Още през 2014 г. написах статия, наречена Настройка на производителността на целия план за заявка. Той разгледа начини за намиране на относително малък брой различни стойности от умерено голям набор от данни и заключи, че рекурсивното решение може да бъде оптимално. Тази последваща публикация преразглежда въпроса за SQL Server 2019, използвайки по-голям брой редове.
Тестова среда
Ще използвам базата данни от 50 GB Stack Overflow 2013, но всяка голяма таблица с малък брой различни стойности би била подходяща.
Ще търся различни стойности в BountyAmount колона на dbo.Votes таблица, представена във възходящ ред на сумата на наградата. Таблицата Votes има малко под 53 милиона реда (52 928 720 за да бъдем точни). Има само 19 различни суми за награда, включително NULL .
Базата данни на Stack Overflow 2013 се предлага без неклъстерни индекси, за да се сведе до минимум времето за изтегляне. В Id има клъстериран индекс на първичен ключ колона на dbo.Votes маса. Той идва на съвместимост със SQL Server 2008 (ниво 100), но ще започнем с по-модерна настройка на SQL Server 2017 (ниво 140):
ALTER DATABASE StackOverflow2013
SET COMPATIBILITY_LEVEL = 140;
Тестовете бяха извършени на моя лаптоп с помощта на SQL Server 2019 CU 2. Тази машина има четири i7 процесора (с хипернишкова до 8) с базова скорост от 2,4 GHz. Той има 32 GB RAM, като 24 GB са налични за екземпляра на SQL Server 2019. Разходният праг за паралелизъм е зададен на 50.
Всеки резултат от теста представлява най-доброто от десетте проби, с всички необходими данни и индексни страници в паметта.
1. Клъстериран индекс на магазините на редове
За да зададете базова линия, първото изпълнение е серийна заявка без ново индексиране (и не забравяйте, че това е с базата данни, настроена на ниво на съвместимост 140):
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (MAXDOP 1);
Това сканира клъстерирания индекс и използва хеш агрегат в режим на ред, за да намери отделните стойности на BountyAmount :
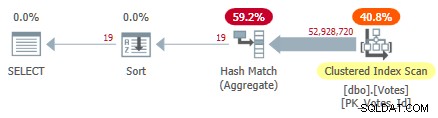 План за сериен клъстерен индекс
План за сериен клъстерен индекс
Това отнема 10 500 мс за да завършите, като използвате същото време на процесора. Не забравяйте, че това е най-доброто време за десет проби с всички данни в паметта. Автоматично създадени статистически извадки за BountyAmount колона са създадени при първото стартиране.
Около половината от изминалото време се изразходва за сканиране на клъстерирани индекси и около половината за агрегата за съвпадение на хеш. Сортирането има само 19 реда за обработка, така че консумира само 1 ms или така. Всички оператори в този план използват изпълнение в режим на ред.
Премахване на MAXDOP 1 hint дава паралелен план:
 План за паралелен клъстерен индекс
План за паралелен клъстерен индекс
Това е планът, който оптимизаторът избира без никакви намеци в моята конфигурация. Връща резултати след 4200 мс използвайки общо 32 800 ms CPU (при DOP 8).
2. Неклъстериран индекс
Сканиране на цялата таблица, за да се намери само BountyAmount изглежда неефективно, така че е естествено да опитате да добавите неклъстериран индекс само към една колона, от която се нуждае тази заявка:
CREATE NONCLUSTERED INDEX b ON dbo.Votes (BountyAmount);
Създаването на този индекс отнема известно време (1 m 40s). MAXDOP 1 заявката вече използва Stream Aggregate, тъй като оптимизаторът може да използва неклъстерирания индекс за представяне на редове в BountyAmount поръчка:
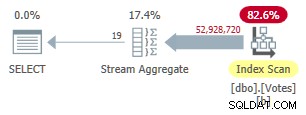 План за режим на сериен неклъстериран ред
План за режим на сериен неклъстериран ред
Това работи за 9300 мс (консумиращо същото време на процесора). Полезно подобрение спрямо оригиналните 10 500 мс, но едва ли е разтърсващо.
Премахване на MAXDOP 1 hint дава паралелен план с локално (по нишка) агрегиране:
 План за паралелен неклъстериран режим на ред
План за паралелен неклъстериран режим на ред
Това се изпълнява за 3400 мс използвайки 25 800 ms време на процесора. Може да успеем да подобрим с компресирането на редове или страници в новия индекс, но искам да премина към по-интересни опции.
