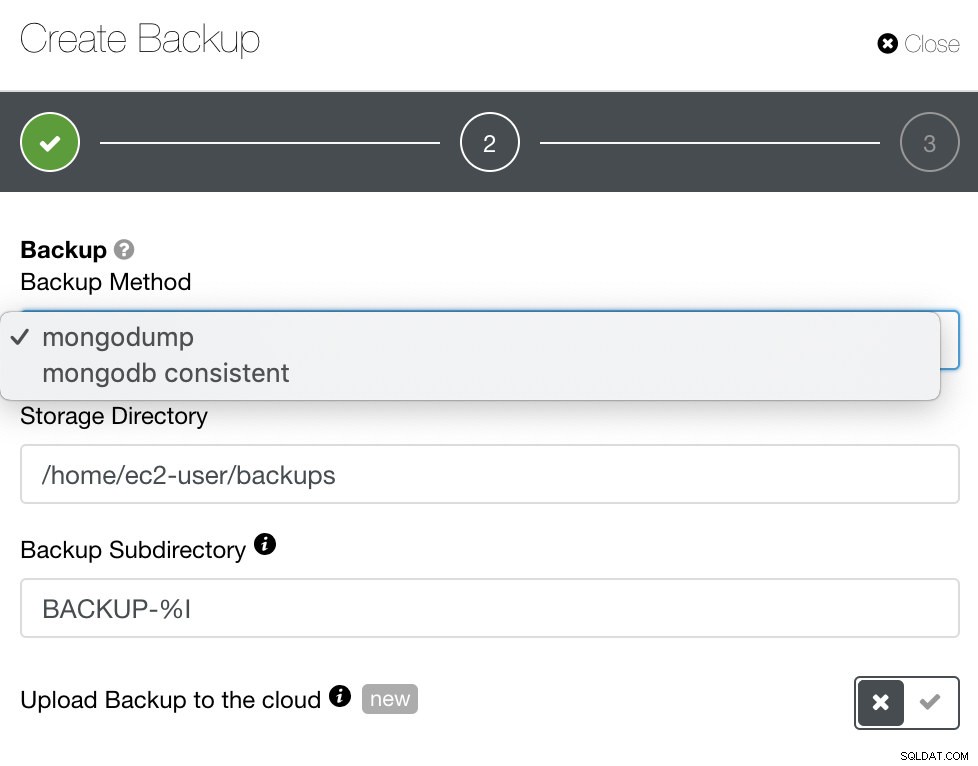
За MongoDB, ClusterControl предлага mongodump или mongodb последователен. Може да се наложи да вземете под внимание, че mongodb Consistent не поддържа RHEL 7, но може да успеете да го инсталирате ръчно.
По подразбиране ClusterControl ще изброи отчет за всички направени архиви, успешни или неуспешни. Вижте по-долу:
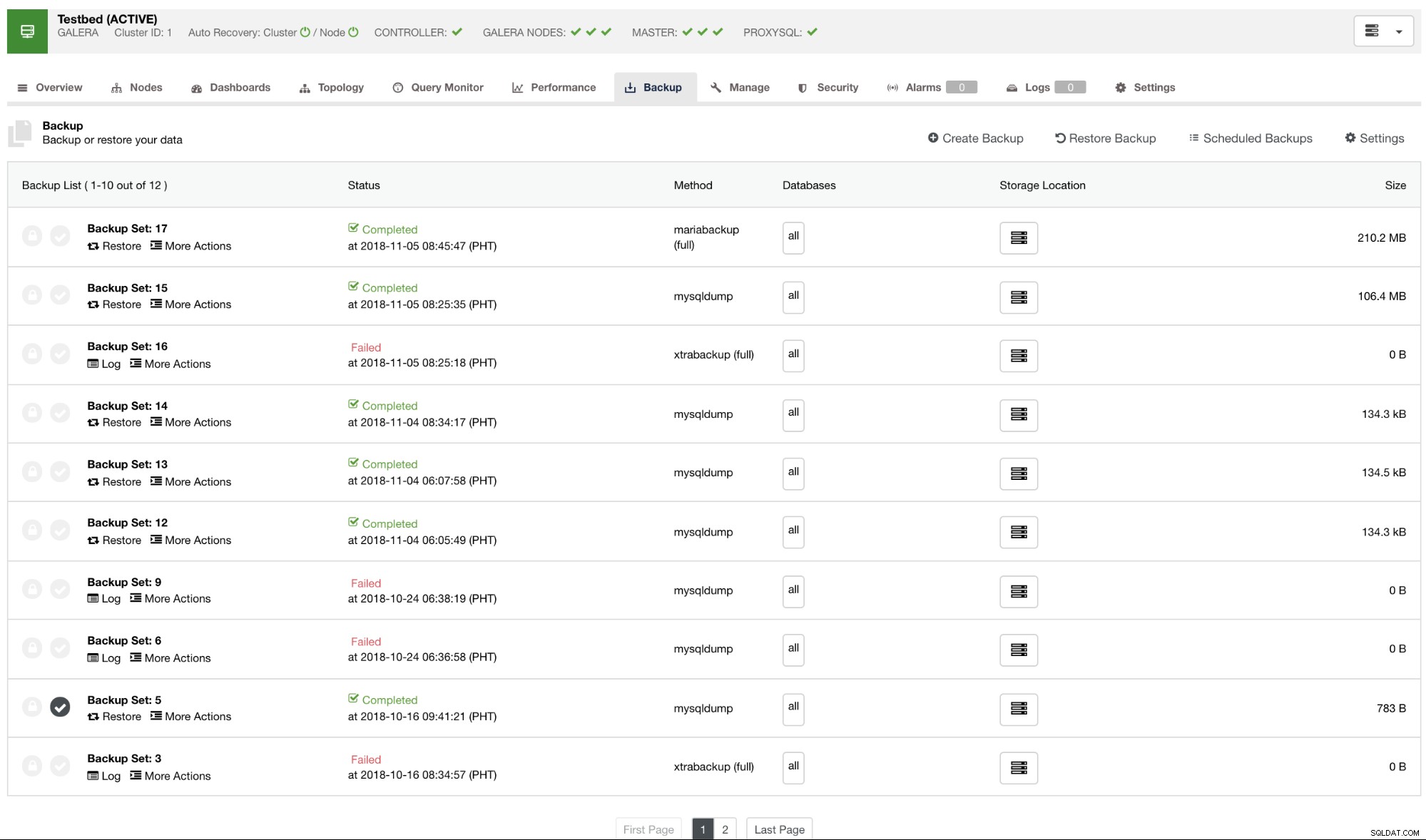
Можете да проверите в списъка с архивни отчети, които са създадени или планирани с помощта на ClusterControl. В списъка можете да видите регистрационните файлове за по-нататъшно изследване и диагностика. Например, ако архивирането завърши правилно според желаната от вас политика за архивиране, независимо дали компресията и криптирането са зададени правилно, или ако желаният размер на архивните данни е правилен. Това е добър начин да направите бърза проверка на здравия разум – ако вашият набор от данни е с размер около 1 GB, няма начин пълното архивиране да бъде само 100 KB – нещо трябва да се е объркало в даден момент.
Възстановяване след бедствие
Съхраняването на резервни копия в клъстера (или директно на възел на база данни или на хоста на ClusterControl) е полезно, когато искате бързо да възстановите данните си:всички архивни файлове са на място и могат да бъдат декомпресирани и възстановени незабавно. Когато става въпрос за възстановяване след бедствие (DR), това може да не е най-добрият вариант. Може да се случат различни проблеми - сървърите може да се сринат, мрежата може да не работи надеждно, дори цели центрове за данни може да не са достъпни поради някакъв вид прекъсване. Това може да се случи независимо дали работите с по-малък доставчик на услуги с един център за данни