Един от страхотните начини да научите за грешки в SQL Server е да прочетете бележките за изданието за Кумулативни актуализации и сервизни пакети, когато излязат. Въпреки това, понякога това също е чудесен начин да научите за подобренията на SQL Server.
Кумулативна актуализация 6 за SQL Server 2014 Service Pack 1 въведе нов флаг за проследяване, 7471, който променя поведението на заключване на задачите UPDATE STATISTICS в SQL Server (вижте KB #3156157). В тази публикация ще разгледаме разликата в поведението на заключване и къде може да бъде полезен този флаг за проследяване.
За да настроя подходяща демонстрационна среда за тази публикация, използвах базата данни AdventureWorks2014 и създадох таблица с увеличена версия SalesOrderDetail въз основа на скрипта, наличен в моя блог. Таблицата SalesOrderDetailEnlarged беше увеличена до 2GB по размер, така че операциите UPDATE STATISTICS WITH FULLSCAN могат да се изпълняват спрямо различни статистически данни в таблицата едновременно. След това използвах sp_whoisactive, за да прегледам заключванията, държани от двете сесии.
Поведение без TF 7471
Поведението по подразбиране на SQL Server изисква изключително заключване (X) на ресурса OBJECT.UPDSTATS за таблицата всеки път, когато команда UPDATE STATISTICS се изпълнява срещу таблица. Можете да видите това в изхода sp_whoisactive за две едновременни изпълнения на UPDATE STATISTICS WITH FULLSCAN спрямо таблицата Sales.SalesOrderDetailEnlarged, като използвате различни имена на индекси за актуализиране на статистиката. Това води до блокиране на второто изпълнение на АКТУАЛИЗИРАНА СТАТИСТИКА, докато първото изпълнение завърши.
АКТУАЛИЗИРАНЕ НА СТАТИСТИКАТА [Продажби].[SalesOrderDetailEnlarged] ([PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID]) С ПЪЛЕН СКАН;
АКТУАЛИЗИРАНЕ НА СТАТИСТИКАТА [Продажби].[SalesOrderDetailEnlarged] ([IX_SalesOrderDetailEnlarged_ProductID]) С ПЪЛНО СКАНИРАНЕ;
Детайлността на ресурса за заключване, който е на OBJECT.UPDSTATS, предотвратява едновременни актуализации на множество статистики спрямо една и съща таблица. Хардуерните подобрения през последните години наистина промениха потенциалните пречки, които са общи за реализациите на SQL Server и точно както промените бяха направени в DBCC CHECKDB, за да работи по-бързо, променяйки поведението на заключване на UPDATE STATISTICS, за да позволи едновременни актуализации на статистическите данни на същата таблица може значително да намали прозорците за поддръжка за VLDB, особено когато има достатъчно капацитет на процесора и I/O подсистемата, за да позволи да се извършват едновременни актуализации, без да се засяга изживяването на крайния потребител.
Поведение с TF 7471
Поведението на заключване с флаг за проследяване 7471 активира промени от изискване на изключително заключване (X) на ресурса OBJECT.UPDSTATS до изискване на заключване за актуализиране (U) на ресурса METADATA.STATS за конкретната статистика, която се актуализира, което позволява едновременни изпълнения на АКТУАЛИЗИРАНА СТАТИСТИКА на същата таблица. Резултатът от sp_whoisactive за същите команди UPDATE STATISTICS WITH FULLCAN с активиран флаг за проследяване е показан по-долу:
АКТУАЛИЗИРАНЕ НА СТАТИСТИКАТА [Продажби].[SalesOrderDetailEnlarged] ([PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID]) С ПЪЛЕН СКАН;
АКТУАЛИЗИРАНЕ НА СТАТИСТИКАТА [Продажби].[SalesOrderDetailEnlarged] ([IX_SalesOrderDetailEnlarged_ProductID]) С ПЪЛНО СКАНИРАНЕ;
За VLDB, които стават все по-често срещано място, това може да направи голяма разлика във времето, необходимо за извършване на актуализации на статистиката в сървъра.
Наскоро писах в блог за решение за паралелна поддръжка за SQL Server, използвайки Service Broker и скриптовете за поддръжка на Ola Hallengren като начин за оптимизиране на задачите за нощна поддръжка и намаляване на времето, необходимо за възстановяване на индекси и актуализиране на статистически данни на сървъри, които имат много CPU и I/O капацитет на разположение. Като част от това решение, аз принудих ред на задачи на опашка към Service Broker, за да се опитам да избегна едновременни изпълнения срещу една и съща таблица както за задачи за повторно изграждане/реорганизиране на индекс, така и за задачи UPDATE STATISTICS. Целта на това беше работниците да бъдат максимално заети до края на задачите за поддръжка, където нещата ще се сериализират в изпълнение въз основа на блокиране на едновременни задачи.