3. Пакетен режим в магазин на редове (BMOR)
Сега настройте базата данни в режим на съвместимост на SQL Server 2019, като използвате:
ALTER DATABASE StackOverflow2013 SET COMPATIBILITY_LEVEL = 150;
Това дава на оптимизатора свобода да избира пакетен режим в магазина на редове, ако прецени, че си струва. Това може да осигури някои от предимствата на изпълнението в пакетен режим, без да се изисква индекс на хранилището на колони. За задълбочени технически подробности и недокументирани опции вижте отличната статия на Дмитрий Пилугин по темата.
За съжаление, оптимизаторът все още избира пълно изпълнение в режим на ред, използвайки агрегати на потока както за серийните, така и за паралелните тестови заявки. За да получим пакетен режим в плана за изпълнение на магазина на редове, можем да добавим намек за насърчаване на агрегирането чрез съвпадение на хеш (което може да се изпълнява в пакетен режим):
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (HASH GROUP, MAXDOP 1); Това ни дава план с всички оператори, работещи в пакетен режим:
 Сериен пакетен режим в план за магазин на редове
Сериен пакетен режим в план за магазин на редове
Резултатите се връщат след 2600 мс (всички процесори както обикновено). Това вече е по-бързо от паралелния план за редов режим (изминали 3400 мс), като същевременно се използва много по-малко процесор (2600 мс срещу 25 800 мс).
Премахване на MAXDOP 1 намек (но запазване на HASH GROUP ) дава паралелен пакетен режим на план за магазин за редове:
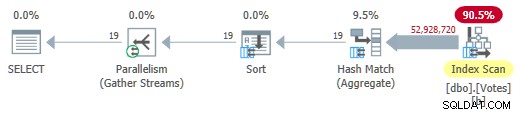 Паралелен пакетен режим на план за магазин на редове
Паралелен пакетен режим на план за магазин на редове
Това се изпълнява само за 725 мс използвайки 5700 мс процесор.
4. Пакетен режим в Column Store
Паралелният пакетен режим на резултата от магазина на редове е впечатляващо подобрение. Можем да направим още по-добре, като предоставим представяне на данните в хранилище на колони. За да запазим всичко останало същото, ще добавя неклъстериран индекс на хранилище на колона само за колоната, от която се нуждаем:
CREATE NONCLUSTERED COLUMNSTORE INDEX nb ON dbo.Votes (BountyAmount);
Това се попълва от съществуващия неклъстериран индекс на b-дърво и отнема само 15 секунди за създаване.
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY V.BountyAmount
OPTION (MAXDOP 1); Оптимизаторът избира напълно пакетен план за режим, включващ сканиране на индекс на хранилището на колони:
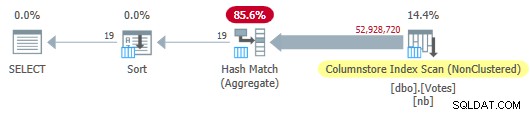 План за магазин за серийни колони
План за магазин за серийни колони
Това се изпълнява за 115 мс използвайки същото време на процесора. Оптимизаторът избира този план без никакви намеци за конфигурацията на моята система, тъй като прогнозната цена на плана е под прага на разходите за паралелизъм .
За да получим паралелен план, можем или да намалим прага на разходите, или да използваме недокументиран намек:
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (USE HINT ('ENABLE_PARALLEL_PLAN_PREFERENCE')); Във всеки случай паралелният план е:
 План за паралелни колони
План за паралелни колони
Изминалото време на заявката вече е до 30 мс , докато консумирате 210 мс процесор.
5. Пакетен режим в Column Store с Push Down
Текущото най-добро време за изпълнение от 30 ms е впечатляващо, особено в сравнение с оригиналните 10 500 ms. Въпреки това е малко срамно, че трябва да предадем близо 53 милиона реда (в 58 868 партиди) от сканирането до агрегата за съвпадения на хеш.
Би било хубаво, ако SQL Server може да изтласка агрегирането надолу в сканирането и просто да върне различни стойности от хранилището на колони директно. Може да си помислите, че трябва да изразим DISTINCT като GROUP BY за да получите Grouped Aggregate Pushdown, но това е логично излишно, а не цялата история във всеки случай.
С настоящата реализация на SQL Server всъщност трябва да изчислим агрегат за да активирате натискане на агрегат. Нещо повече, трябва да използваме обобщения резултат по някакъв начин, или оптимизаторът просто ще го премахне като ненужен.
Един от начините да напишете заявката за постигане на обобщено избутване е да добавите логически излишно изискване за вторично подреждане:
SELECT
V.BountyAmount
FROM dbo.Votes AS V
GROUP BY
V.BountyAmount
ORDER BY
V.BountyAmount,
COUNT_BIG(*) -- New!