или глобален доставчик като Amazon Web Services. Поради това не е безопасно да съхранявате всичките си яйца в една кошница - трябва да се уверите, че имате копие на резервното си копие, съхранявано на някакво външно място. ClusterControl поддържа Amazon S3, Google Storage и Azure Cloud Storage.
За тези, които биха искали да прилагат свои собствени DR политики, архивите на ClusterControl се съхраняват в добре структурирана директория. Освен това имате възможност да качите резервното си копие в облака. Вижте изображението по-долу:
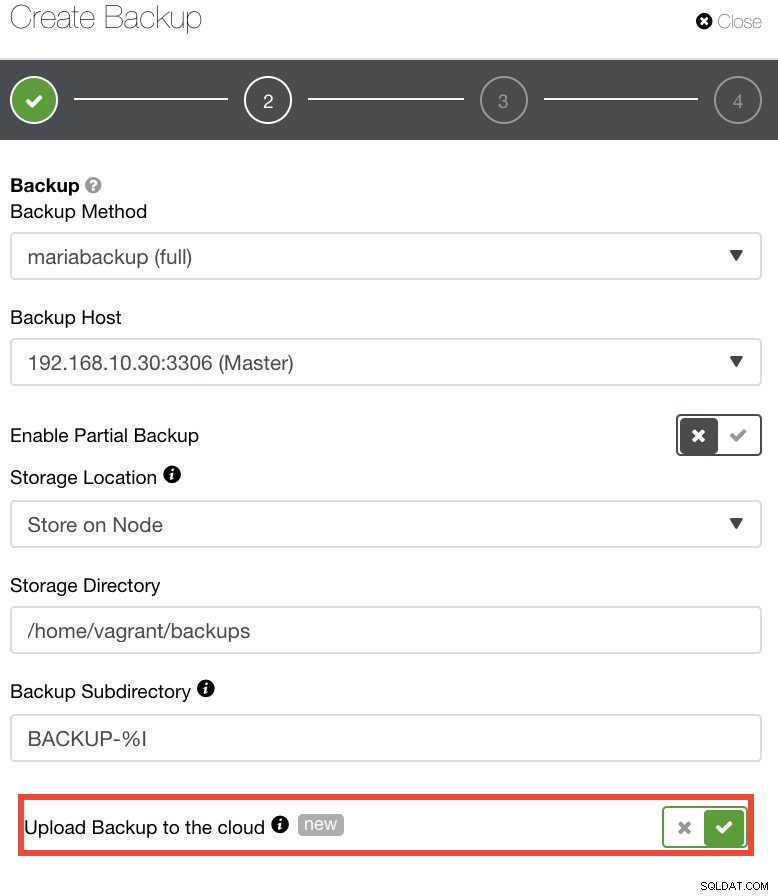
Можете да избирате и качвате в Amazon Web Services, Google Cloud и Microsoft Azure. Вижте изображението по-долу:
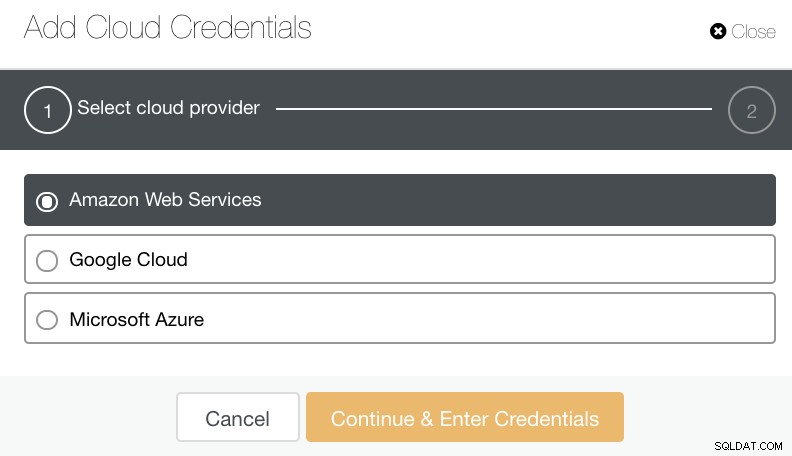
Като добра практика при архивиране на резервни копия на базата данни, уверете се, че вашата целева облачна дестинация е базирана на същия регион като сървърите на бази данни или поне най-близкия. Уверете се, че предлага висока наличност, издръжливост и мащабируемост; тъй като трябва да прецените колко често и незабавно имате нужда от вашите данни.
В допълнение към създаването на логическо или физическо резервно копие за вашия DR, създаването на пълна моментна снимка на вашите данни (например с помощта на LVM Snapshot, Amazon EBS Snapshots или Volume Snapshots, ако използвате файлова система Veritas) на конкретния възел може да увеличи възстановяването на резервното ви копие. Можете също да използвате WAL (за Postgres) за вашето Point In Time Recovery (PITR) или вашите MySQL двоични регистрационни файлове за вашия PITR. По този начин трябва да имате предвид, че може да се наложи да създадете свой собствен архив за вашия PITR. Така че е напълно добре да създадете и внедрите свой собствен набор от скриптове и да обработвате DR според точните си изисквания.