Направих някои модификации на обработката в тази публикация, за да тествам ефектите на този флаг за проследяване само с едновременни актуализации на статистиката и резултатите са по-долу.
Тестване на производителността на едновременно актуализиране на статистика
За да тествам ефективността само на паралелно актуализиране на статистически данни, използвайки конфигурацията на Service Broker, започнах със създаване на статистика на колона за всяка колона в базата данни на AdventureWorks2014, използвайки следния скрипт за генериране на DDL командите, които да бъдат изпълнени.
ИЗПОЛЗВАЙТЕ [AdventureWorks2014] ИЗБЕРЕТЕ ИЗБЕРЕТЕ *, 'ИЗПУСКАНЕ НА СТАТИСТИКА ' + QUOTENAME(c.TABLE_SCHEMA) + '.' + QUOTENAME(c.TABLE_NAME) + '.' + QUOTENAME(c.TABLE_NAME + '_' + c.COLUMN_NAME) + ';GOCREATE STATISTICS ' +QUOTENAME(c.TABLE_NAME + '_' + c.COLUMN_NAME) + 'ON ' + QUOTENAME(c.TABLE_SCHEMA) + ' + QUOTENAME(c.TABLE_NAME) + ' (' +QUOTENAME(c.COLUMN_NAME) + ');' + 'GO' FROM INFORMATION_SCHEMA.COLUMNS AS CINNER JOIN INFORMATION_SCHEMA.TABLES AS t ON c.TABLE_CATALOG =t.TABLE_CATALOG AND c.TABLE_SCHEMA =t.TABLE_SCHEMA AND c.TABLE_SCHEMA AND c.TABLE_SCHEMA AND c.TABLE_BASE' =TPEWTABELE'NAME =TPEWTABLE_NAME. .DATA_TYPE <> N'xml';Това не е нещо, което обикновено бихте искали да направите, но ми дава много статистически данни за паралелно тестване на въздействието на флага за проследяване върху едновременното актуализиране на статистиката. Вместо да подреждам произволно реда, в който поставям задачите на опашка в Service Broker, аз просто поставям задачите на опашка, както съществуват в таблицата CommandLog въз основа на идентификатора на таблицата, като просто увеличавам идентификатора с един, докато всички команди не бъдат поставени на опашката за обработка.
ИЗПОЛЗВАЙТЕ [главен]; -- Изчистете командата LogTRUNCATE TABLE [master].[dbo].[CommandLog]; ДЕКЛАРИРАНЕ @MaxID INT;ИЗБЕРЕТЕ @MaxID =MAX(ID) ОТ master.dbo.CommandLog; SELECT @MaxID =ISNULL(@MaxID, 1) ---- Заредете нови задачи в командата LogEXEC master.dbo.IndexOptimize @Databases =N'AdventureWorks2014', @FragmentationLow =NULL, @FragmentationMedium =NULL, @Fragmentation, @Fragmentation,igh @UpdateStatistics ='ВСИЧКИ', @StatisticsSample =100, @LogToTable ='Y', @Execute ='N'; DECLARE @NewMaxID INTSELECT @NewMaxID =MAX(ID) ОТ master.dbo.CommandLog; ИЗПОЛЗВАЙТЕ msdb; DECLARE @CurrentID INT =@MaxIDWHILE (@CurrentID <=@NewMaxID)BEGIN -- Започнете разговор и изпратете съобщение за заявка DECLARE @conversation_handle UNIQUEIDENTIFIER; ДЕКЛАРИРАНЕ на @message_body XML; ЗАПОЧНЕТЕ ТРАНЗАКЦИЯ; ЗАПОЧНЕТЕ ДИАЛОГ @conversation_handle ОТ УСЛУГА [OlaHallengrenMaintenanceTaskService] КЪМ ОБСЛУЖВАНЕ N'OlaHallengrenMaintenanceTaskService' НА ДОГОВОР [OlaHallengrenMaintenanceTaskContract] С ШИФРИРАНЕ =ИЗКЛЮЧЕНО; SELECT @message_body =N''+CAST(@CurrentID КАТО NVARCHAR)+N' '; ИЗПРАЩАНЕ НА РАЗГОВОР @conversation_handle ТИП СЪОБЩЕНИЕ [OlaHallengrenMaintenanceTaskMessage] (@message_body); ИЗВЪРШВАНЕ НА ТРАНЗАКЦИЯ; SET @CurrentID =@CurrentID + 1; КРАЙ, ДОКАТО СЪЩЕСТВУВА (ИЗБЕРЕТЕ 1 ОТ OlaHallengrenMaintenanceTaskQueue WITH(NOLOCK))ЗАПОЧНЕТЕ WAITFOR DELAY '00:00:01.000'END WAITFOR DELAY '06:00ms DATE(StarFFTime:00ms DATE ), MAX(EndTime)) ОТ master.dbo.CommandLog;GO 10След това изчаках да завършат всички задачи, измерих делтата в началния и крайния час на изпълнението на задачата и взех средната стойност от десет теста, за да определя подобренията само за актуализиране на статистическите данни едновременно с използване на извадката по подразбиране и актуализации за пълно сканиране.
