Автоматичното преминаване при отказ за MySQL репликация е предмет на дебат от много години.
Дали е нещо добро или лошо?
За тези с дълга памет в света на MySQL, те може да си спомнят прекъсването на GitHub през 2012 г., което беше основно причинено от софтуера, който взе грешни решения.
Тогава GitHub току-що мигрира към комбинация от MySQL Replication, Corosync, Pacemaker и Percona Replication Manager. PRM реши да направи отказ след неуспешни проверки на здравето на главния, който беше претоварен по време на миграция на схема. Избран е нов мастер, но той се представя лошо поради студени кешове. Високото натоварване на заявките от натоварения сайт доведе до повторен отказ на PRM сърдечните удари на студения главен код и PRM след това задейства друго превключване към оригиналния главен обект. И проблемите просто продължиха, както е обобщено по-долу.
 Източник:Хенрик Инго и Масимо Бриньоли на Percona Live 2013
Източник:Хенрик Инго и Масимо Бриньоли на Percona Live 2013 Превъртете напред няколко години и GitHub се завърна с доста сложна рамка за управление на MySQL репликация и автоматизиран отказ! Както го казва Шломи Ноач:
„За тази цел ние използваме автоматизирани главни откази. Времето, което ще отнеме на човек, за да се събуди и да поправи неуспешен главен код, е извън нашите очаквания за наличност, а оперирането на такъв отказ понякога е нетривиално. Очакваме главните грешки да бъдат автоматично открити и възстановени в рамките на 30 секунди или по-малко и очакваме преминаването при отказ да доведе до минимална загуба на налични хостове.“
Повечето компании не са GitHub, но може да се твърди, че никоя компания не обича прекъсвания. Прекъсванията са разрушителни за всеки бизнес и също струват пари. Предполагам, че повечето компании там вероятно биха искали да имат някакъв вид автоматизирано отказване и причините да не го внедрят вероятно са сложността на съществуващите решения, липсата на компетентност при внедряването на такива решения или липсата на доверие в софтуера, който да вземе. толкова важно решение.
Има редица автоматизирани решения за отказване, включително (и не само) MHA, MMM, MRM, mysqlfailover, Orchestrator и ClusterControl. Някои от тях са на пазара от няколко години, други са по-нови. Това е добър знак, множество решения означават, че пазарът е налице и хората се опитват да се справят с проблема.
Когато проектирахме автоматично преминаване при отказ в ClusterControl, използвахме няколко ръководни принципа:
-
Уверете се, че главният е наистина мъртъв, преди да преминете при отказ
В случай на мрежов дял, при който софтуерът за отказване губи връзка с главната, той ще спре да го вижда. Но главният може да работи добре и може да се види от останалата част от топологията на репликация.
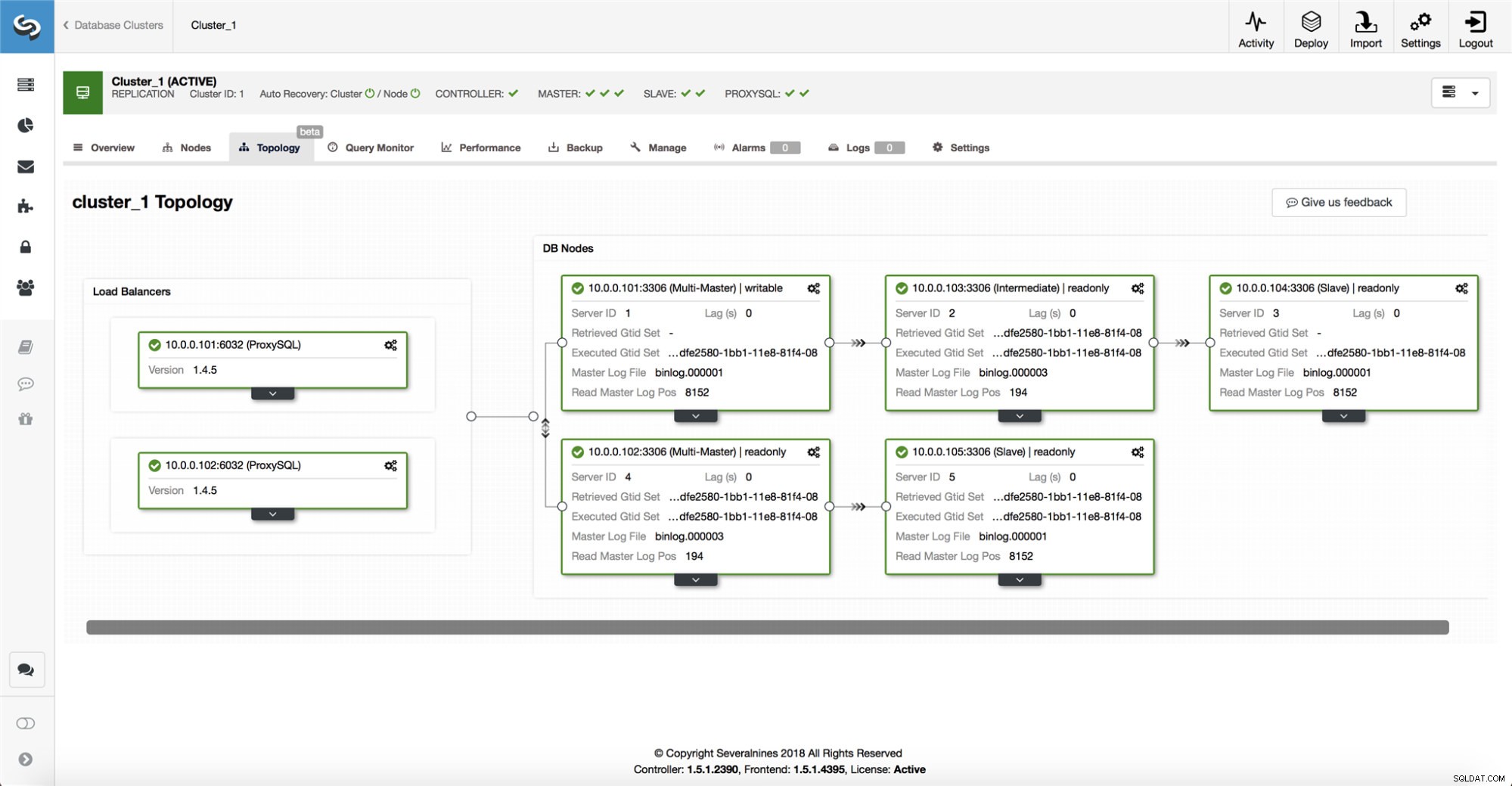
ClusterControl събира информация от всички възли на базата данни, както и от всички използвани прокси сървъри/балансери на натоварването на базата данни и след това изгражда представяне на топологията. Няма да прави опит за преодоляване на срив, ако подчинените могат да видят главния, нито ако ClusterControl не е 100% сигурен за състоянието на главния.