Друг чудесен начин за внедряване на политика за възстановяване след бедствие е използването на подчинен асинхронен репликация – нещо, което споменахме по-рано в тази публикация в блога. Можете да разположите такъв асинхронен подчинен на отдалечено място, може би някой друг център за данни, и след това да го използвате, за да правите резервни копия и да ги съхранявате локално на това подчинено устройство. Разбира се, бихте искали да вземете локално резервно копие на вашия клъстер, за да го имате локално, ако трябва да възстановите клъстера. Преместването на данни между центровете за данни може да отнеме много време, така че наличието на локални архивни файлове може да ви спести известно време. В случай, че загубите достъпа до основния си производствен клъстер, все още може да имате достъп до подчинения. Тази настройка е много гъвкава - първо, имате работещ MySQL хост с вашите производствени данни, така че не би трябвало да е твърде трудно да разположите пълното си приложение в сайта на DR. Освен това ще имате резервни копия на производствените си данни, които бихте могли да използвате, за да разширите своята среда за DR.
И накрая и най-важното, резервно копие, което не е тествано, остава непроверено архивиране, известно още като Schroedinger Backup. За да сте сигурни, че имате работещ архив, трябва да извършите тест за възстановяване. ClusterControl предлага начин за автоматично потвърждаване и тестване на вашия архив.
Надяваме се, че това ви дава достатъчно информация, за да изградите безопасна и надеждна процедура за архивиране на вашите бази данни с отворен код.



