Забележка:Тази публикация първоначално е публикувана само в нашата електронна книга, Високопроизводителни техники за SQL Server, том 3. Можете да научите за нашите електронни книги тук.
Едно изискване, което виждам от време на време, е да има върната заявка с поръчки, групирани по клиент, показващи максималния общ дължим, видян за всяка поръчка до момента („изпълнена макс.“). Така че представете си тези примерни редове:
| SalesOrderID | CustomerID | Дата на поръчка | TotalDue |
|---|---|---|---|
| 12 | 2 | 01.01.2014 | 37,55 |
| 23 | 1 | 2014-01-02 | 45,29 |
| 31 | 2 | 03.01.2014 | 24,56 |
| 32 | 2 | 04.01.2014 | 89,84 |
| 37 | 1 | 05.01.2014 | 32,56 |
| 44 | 2 | 06.01.2014 | 45,54 |
| 55 | 1 | 07.01.2014 | 99,24 |
| 62 | 2 | 08.01.2014 | 12,55 |
Няколко реда примерни данни
Желаните резултати от посочените изисквания са както следва – накратко, сортирайте поръчките на всеки клиент по дата и избройте всяка поръчка. Ако това е най-високата стойност на TotalDue за всички поръчки, наблюдавани до тази дата, отпечатайте общата сума на поръчката, в противен случай отпечатайте най-високата стойност на TotalDue от всички предишни поръчки:
| SalesOrderID | CustomerID | Дата на поръчка | TotalDue | MaxTotalDue |
|---|---|---|---|---|
| 12 | 1 | 2014-01-02 | 45,29 | 45,29 |
| 23 | 1 | 05.01.2014 | 32,56 | 45,29 |
| 31 | 1 | 07.01.2014 | 99,24 | 99,24 |
| 32 | 2 | 01.01.2014 | 37,55 | 37,55 |
| 37 | 2 | 03.01.2014 | 24,56 | 37,55 |
| 44 | 2 | 04.01.2014 | 89,84 | 89,84 |
| 55 | 2 | 06.01.2014 | 45,54 | 89,84 |
| 62 | 2 | 08.01.2014 | 12,55 | 89,84 |
Примерни желани резултати
Много хора инстинктивно биха искали да използват курсор или цикъл while, за да постигнат това, но има няколко подхода, които не включват тези конструкции.
Корелирана подзаявка
Този подход изглежда най-простият и ясен подход към проблема, но е доказано отново и отново, че не се мащабира, тъй като показанията нарастват експоненциално с увеличаването на таблицата:
SELECT /* Корелирана подзаявка */ SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue =(SELECT MAX(TotalDue) FROM Sales.SalesOrderHeader, WHERE CustomerID =h.CustomerID И SalesOrderID <=h.SalesOrderID <=h.SalesAderSalesA FROM SalesHeader ORDER BY CustomerID, SalesOrderID;
Ето плана срещу AdventureWorks2014, използвайки SQL Sentry Plan Explorer:
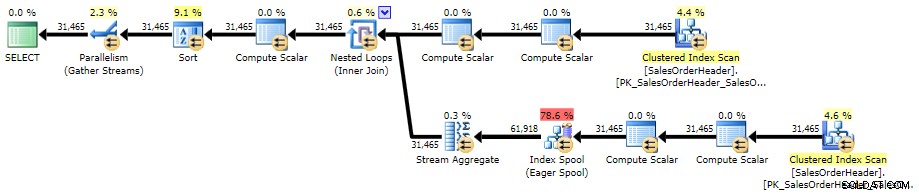 План за изпълнение на корелирана подзаявка (щракнете, за да увеличите)
План за изпълнение на корелирана подзаявка (щракнете, за да увеличите)
КРЪСТНО ПРИЛАГАНЕ на самостоятелно препращане
Този подход е почти идентичен с подхода на корелирана подзаявка по отношение на синтаксис, форма на плана и производителност в мащаб.
