Хеш индексите са неразделна част от базите данни. Ако някога сте използвали база данни, има вероятност да сте ги виждали в действие, без дори да го осъзнавате.
Хеш индексите се различават по работа от другите типове индекси, тъй като съхраняват стойности, а не указатели към записи, разположени на диск. Това гарантира по-бързо търсене и вмъкване в индекса. Ето защо хеш индексите често се използват като първични ключове или уникални идентификатори.
Разбиране на хеш индексите
Хеш индексът е тип индекс, който се използва най-често в управлението на данни. Обикновено се създава в колона, която съдържа уникални стойности, като първичен ключ или имейл адрес. Основното предимство от използването на хеш индекси е тяхната бърза производителност.
Концепцията зад тези индекси може да бъде сложна за разбиране за някой, който никога не е чувал за тях преди. Разбирането на хеш индексите обаче е важно, ако трябва да разберете как работят базите данни. Необходим е за решаване на често срещани проблеми, свързани с базите данни и тяхната скорост.
Добрата новина е, че с малко търпение и изключен мобилен телефон можете със сигурност да овладеете хеш индексите! Така че, нека да разгледаме по-добре.
Бързо и лесно
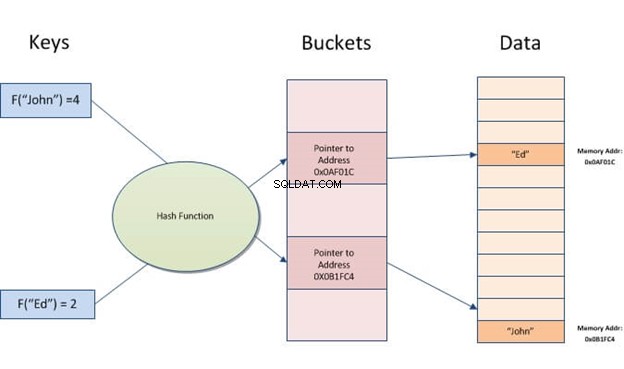
Хеш индексът е структура от данни, която може да се използва за ускоряване на заявките към база данни. Работи чрез преобразуване на входни записи в масив от кофи. Всяка кофа има същия брой записи като всички други кофи в таблицата. По този начин, без значение колко различни стойности имате за конкретна колона, всеки ред винаги ще се съпоставя с една кофа.
Хеш индексите позволяват бързо търсене на данни, съхранявани в таблици. Те работят, като създават индексен ключ от стойността и след това го намират въз основа на получения хеш. Полезно е, когато има много входни данни с подобни стойности или дубликати, тъй като трябва само да сравнява ключове, вместо да преглежда всички записи.
Не беше ли това нито бързо, нито лесно? За да разберете как работят хеш индексите и защо са толкова мощни, трябва да разберете какво се има предвид под хеширане.
Хеширане взема част от информация (низ) и я превръща в адрес или указател за бърз достъп по-късно.
Идеята с хеширането е, че данните получават малко число. Когато търсите данните, не е нужно всъщност да пресявате маси. Вместо това просто потърсете този номер. Най-простият пример е Ctrl+F-извеждане на думата, която търсите в текст, вместо да четете сами десетки страници.
За какво са хеш индексите?
Хеш индексът е начин за ускоряване на процеса на търсене. С традиционните индекси трябва да сканирате всеки ред, за да сте сигурни, че вашата заявка е успешна. Но с хеш индексите това не е така!
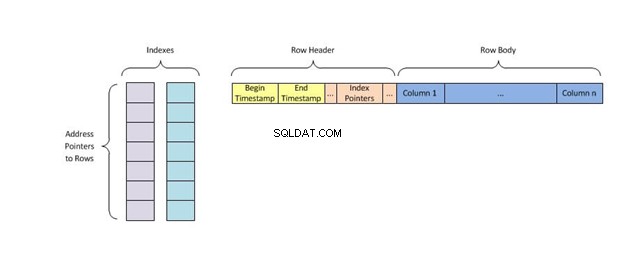
Всеки ключ на индекса съдържа само един ред от данните в таблицата и използва алгоритъма за индексиране, наречен хеширане което им присвоява уникално местоположение в паметта, елиминирайки всички други ключове с дублиращи се стойности, преди да намери това, което търси.
