Още анализиране на запитването на ключовата популация
В част 3 от нашата серия за проследяване на ODBC ще разгледаме допълнително ключовете за управление на Access за свързани ODBC таблици и как сортира и групира заявките SELECT заедно. В предишната статия научихме как набор от записи от dynaset е всъщност 2 отделни заявки, като първата заявка извлича само ключовете на ODBC свързаната таблица, която впоследствие се използва за попълване на данните. В тази статия ще проучим малко повече за това как Access управлява ключовете и как извежда кой е ключът, който трябва да се използва за ODBC свързана таблица между с разклоненията, които има. Ще започнем със сортирането.
Добавяне на сортиране към заявката
Видяхте в предишната статия, че започнахме с прост SELECT без особена поръчка. Също така видяхте как Access първо извлече CityID и използвайте резултата от първата заявка, за да попълните следващите заявки, за да осигурите на потребителя вид, че сте бързи при отваряне на голям набор от записи. Ако някога сте изпитвали ситуация, при която добавянето на сортиране или групиране към заявка изведнъж се забави, това ще обясни защо.
Нека добавим сортиране в StateProvinceID в заявка за достъп:
SELECT Cities.* FROM Cities ORDER BY Cities.StateProvinceID;Сега, ако проследим ODBC SQL, трябва да видим изхода:
SQLExecDirect: SELECT "Application"."Cities"."CityID" FROM "Application"."Cities" ORDER BY "Application"."Cities"."StateProvinceID" SQLPrepare: SELECT "CityID", "CityName", "StateProvinceID", "Location", "LatestRecordedPopulation", "LastEditedBy", "ValidFrom", "ValidTo" FROM "Application"."Cities" WHERE "CityID" = ? SQLExecute: (GOTO BOOKMARK) SQLPrepare: SELECT "CityID", "CityName", "StateProvinceID", "Location", "LatestRecordedPopulation", "LastEditedBy", "ValidFrom", "ValidTo" FROM "Application"."Cities" WHERE "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? SQLExecute: (MULTI-ROW FETCH) SQLExecute: (MULTI-ROW FETCH)Ако сравните с проследяването от предишната статия, можете да видите, че те са еднакви с изключение на първата заявка. Access поставя сортирането в първата заявка, където използва, за да получи ключовете. Това има смисъл, тъй като чрез налагането на сортирането върху ключовете, които използва, за да премине през записите, Access гарантира, че има съответствие едно към едно между редовната позиция на записа и начина, по който той трябва да бъде сортиран. След това попълва записите по абсолютно същия начин. Единствената разлика е последователността от ключове, които използва за попълване на другите заявки.
Нека разгледаме какво се случва, когато добавим GROUP BY като преброите градовете по щат:
SELECT Cities.StateProvinceID ,Count(Cities.CityID) AS CountOfCityID FROM Cities GROUP BY Cities.StateProvinceID;Проследяването трябва да изведе:
SQLExecDirect:
SELECT
"StateProvinceID"
,COUNT("CityID" )
FROM "Application"."Cities"
GROUP BY "StateProvinceID" Може също да сте забелязали, че заявката сега се отваря бавно и въпреки че може да бъде зададена като набор от записи от dynaset, Access избра да игнорира това и основно да го третира като набор от записи от тип моментна снимка. Това има смисъл, тъй като заявката не може да се актуализира и защото не можете наистина да навигирате до произволна позиция в заявка като тази. По този начин трябва да изчакате, докато всички редове бъдат извлечени, преди да можете свободно да разглеждате. StateProvinceID не може да се използва за намиране на запис, тъй като в Cities ще има няколко записа маса. Въпреки че използвах GROUP BY в този пример не е необходимо да е групиране, което кара Access да използва вместо това набор от записи от тип моментна снимка. Използване на DISTINCT например би имало същия ефект. Полезно практическо правило, за да се предвиди дали Access ще използва набор от записи от тип dynaset, е да се запита дали даден ред в резултантния набор от записи се преобразува обратно в точно един ред в източника на данни ODBC. Ако това не е така, Access ще използва поведението на моментна снимка, дори ако заявката е трябвало да използва dynaset. Следователно, само защото по подразбиране е набор от записи от тип dynaset, това не гарантира, че всъщност ще бъде набор от записи от тип dynaset. Това е просто искане , а не искане.
Определяне на ключа, който да се използва за избор
Може да сте забелязали в предишния проследен SQL както в тази, така и в предишни статии, Access използва CityID като ключ. Тази колона беше извлечена в първата заявка, след което беше използвана в следващите подготвени заявки. Но как Access знае коя колона(и) на свързана таблица трябва да използва? Първата склонност би била да се каже, че проверява за първичен ключ и го използва. Това обаче би било неправилно. Всъщност системата за база данни на Access ще използва SQLStatistics на ODBC функция по време на свързването или повторното свързване на таблицата, за да провери какви индекси са налични. Тази функция ще върне набор от резултати с един ред за всяка колона, участваща в индекс за всички индекси. Този набор от резултати винаги е сортиран и по конвенция винаги ще сортира клъстерирани индекси, хеширани индекси и след това други типове индекси. Във всеки тип индекс индексите ще бъдат сортирани по имената им по азбучен ред. Двигателят на базата данни на Access ще избере първия уникален индекс, който намери, дори ако не е действителният първичен ключ. За да докажем това, ще създадем глупава таблица с някои странни индекси:
CREATE TABLE dbo.SillyTable ( ID int CONSTRAINT PK_SillyTable PRIMARY KEY NONCLUSTERED, OtherStuff int CONSTRAINT UQ_SillyTable_OtherStuff UNIQUE CLUSTERED, SomeValue nvarchar(255) );Ако след това попълним таблицата с някои данни и се свържем с нея в Access и отворим изглед на лист с данни в свързаната таблица, ще видим това в проследен ODBC SQL. За краткост са включени само първите 2 команди.
