Поддръжката е нещо, което оперативният екип не може да избегне. Сървърите трябва да бъдат в крак с най-новия софтуер, хардуер и технология, за да гарантират, че системите са стабилни и работят с възможно най-нисък риск, като същевременно използват по-нови функции за подобряване на цялостната производителност.
Несъмнено има дълъг списък от задачи за поддръжка, които трябва да се изпълняват от системните администратори, особено когато става въпрос за критични системи. Някои от задачите трябва да се изпълняват на редовни интервали, като ежедневно, седмично, месечно и годишно. Някои трябва да се направят веднага, спешно. Независимо от това, всяка операция по поддръжката не трябва да води до друг по-голям проблем и всяка поддръжка трябва да се третира с повишено внимание, за да се избегне прекъсване на бизнеса.
Получаването на съмнително състояние и фалшиви аларми е често срещано явление, докато поддръжката е в ход. Това се очаква, защото по време на периода на поддръжка сървърът няма да работи както трябва, докато задачата за поддръжка не бъде завършена. ClusterControl, всеобхватната платформа за управление и наблюдение за вашите бази данни с отворен код, може да бъде конфигурирана, за да разбере тези обстоятелства, за да опрости вашите рутини за поддръжка, без да жертвате функциите за наблюдение и автоматизация, които предлага.
Режим на поддръжка
ClusterControl въведе режим на поддръжка във версия 1.4.0, където можете да поставите отделен възел в поддръжка, което не позволява на ClusterControl да вдига аларми и да изпраща известия за определена продължителност. Режимът на поддръжка може да бъде конфигуриран от потребителския интерфейс на ClusterControl, а също и чрез инструмента ClusterControl CLI, наречен "s9s". От потребителския интерфейс просто отидете на Nodes -> изберете възел -> Node Actions -> Schedule Maintenance Mode :
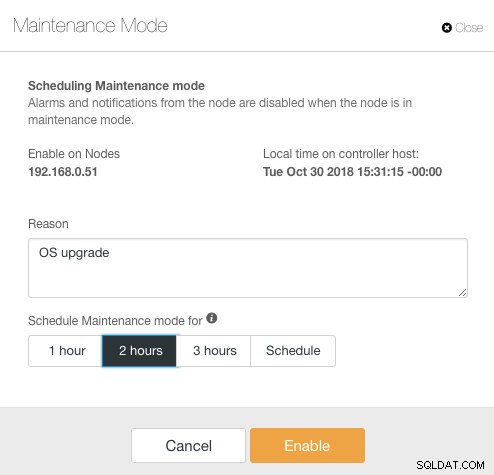
Тук можете да зададете периода на поддръжка за предварително определено време или да го планирате съответно. Можете също да запишете причината за планирането на надстройката, полезно за целите на одита. Трябва да видите следното известие, когато режимът на поддръжка е активен:
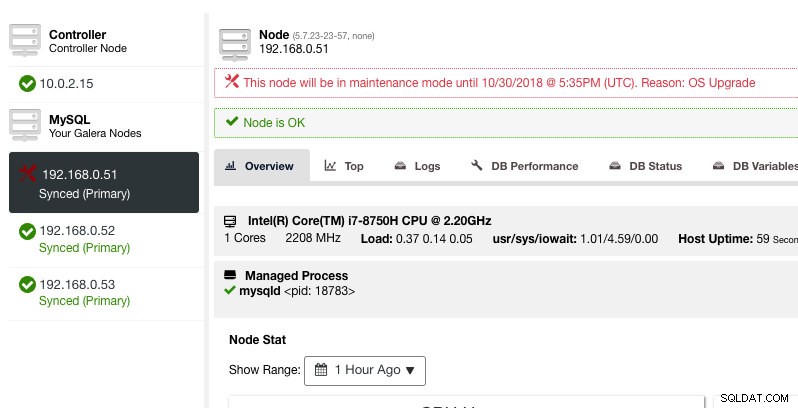
ClusterControl няма да влоши възела, следователно състоянието на възела остава както е, освен ако не извършите каквото и да е действие, което променя състоянието. Алармите и известията за този възел ще бъдат активирани повторно, след като периодът на поддръжка приключи или операторът изрично го деактивира, като отиде на Действия на възел -> Деактивиране на режима на поддръжка .