Хеш индексите са един от многото начини за организиране на данни в база данни. Те работят, като приемат вход и го използват като ключ за съхранение на диск. Тези ключове или хеш стойности , може да бъде всичко от дължини на низове до знаци във входа.
Хеш индексите се използват най-често при запитване на конкретни входни данни със специфични атрибути. Например, може да намери всички букви А, които са по-високи от 10 см. Можете да го направите бързо, като създадете функция за хеш индекс.
Хеш индексите са част от системата на базата данни PostgreSQL. Тази система е разработена за увеличаване на скоростта и производителността. Хеш индексите могат да се използват във връзка с други типове индекси, като B-tree или GiST.
Хеш индексът съхранява ключове, като ги разделя на по-малки парчета, наречени кофи, където на всяка кофа се дава целочислен идентификационен номер, за да се извлече бързо при търсене на местоположението на ключа в хеш таблицата. Кофите се съхраняват последователно на диск, така че данните, които съдържат, могат да бъдат бързо достъпни.
Още технически обяснения можете да намерите на тази страница (щракнете с десния бутон на мишката и изберете „Превод на английски“).
Предимства
Основното предимство на използването на хеш индекси е, че те позволяват бърз достъп при извличане на записа по ключовата стойност. Често е полезно за заявки с условие за равенство. Освен това използването на хеш бенчмаркове няма да изисква много място за съхранение. По този начин това е ефективен инструмент, но не и без недостатъци.
Недостатъци
Хеш индексите са сравнително нова структура за индексиране с потенциал да предоставят значителни ползи за производителността. Можете да ги мислите като разширение на двоични дървета за търсене (BST).
Хеш индексите работят, като съхраняват данни в кофи въз основа на техните хеш стойности, което позволява бързо и ефективно извличане на данните. Гарантирано са изрядни.
Въпреки това, не е възможно да се съхраняват дублирани ключове в рамките на кофа. Следователно винаги ще има режийни разходи. Но засега предимствата на използването на хеш индекси са повече от минусите.
Как работи всичко това малко по-задълбочено?
Нека направим демонстрация на aviasales база данни, за да получите по-задълбочено разбиране за това как работят хеш индексите.
demo=# create index on flights using hash(flight_no);
WARNING: hash indexes are not WAL-logged and their use is discouraged
CREATE INDEX
demo=# explain (costs off) select * from flights where flight_no = 'PG0001';
QUERY PLAN
----------------------------------------------------
Bitmap Heap Scan on flights
Recheck Cond: (flight_no = 'PG0001'::bpchar)
-> Bitmap Index Scan on flights_flight_no_idx
Index Cond: (flight_no = 'PG0001'::bpchar)
(4 rows)
Тук можете да видите как внедряваме хеш индекси чрез компилиране на данни в набори.
Това е лесен пример, но имайте предвид, че ограниченията идват с по-малко инфраструктура на кода. Може да има липса на достъп до WAL-лог или невъзможност за възстановяване на индекси (индекси?) след срив. Освен това индексите може да не участват в репликацията – това се дължи на остарял PostgreSQL. Въпреки това, точно както при Python, получавате предупреждения, които често ви позволяват да предотвратите грешки.
Можете да погледнете по-задълбочено в тези индекси, ако сте достатъчно заинтригувани. За това създаваме проверка на страница екземпляр на разширение.
demo=# create extension pageinspect;
CREATE EXTENSION
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',0));
hash_page_type
----------------
metapage
(1 row)
demo=# select ntuples, maxbucket from hash_metapage_info(get_raw_page('flights_flight_no_idx',0));
ntuples | maxbucket
---------+-----------
33121 | 127
(1 row)
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',1));
hash_page_type
----------------
bucket
(1 row)
demo=# select live_items, dead_items from hash_page_stats(get_raw_page('flights_flight_no_idx',1));
live_items | dead_items
------------+------------
407 | 0
(1 row)
Ако искате да проверите напълно кода, започнете с README.
Резюме
Хеш индексите са структура от данни, която ускорява процеса на търсене на информация в големи бази данни. Те работят, като разделят данните на по-малки парчета и след това ги сортират. Така, когато търсите нещо, можете да го намерите много по-бързо.
Ако искате да търсите повече неща, има ресурси за DYOR. Освен това внимавайте за новите ни статии, които излизат по-бързо, отколкото можете да Ctrl+F думата „хеш“ на тази страница. Надявам се това да помогне!