OPTION (MAXDOP 1); Серийният план сега е:
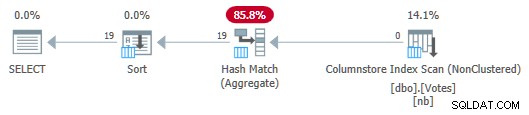 План на магазина за серийни колони с обобщено натискане надолу
План на магазина за серийни колони с обобщено натискане надолу
Забележете, че не се предават редове от сканирането към агрегата! Под кориците, частични агрегати на BountyAmount стойностите и свързаните с тях броя на редовете се предават на Hash Match Aggregate, който сумира частичните агрегати, за да образува необходимия краен (глобален) агрегат. Това е много ефективно, както се потвърждава от изминалото време от 13 мс (всичко това е процесорно време). Като напомняне, предишният сериен план отне 115 мс.
За да завършим комплекта, можем да получим паралелна версия по същия начин както преди:
 План за паралелно хранилище с колони с агрегатно натискане надолу
План за паралелно хранилище с колони с агрегатно натискане надолу
Това работи за 7 мс използвайки общо 40 мс процесор.
Срамота е, че трябва да изчислим и използваме агрегат, от който не се нуждаем, само за да ни натисне. Може би това ще бъде подобрено в бъдеще, така че DISTINCT и GROUP BY без агрегати могат да бъдат преместени надолу към сканирането.
6. Редов режим Рекурсивен общ израз на таблица
В началото обещах да преразгледам рекурсивното CTE решение, използвано за намиране на малък брой дубликати в голям набор от данни. Прилагането на текущото изискване с помощта на тази техника е доста лесно, въпреки че кодът непременно е по-дълъг от всичко, което сме виждали до този момент:
WITH R AS
(
-- Anchor
SELECT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH FIRST 1 ROW ONLY
UNION ALL
-- Recursive
SELECT
Q1.BountyAmount
FROM
(
SELECT
V.BountyAmount,
rn = ROW_NUMBER() OVER (
ORDER BY V.BountyAmount ASC)
FROM R
JOIN dbo.Votes AS V
ON V.BountyAmount > ISNULL(R.BountyAmount, -1)
) AS Q1
WHERE
Q1.rn = 1
)
SELECT
R.BountyAmount
FROM R
ORDER BY
R.BountyAmount ASC
OPTION (MAXRECURSION 0); Идеята има своите корени в така нареченото сканиране при пропускане на индекса:намираме най-ниската стойност, представляваща интерес в началото на индекса на b-дървото с възходящ ред, след това търсим да намерим следващата стойност в реда на индекса и т.н. Структурата на индекса на b-дърво прави намирането на следващата най-висока стойност много ефективно — няма нужда да сканирате през дубликатите.
Единственият истински трик тук е да убедим оптимизатора да ни позволи да използваме TOP в „рекурсивната“ част на CTE, за да върне едно копие на всяка отделна стойност. Моля, вижте предишната ми статия, ако имате нужда от освежаване на подробностите.
Планът за изпълнение (обяснен най-общо от Крейг Фридман тук) е:
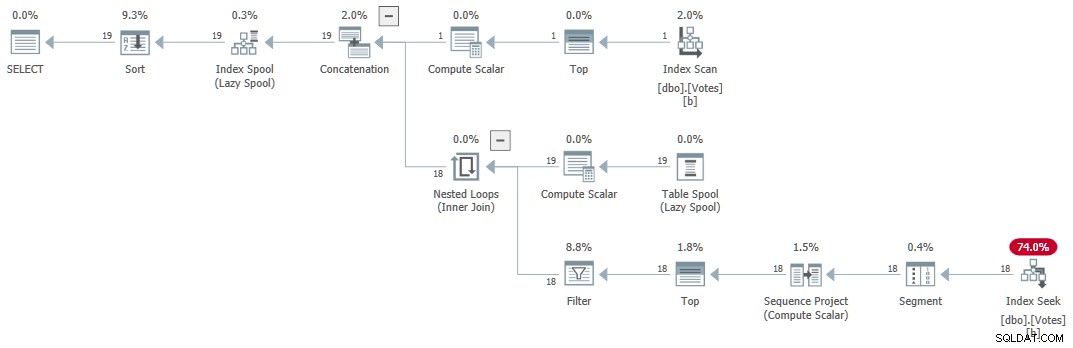 Сериен рекурсивен CTE
Сериен рекурсивен CTE
Заявката връща правилни резултати за 1 мс използвайки 1 мс процесор, според Sentry One Plan Explorer.
7. Итерационен T-SQL
Подобна логика може да бъде изразена с помощта на WHILE цикъл. Кодът може да е по-лесен за четене и разбиране от рекурсивния CTE. Той също така избягва да се налага да се използват трикове за заобикаляне на многото ограничения върху рекурсивната част на CTE. Производителността е конкурентна на около 15 ms. Този код е предоставен за интерес и не е включен в обобщената таблица на ефективността.