Обърнете внимание, че ако автоматичното възстановяване на възел е активирано, ClusterControl винаги ще възстанови възел, независимо от състоянието на режима на поддръжка. Не забравяйте да деактивирате възстановяването на възел, за да избегнете намесата на ClusterControl в задачите ви за поддръжка, това може да стане от горната лента за обобщение.
Режимът на поддръжка може също да бъде конфигуриран чрез ClusterControl CLI или "s9s". Можете да използвате командата "s9s support", за да изброите и манипулирате периодите на поддръжка. Следният команден ред планира едночасов прозорец за поддръжка за възел 192.168.1.121 утре:
$ s9s maintenance --create \
--nodes=192.168.1.121 \
--start="$(date -d 'now + 1 day' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 1 day + 1 hour' '+%Y-%m-%d %H:%M:%S')" \
--reason="Upgrading software."За повече подробности и примери вижте документацията за поддръжка на s9s.
Режим на поддръжка за целия клъстер
Към момента на това писане конфигурацията на режима на поддръжка трябва да бъде конфигурирана за управляван възел. За поддръжка в целия клъстер трябва да се повтори процеса на планиране за всеки управляван възел на клъстера. Това може да е непрактично, ако имате голям брой възли във вашия клъстер или ако интервалът за поддръжка е много кратък между две задачи.
За щастие ClusterControl CLI (известен още като s9s) може да се използва като заобиколно решение за преодоляване на това ограничение. Можете да използвате "s9s възли", за да изброите и манипулирате управляваните възли в клъстер. Този списък може да бъде повторен, за да се планира режим на поддръжка в целия клъстер в даден момент с помощта на командата „s9s support“.
Нека разгледаме пример, за да разберем това по-добре. Помислете за следния Percona XtraDB клъстер с три възли, който имаме:
$ s9s nodes --list --cluster-name='PXC57' --long
STAT VERSION CID CLUSTER HOST PORT COMMENT
coC- 1.7.0.2832 1 PXC57 10.0.2.15 9500 Up and running.
go-M 5.7.23 1 PXC57 192.168.0.51 3306 Up and running.
go-- 5.7.23 1 PXC57 192.168.0.52 3306 Up and running.
go-- 5.7.23 1 PXC57 192.168.0.53 3306 Up and running.
Total: 4Клъстерът има общо 4 възела - 3 възела на база данни с един възел ClusterControl. Първата колона, STAT, показва ролята и състоянието на възела. Първият знак е ролята на възела - "c" означава контролер, а "g" означава възел на базата данни Galera. Да предположим, че искаме да планираме само възлите на базата данни за поддръжка, можем да филтрираме изхода, за да получим името на хоста или IP адреса, където отчетеният STAT има "g" в началото:
$ s9s nodes --list --cluster-name='PXC57' --long --batch | grep ^g | awk {'print $5'}
192.168.0.51
192.168.0.52
192.168.0.53С проста итерация можем да планираме прозорец за поддръжка в целия клъстер за всеки възел в клъстера. Следната команда повтаря създаването на поддръжка въз основа на всички IP адреси, намерени в клъстера, като използва цикъл for, където планираме да започнем операцията по поддръжка по същото време утре и да завършим един час по-късно:
$ for host in $(s9s nodes --list --cluster-id='PXC57' --long --batch | grep ^g | awk {'print $5'}); do \
s9s maintenance \
--create \
--nodes=$host \
--start="$(date -d 'now + 1 day' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 1 day + 1 hour' '+%Y-%m-%d %H:%M:%S')" \
--reason="OS upgrade"; done
f92c5370-004d-4735-bba0-8c1bd26b9b98
9ff7dd8c-f2cb-4446-b14b-a5c2b915b853
103d715d-d0bc-4402-9326-1a053bc5d36bТрябва да видите разпечатка на 3 UUID, уникалния низ, който идентифицира всеки период на поддръжка. След това можем да проверим със следната команда:
$ s9s maintenance --list --long
ST UUID OWNER GROUP START END HOST/CLUSTER REASON
-h f92c537 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.51 OS upgrade
-h 9ff7dd8 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.52 OS upgrade
-h 103d715 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.53 OS upgrade
Total: 3От горния изход получихме списък с планираните времена за поддръжка за всеки възел на базата данни. По време на насроченото време ClusterControl няма нито да вдига аларми, нито да изпраща известия, ако открие нередности в клъстера.