ИЗБЕРЕТЕ /* КРЪСТНО ПРИЛАГАНЕ */ h.SalesOrderID, h.CustomerID, h.OrderDate, h.TotalDue, x.MaxTotalDueFROM Sales.SalesOrderHeader КАТО hCROSS APPLY( SELECT MaxTotalDue =MAXeader Sales (Изберете MaxTotalDue =MAXeader Sales) i Totalles i.CustomerID =h.CustomerID И i.SalesOrderID <=h.SalesOrderID) КАТО xORDER BY h.CustomerID, h.SalesOrderID;
Планът е доста подобен на корелирания план за подзаявка, като единствената разлика е местоположението на сорта:
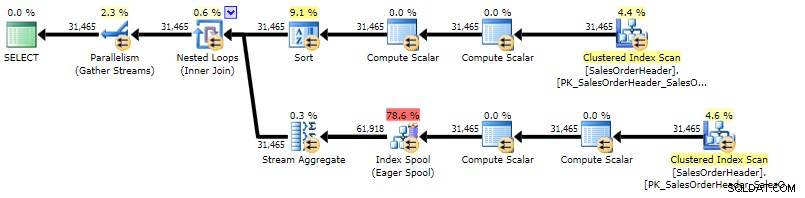 План за изпълнение на CROSS APPLY (щракнете, за да увеличите)
План за изпълнение на CROSS APPLY (щракнете, за да увеличите)
Рекурсивен CTE
Зад кулисите това използва цикли, но докато всъщност не го стартираме, можем да се преструваме, че не го прави (въпреки че лесно е най-сложната част от кода, която някога бих искал да напиша, за да разреша този конкретен проблем):
;WITH /* Рекурсивна CTE */ cte AS ( SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue FROM ( SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue =TotalDue, rn =ROW_PARTIORD BY NUMBER() BY SalesOrderID) ОТ Sales.SalesOrderHeader ) AS x WHERE rn =1 UNION ALL SELECT r.SalesOrderID, r.CustomerID, r.OrderDate, r.TotalDue, MaxTotalDue =CASE WHEN r.Total.MaxeDue. .MaxTotalDue END FROM cte CROSS APPLY ( ИЗБЕРЕТЕ SalesOrderID, CustomerID, OrderDate, TotalDue, rn =ROW_NUMBER() НАД (РАЗДЕЛЕНИЕ ПО CustomerID ORDER BY SalesOrderID) FROM Sales.SalesOrderHeader AS h WHERE. cte.SalesOrderID ) AS r WHERE r.rn =1)ИЗБЕРЕТЕ SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDueFROM cteORDER BY CustomerID, SalesOrderIDOPTION (MAXRECURSION 0);
Веднага можете да видите, че планът е по-сложен от предишните два, което не е изненадващо предвид по-сложната заявка:
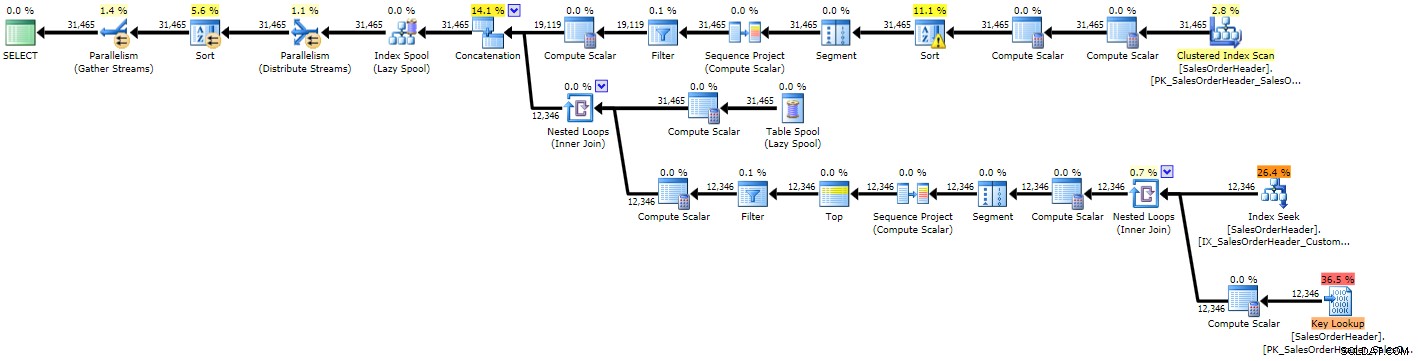 План за изпълнение за рекурсивна CTE (щракнете, за да увеличите)
План за изпълнение за рекурсивна CTE (щракнете, за да увеличите)
Поради някои лоши оценки виждаме търсене на индекс с придружаващо ключово търсене, което вероятно би трябвало и двете да бъдат заменени с едно сканиране, а също така получаваме операция за сортиране, която в крайна сметка трябва да се разлее в tempdb (можете да видите това в подсказката ако задържите курсора на мишката върху оператора за сортиране с иконата за предупреждение):

MAX() НАД (НЕОГРАНИЧЕН РЕДОВ)
Това е решение, достъпно само в SQL Server 2012 и по-нова версия, тъй като използва нововъведени разширения за функциите на прозорците.
SELECT /* MAX() OVER() */ SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue =MAX(TotalDue) OVER ( PARTITION BY CustomerID ORDER BY SalesOrderID РЕДОВ НЕОГРАНИЧЕН ПРЕДШЕСТВАЩ )FROM SalesHer. /предварително>Планът показва точно защо се мащабира по-добре от всички останали; има само една клъстерирана операция за сканиране на индекс, за разлика от две (или лош избор на сканиране и търсене + търсене в случая на рекурсивния CTE):
План за изпълнение на MAX() OVER() (щракнете, за да увеличите)
Сравнение на производителността
Плановете със сигурност ни карат да вярваме, че новият
MAX() OVER()възможностите в SQL Server 2012 са истински победител, но какво ще кажете за осезаеми показатели по време на изпълнение? Ето как се сравняват изпълненията:
Първите две заявки бяха почти идентични; докато в този случай
CROSS APPLYбеше по-добра по отношение на общата продължителност с малка разлика, корелираната подзаявка понякога я изпреварва с малко. Рекурсивният CTE е значително по-бавен всеки път и можете да видите факторите, които допринасят за това – а именно лошите оценки, огромното количество четения, търсенето на ключове и допълнителната операция за сортиране. И както демонстрирах преди с текущите суми, решението на SQL Server 2012 е по-добро в почти всеки аспект.Заключение
Ако използвате SQL Server 2012 или по-нова версия, определено искате да се запознаете с всички разширения на функциите за прозорци, въведени за първи път в SQL Server 2005 – те може да ви дадат доста сериозно повишаване на производителността, когато преглеждате кода, който все още работи " по стария начин." Ако искате да научите повече за някои от тези нови възможности, горещо препоръчвам книгата на Itzik Ben-Gan, Microsoft SQL Server 2012 High-Performance T-SQL Using Window Functions.
Ако все още не сте на SQL Server 2012, поне в този тест можете да избирате между
CROSS APPLYи свързаната подзаявка. Както винаги, трябва да тествате различни методи спрямо вашите данни на вашия хардуер.