SQLExecDirect: SELECT "dbo"."SillyTable"."OtherStuff" FROM "dbo"."SillyTable" SQLPrepare: SELECT "ID" ,"OtherStuff" ,"SomeValue" FROM "dbo"."SillyTable" WHERE "OtherStuff" = ?Тъй като
OtherStuff участва в клъстериран индекс, той дойде преди действителния първичен ключ и по този начин беше избран от механизма на базата данни на Access, за да се използва в набор от записи от тип dynaset за избор на отделен ред. Това е също въпреки факта, че името на уникалния клъстериран индекс би дошло след името на първичния индекс. Тактика да се принуди системата за база данни на Access да избере конкретен индекс за таблица би била да се промени нейния тип или да се преименува името, така че да се сортира по азбучен ред в групата на типа индекс. В случая на SQL Server първичните ключове обикновено са клъстерирани и може да има само един клъстериран индекс, така че е щастлива случайност, че обикновено това е правилният индекс, който да използва машината за база данни на Access. Въпреки това, ако базата данни на SQL Server съдържа таблици с неклъстерирани първични ключове и има клъстериран уникален индекс, това може да не е оптималният избор. В случаите, когато изобщо няма клъстерирани индекси, можете да повлияете кои уникални индекси да се използват, като наименувате индекса, така че да се сортира преди други индекси. Това може да бъде полезно с друг софтуер за RDBMS, където създаването на клъстериран индекс за първичен ключ не е практично или възможно. Индекс от страна на достъпа за свързан SQL изглед или таблица без индекси
При свързване към SQL изглед или SQL таблица, която няма дефинирани индекси или първичен ключ, няма да има налични индекси, които да използва машината за база данни на Access. Ако сте използвали мениджър на свързани таблици, за да свържете таблица или SQL изглед без индекси, може да сте виждали диалогов прозорец като този:
 Ако изберем
Ако изберем ID , завършете свързването, отворете свързаната таблица в изглед за проектиране и след това диалоговия прозорец за индекси, трябва да видим това:
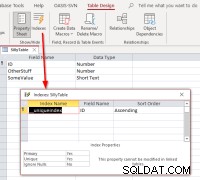 Показва, че таблицата има индекс с име
Показва, че таблицата има индекс с име __uniqueindex но не съществува в оригиналния източник на данни. Какво става? Отговорът е, че Access създаде страна за достъп индекс за използването му, за да помогне да се идентифицира кой може да се използва като идентификатор на запис за такива таблици или изгледи. Ако се случи да свържете отново програмно таблиците, вместо да използвате Мениджъра на свързани таблици, ще намерите за необходимо да репликирате поведението, за да направите такива свързани таблици обновяеми. Това може да стане чрез изпълнение на SQL команда на Access:
CREATE UNIQUE INDEX [__uniqueindex] ON SillyTable (ID);Можете да използвате например
CurrentDb.Execute за да изпълните Access SQL за създаване на индекса на свързаната таблица. Въпреки това, не трябва да го изпълнявате като преходна заявка, тъй като индексът всъщност не е създаден на сървъра. Само предимствата на Access позволяват актуализиране на тази свързана таблица. Струва си да се отбележи, че Access ще позволи само един индекс за такава свързана таблица и само ако тя вече няма индекси. Въпреки това можете да видите, че използването на SQL изглед може да е желана опция в случаите, когато дизайнът на базата данни не ви позволява да използвате клъстерирани индекси и не искате да се занимавате с името на индекса, за да убедите механизма на база данни на Access да използва този индекс, не този индекс. Можете изрично да контролирате индекса и колоните, които трябва да включва, когато свързвате SQL изгледа.
Заключения
От предишната статия видяхме, че набор от записи от dynaset обикновено издава 2 заявки. Първата заявка обикновено се занимава с попълване на Погледнахме по-отблизо как Access обработва популацията от ключове, които ще използва за набор от записи от тип dynaset. Видяхме как Access всъщност ще преобразува всяко сортиране от оригиналната заявка на Access и след това ще го използва в заявката за ключова популация. Видяхме, че подреждането на заявката за ключова популация пряко влияе върху това как данните в набора от записи ще бъдат сортирани и представени на потребителя. Това дава възможност на потребителя да прави неща като прескачане на необичаен запис въз основа на редовната позиция на списъка.
След това видяхме, че групирането и други SQL операции, които предотвратяват съпоставянето едно-единствено между върнатия ред и оригиналния ред, ще накарат Access да третира заявката на Access, сякаш е набор от записи от тип моментна снимка, въпреки че е поискал набор от записи от тип dynaset.
След това разгледахме как Access определя ключа, който да се използва за управление на актуализации с ODBC свързана таблица. Противно на това, което може да очакваме, не е задължително да избере първичния ключ на таблицата, а по-скоро първия уникален индекс, който намира, в зависимост от типа на индекса и името на индекса. Обсъдихме стратегии за гарантиране, че Access ще избере правилния уникален индекс. Разгледахме SQL изглед, който обикновено няма никакви индекси, и обсъдихме метод, чрез който да информираме Access как да ключваме SQL изглед или таблица, която няма първичен ключ, което ни позволява повече контрол върху това как Access ще обработва актуализациите за тези ODBC свързани таблици.
В следващата статия ще разгледаме как Access всъщност изпълнява актуализации на данните, когато потребителите правят промени чрез заявката на Access или източника на запис.
Нашите експерти по достъп са на разположение да помогнат. Обадете ни се на 773-809-5456 или ни пишете на sales@itimpact.com.