Итерация в режим на поддръжка
Някои процедури за поддръжка трябва да се извършват на редовен интервал, например архивиране, домакински задачи и задачи за почистване. По време на времето за поддръжка бихме очаквали сървърът да се държи по различен начин. Въпреки това, всяка неизправност в услугата, временна недостъпност или голямо натоварване със сигурност биха причинили хаос в нашата система за наблюдение. За периоди за поддръжка с чести и кратки интервали това може да се окаже много досадно и пропускането на повдигнатите фалшиви аларми може да ви осигури по-добър сън през нощта.
Въпреки това, разрешаването на режим на поддръжка може също да изложи сървъра на по-голям риск, тъй като стриктното наблюдение се игнорира за определен период от време. Следователно вероятно е добра идея да разберем естеството на операцията по поддръжка, която бихме искали да извършим, преди да активираме режима на поддръжка. Следният контролен списък трябва да ни помогне да определим нашата политика за режим на поддръжка:
- Засегнати възли – Кои възли участват в поддръжката?
- Последици – Какво се случва с възела, когато операцията по поддръжката е в ход? Ще бъде ли недостъпен, високо натоварен или рестартиран?
- Продължителност – Колко време отнема операцията по поддръжка, за да завърши?
- Честота – Колко често трябва да се извършва операцията по поддръжка?
Нека го поставим в случай на употреба. Помислете, че имаме клъстер Percona XtraDB с три възела с възел ClusterControl. Да предположим, че всички наши сървъри работят на виртуални машини и политиката за архивиране на VM изисква всички виртуални машини да бъдат архивирани всеки ден, започвайки от 1:00 часа сутринта, един възел в даден момент. По време на тази операция за архивиране, възелът ще бъде замразен за около 10 минути максимум и възелът, който се управлява и наблюдава от ClusterControl, ще бъде недостъпен, докато архивирането приключи. От гледна точка на Galera Cluster, тази операция не сваля целия клъстер, тъй като клъстерът остава в кворум и основният компонент не е засегнат.
Въз основа на естеството на задачата за поддръжка можем да я обобщим по следния начин:
- Засегнати възли – Всички възли за клъстер ID 1 (3 възела на база данни и 1 възел ClusterControl).
- Последствие – Виртуалната машина, която се архивира, ще бъде недостъпна до завършване.
- Продължителност – Всяка операция за архивиране на VM отнема около 5 до 10 минути, за да завърши.
- Честота – Архивирането на VM е планирано да се изпълнява ежедневно, като се започне от 1:00 часа сутринта на първия възел.