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE @Result table
(
BountyAmount integer NULL UNIQUE CLUSTERED
);
DECLARE @BountyAmount integer;
-- First value in index order
WITH U AS
(
SELECT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH NEXT 1 ROW ONLY
)
UPDATE U
SET @BountyAmount = U.BountyAmount
OUTPUT Inserted.BountyAmount
INTO @Result (BountyAmount);
-- Next higher value
WHILE @@ROWCOUNT > 0
BEGIN
WITH U AS
(
SELECT
V.BountyAmount
FROM dbo.Votes AS V
WHERE
V.BountyAmount > ISNULL(@BountyAmount, -1)
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH NEXT 1 ROW ONLY
)
UPDATE U
SET @BountyAmount = U.BountyAmount
OUTPUT Inserted.BountyAmount
INTO @Result (BountyAmount);
END;
-- Accumulated results
SELECT
R.BountyAmount
FROM @Result AS R
ORDER BY
R.BountyAmount; Обобщена таблица за ефективността
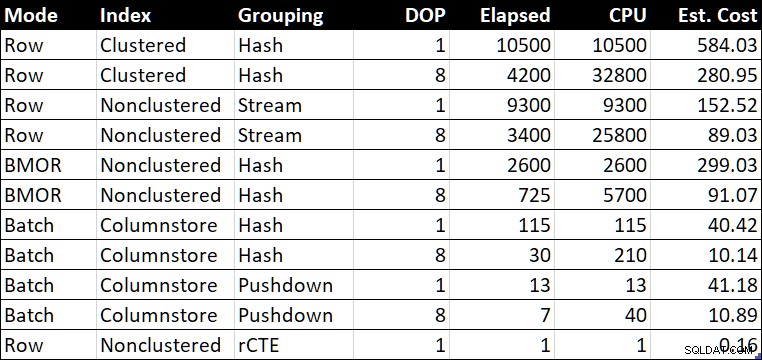 Обобщена таблица на производителността (продължителност/процесор в милисекунди)
Обобщена таблица на производителността (продължителност/процесор в милисекунди)
„Прогн. Колоната за разходи“ показва оценката на разходите на оптимизатора за всяка заявка, отчетена в тестовата система.
Последни мисли
Намирането на малък брой различни стойности може да изглежда като доста конкретно изискване, но съм го срещал доста често през годините, обикновено като част от настройка на по-голяма заявка.
Последните няколко примера бяха доста близки по изпълнение. Много хора биха били доволни от всеки от резултатите от под-втората, в зависимост от приоритетите. Дори серийният пакетен режим в резултат на съхранение на редове от 2600 мс се сравнява добре с най-добрия паралел планове за режим на редове, което предвещава значително ускоряване само чрез надграждане до SQL Server 2019 и активиране на ниво на съвместимост на базата данни 150. Не всеки ще може бързо да премине към съхранение на колони и така или иначе това няма да е винаги правилното решение . Пакетният режим в магазина на редове предоставя чист начин за постигане на някои от печалбите, възможни със складовете на колони, като приемем, че можете да убедите оптимизатора да избере да го използва.
Съвкупният резултат от натискане на съхранението на паралелни колони от 57 милиона реда обработено за 7ms (използвайки 40ms CPU) е забележително, особено като се има предвид хардуера. Резултатът от натискане на серийния агрегат от 13 мс е също толкова впечатляващо. Би било чудесно, ако не се наложи да добавя безсмислен обобщен резултат, за да получа тези планове.
За тези, които все още не могат да преминат към SQL Server 2019 или съхранение на колони, рекурсивният CTE все още е жизнеспособно и ефективно решение, когато съществува подходящ индекс на b-дърво, а броят на необходимите различни стойности гарантирано е доста малък. Би било добре, ако SQL Server може да получи достъп до b-дърво като това, без да е необходимо да пише рекурсивен CTE (или еквивалентен итеративен цикъл на T-SQL код с помощта на WHILE ).
Друго възможно решение на проблема е да се създаде индексиран изглед. Това ще осигури различни стойности с голяма ефективност. Лошото, както обикновено, е, че всяка промяна в основната таблица ще трябва да актуализира броя на редовете, съхранен в материализирания изглед.
Всяко от представените тук решения има своето място в зависимост от изискванията. Наличието на широка гама от налични инструменти като цяло е добро нещо, когато настройвате заявки. През повечето време бих избрал едно от решенията за пакетен режим, защото тяхната производителност ще бъде доста предвидима, независимо колко дубликати са налице.