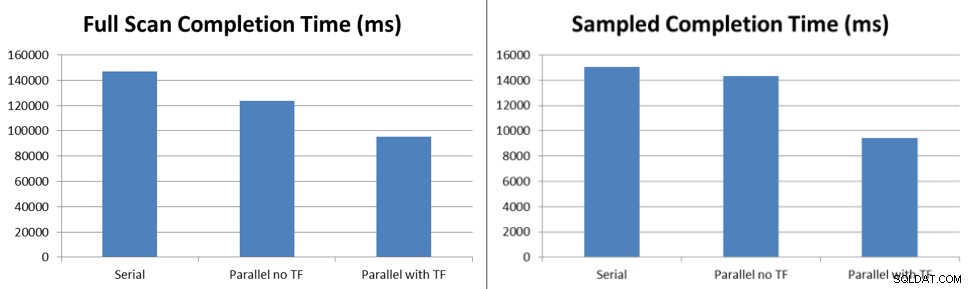
Резултатите от теста показват, че дори при блокирането, което се случва при поведението по подразбиране без флага за проследяване, извадките на актуализациите на статистиката се изпълняват с 6% по-бързо, а актуализациите на пълно сканиране се изпълняват с 16% по-бързо с пет нишки, обработващи задачите, поставени на опашка до Service Broker. С активиран флаг за проследяване 7471, същите извадки актуализации на статистически данни се изпълняват с 38% по-бързо, а актуализациите за пълно сканиране се изпълняват с 45% по-бързо с пет нишки, обработващи задачите, поставени на опашка до Service Broker.
Потенциални предизвикателства с TF 7471
Колкото и убедителни да са резултатите от теста, нищо на този свят не е безплатно и при първоначалното ми тестване на това срещнах някои проблеми с размера на VM, който използвах на моя лаптоп, което създаде проблеми с работното натоварване.
Първоначално тествах паралелна поддръжка, използвайки 4vCPU VM с 4GB RAM, която настроих специално за тази цел. Когато започнах да увеличавам броя на MAX_QUEUE_READERS за процедурата за активиране в Service Broker, започнах да срещам проблеми с изчакването на RESOURCE_SEMAPHORE, когато флагът за проследяване беше активиран, позволявайки паралелни актуализации на статистическите данни за увеличените таблици в моята база данни AdventureWorks2014 поради изискванията за предоставяне на памет за всяка от изпълняваните команди UPDATE STATISTICS. Това беше облекчено чрез промяна на конфигурацията на VM на 16 GB RAM, но това е нещо, което трябва да се наблюдава и следи при изпълнение на паралелни задачи на по-големи таблици, за да се включи поддръжка на индекси, тъй като липсата на памет ще повлияе и на заявките на крайния потребител, които може да се опитват да изпълнят и също се нуждаете от по-голямо предоставяне на памет.
Екипът на продукта също е публикувал в блог за този флаг за проследяване и в публикацията си те предупреждават, че могат да възникнат сценарии за блокиране по време на едновременно актуализиране на статистиката, докато статистическите данни също се създават. Това не е нещо, с което все още съм се сблъсквал по време на тестването си, но определено трябва да знам (Кендра Литъл също предупреждава за това). В резултат на това, тяхната препоръка е този флаг за проследяване да се активира само по време на изпълнение на задачата за паралелна поддръжка и след това трябва да бъде деактивиран за нормални периоди на натоварване.
Насладете се!