След това можем да излезем с план за изпълнение, за да планираме нашия режим на поддръжка:
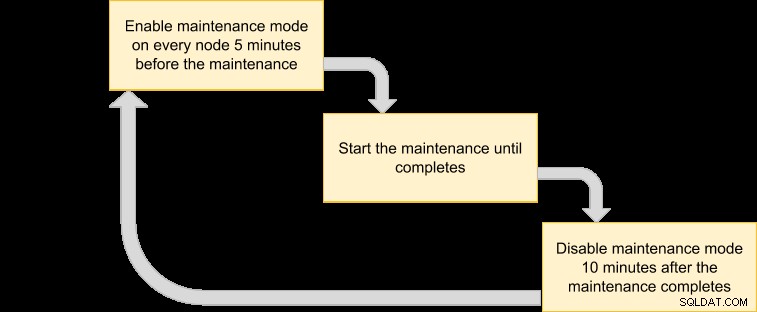
Тъй като искаме всички възли в клъстера да бъдат архивирани от мениджъра на VM, просто избройте възлите за съответния ID на клъстер:
$ s9s nodes --list --cluster-id=1
192.168.0.51 10.0.2.15 192.168.0.52 192.168.0.53Горният изход може да се използва за планиране на поддръжка в целия клъстер. Например, ако изпълните следната команда, ClusterControl ще активира режима на поддръжка за всички възли под идентификатор на клъстер 1 от сега до следващите 50 минути:
$ for host in $(s9s nodes --list --cluster-id=1); do \
s9s maintenance --create \
--nodes=$host \
--start="$(date -d 'now' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 50 minutes' '+%Y-%m-%d %H:%M:%S')" \
--reason="Backup VM"; doneИзползвайки горната команда, можем да я преобразуваме в изпълнителен файл, като го поставим в скрипт. Създайте файл:
$ vim /usr/local/bin/enable_maintenance_modeИ добавете следните редове:
for host in $(s9s nodes --list --cluster-id=1)
do \
s9s maintenance \
--create \
--nodes=$host \
--start="$(date -d 'now' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 50 minutes' '+%Y-%m-%d %H:%M:%S')" \
--reason="VM Backup"
doneЗапазете го и се уверете, че разрешението за файл е изпълнимо:
$ chmod 755 /usr/local/bin/enable_maintenance_modeСлед това използвайте cron, за да планирате скрипта да се изпълнява от 5 минути до 1:00 сутринта всеки ден, точно преди операцията за архивиране на VM да започне в 1:00 часа:
$ crontab -e
55 0 * * * /usr/local/bin/enable_maintenance_modeПрезаредете демона cron, за да се уверите, че нашият скрипт е поставен на опашка:
$ systemctl reload crond # or service crond reloadТова е. Вече можем да извършваме ежедневната си операция по поддръжка, без да ни подслушват фалшиви аларми и известия по пощата, докато поддръжката приключи.
Функция за бонусна поддръжка - Пропускане на възстановяване на възел
С активирано автоматично възстановяване, ClusterControl е достатъчно интелигентен, за да открие повреда на възел и ще се опита да възстанови неуспешен възел след 30-секунден гратисен период, независимо от състоянието на режима на поддръжка. Знаете ли, че ClusterControl може да бъде конфигуриран така, че умишлено да пропуска възстановяването на възел за конкретен възел? Това може да бъде много полезно, когато трябва да извършите спешна поддръжка, без да знаете срока и резултата от поддръжката.
Например, представете си, че се е случило повреда на файловата система и се изисква проверка и ремонт на файловата система след твърдо рестартиране. Трудно е да се определи предварително колко време ще е необходимо, за да завърши тази операция. По този начин можем просто да използваме файл с флаг, за да сигнализираме на ClusterControl да пропусне възстановяването за възела.
Първо, добавете следния ред вътре в /etc/cmon.d/cmon_X.cnf (където X е идентификаторът на клъстера) на възела ClusterControl:
node_recovery_lock_file=/root/do_not_recoverСлед това рестартирайте услугата cmon, за да заредите промяната:
$ systemctl restart cmon # service cmon restartИ накрая, уверете се, че посоченият файл присъства на възела, който искаме да пропуснем за възстановяване на ClusterControl:
$ touch /root/do_not_recoverНезависимо от състоянието на режима на автоматично възстановяване и поддръжка, ClusterControl ще възстанови възела само когато този файл с флаг не съществува. След това администраторът е отговорен да създаде и премахне файла на възела на базата данни.
Това е, хора. Приятна поддръжка!