ClusterControl също така улеснява визуализирането на топологията на настройката, както и състоянието на различните възли (това е разбирането на ClusterControl за състоянието на системата, въз основа на информацията, която събира).
-
Отказ само веднъж
Много е писано за пляскането. Може да стане много объркано, ако инструментът за наличност реши да извърши множество откази. Това е опасна ситуация. Всеки избран главен, колкото и кратък да е периода, в който е изпълнявал ролята на главен, може да има свои собствени набори от промени, които никога не са били репликирани на нито един сървър. Така че може да се стигне до несъответствие между всички избрани господари.
-
Не прехвърляйте при отказ към непоследователно подчинено устройство
Когато избираме подчинен, който да бъде повишен като главен, ние гарантираме, че робът няма несъответствия, напр. грешни транзакции, тъй като това може да наруши репликацията.
-
Пишете само на майстора
Репликацията отива от главен към подчинен(и). Писането директно на подчинен би създало различен набор от данни и това може да бъде потенциален източник на проблем. Зададохме подчинените на read_only и super_read_only в по-новите версии на MySQL или MariaDB. Също така препоръчваме използването на балансьор на натоварване, например ProxySQL или MaxScale, за да защити слоя на приложението от основната топология на базата данни и всякакви промени в нея. Балансирането на натоварването също така налага запис върху текущото главно устройство.
-
Не възстановявайте автоматично неуспешния главен код
Ако главният е неуспешен и е избран нов главен, ClusterControl няма да се опитва да възстанови неуспешния главен. Защо? Този сървър може да има данни, които все още не са репликирани, и администраторът ще трябва да направи известно проучване на грешката. Добре, все още можете да конфигурирате ClusterControl да изтрие данните на неуспешния главен обект и да го накара да се присъедини като подчинен към новия главен - ако сте наред със загубата на някои данни. Но по подразбиране ClusterControl ще остави неуспешния главен обект, докато някой го погледне и реши да го въведе отново в топологията.
И така, трябва ли да автоматизирате отказването? Зависи как сте конфигурирали репликацията. Настройките за кръгова репликация с множество глави с възможност за запис или сложни топологии вероятно не са добри кандидати за автоматично преминаване при отказ. Ще се придържаме към горните принципи, когато проектираме решение за репликация.
На PostgreSQL
Когато става въпрос за поточно репликация на PostgreSQL, ClusterControl използва подобни принципи за автоматизиране на отказ. За PostgreSQL ClusterControl поддържа както асинхронни, така и синхронни модели на репликация между главния и подчинените. И в двата случая, и в случай на повреда, подчинения с най-актуални данни се избира за нов главен. Неуспешните главни не се възстановяват/поправят автоматично, за да се присъединят отново към настройката за репликация.
Взети са няколко защитни мерки, за да се уверите, че неуспешният главен уред не работи и остава надолу, напр. премахва се от заложеното за балансиране на натоварването в проксито и се убива, ако напр. потребителят ще го рестартира ръчно. Там е малко по-предизвикателно да се открият мрежови разделения между ClusterControl и главния, тъй като подчинените не предоставят никаква информация за състоянието на главната, от която се репликират. Така че проксито пред настройката на базата данни е важно, тъй като може да осигури друг път към главния.
На MongoDB
Репликацията на MongoDB в репликация чрез oplog е много подобна на репликацията на binlog, така че как така MongoDB автоматично възстановява неуспешен главен файл? Проблемът все още е налице и MongoDB се справя с него, като отменя всички промени, които не са били репликирани на подчинените в момента на повреда. Тези данни се премахват и се поставят в папка за връщане назад, така че администраторът трябва да ги възстанови.
За да научите повече, вижте ClusterControl; и не се колебайте да коментирате или да задавате въпроси по-долу.



