В публикациите си тази година обсъждах реакциите на коляното при различни видове изчакване и в тази публикация ще продължа с темата за статистиката за чакане и ще обсъдя PAGEIOLATCH_XX изчакайте. Казвам "изчакайте", но наистина има няколко вида PAGEIOLATCH чака, което съм обозначил с XX в края. Най-често срещаните примери са:
PAGEIOLATCH_SH– (SH са) чака страница с файл с данни да бъде пренесена от диска в буферния пул, за да може съдържанието й да бъде прочетеноPAGEIOLATCH_EXилиPAGEIOLATCH_UP– (EX включващ или ГОРЕ дата) чака страница с файл с данни да бъде пренесена от диска в буферния пул, за да може съдържанието й да бъде променено.
От тях най-често срещаният тип е PAGEIOLATCH_SH .
Когато този тип изчакване е най-разпространеният на сървъра, реакцията на коляното е, че I/O подсистемата трябва да има проблем и затова разследванията трябва да бъдат фокусирани.
Първото нещо, което трябва да направите, е да сравните PAGEIOLATCH_SH брой изчакване и продължителност спрямо изходното ви ниво. Ако обемът на изчакванията е горе-долу същият, но продължителността на всяко изчакване за четене е станала много по-дълга, тогава бих се притеснявал за проблем с I/O подсистемата, като например:
- Неправилна конфигурация/неизправност на ниво I/O подсистема
- Забавяне на мрежата
- Друго I/O работно натоварване, което причинява спор с нашето работно натоварване
- Конфигуриране на синхронна I/O-подсистема репликация/огледалност
Според моя опит моделът често е, че броят на PAGEIOLATCH_SH изчакванията са се увеличили значително от базовото (нормално) количество и продължителността на изчакване също се е увеличила (т.е. времето за четене на I/O се е увеличило), тъй като големият брой четения претоварва I/O подсистемата. Това не е проблем на I/O подсистемата – това е SQL Server, който управлява повече I/O, отколкото би трябвало да бъде. Фокусът сега трябва да се превключи към SQL Server, за да се идентифицира причината за допълнителните I/O.
Причини за голям брой входове/изходи за четене
SQL Server има два типа четене:логически входно-изходни и физически входно-изходни. Когато частта Методи за достъп на Storage Engine трябва да получи достъп до страница, тя иска от буферния пул за указател към страницата в паметта (наречена логически вход/изход) и буферният пул проверява чрез своите метаданни, за да види дали тази страница е вече в паметта.
Ако страницата е в паметта, буферният пул дава на методите за достъп указател и I/O остава логически I/O. Ако страницата не е в паметта, буферният пул издава "реален" I/O (наречен физически I/O) и нишката трябва да изчака да завърши – пораждайки PAGEIOLATCH_XX изчакайте. След като I/O завърши и показалецът е наличен, нишката е уведомена и може да продължи да работи.
В идеалния свят цялото ви работно натоварване би се поберело в паметта и така, след като буферният пул се „загрее“ и задържи цялото работно натоварване, не се изискват повече четения, а само записване на актуализирани данни. Това обаче не е идеален свят и повечето от вас нямат този лукс, така че някои четения са неизбежни. Докато броят на четенията остава около базовото ви количество, няма проблем.
Когато се наложи голям брой четения внезапно и неочаквано, това е знак, че има значителна промяна или в работното натоварване, в количеството памет на буферния пул, наличен за съхраняване на копия на страници в паметта, или и в двете.
Ето някои възможни основни причини (не е изчерпателен списък):
- Натиск от външна памет на Windows върху SQL Server, което кара мениджъра на паметта да намали размера на буферния пул.
- Планирайте раздуване на кеша, което води до заемане на допълнителна памет от буферния пул.
- План на заявка, извършващ сканиране на таблица/клъстериран индекс (вместо търсене на индекс) поради:
- увеличаване на обема на натоварване
- проблем при подслушване на параметри
- задължителен неклъстериран индекс, който е отпаднал или променен
- неявно преобразуване
Един модел, който трябва да търсите, който предполага, че сканирането на таблица/клъстериран индекс е причината също така да виждате голям брой CXPACKET изчаква заедно с PAGEIOLATCH_SH чака. Това е често срещан модел, който показва, че се извършват големи, паралелни сканирания на таблици/клъстерни индекси.
Във всички случаи можете да разгледате какъв план за заявка причинява PAGEIOLATCH_SH чака с помощта на sys.dm_os_waiting_tasks и други DMV и можете да получите код за това в моя публикация в блога тук. Ако имате наличен инструмент за наблюдение на трета страна, той може да ви помогне да идентифицирате виновника, без да си изцапате ръцете.
Примерен работен поток със SQL Sentry и Plan Explorer
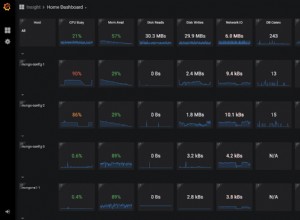
В прост (очевидно измислен) пример, нека да предположим, че съм на клиентска система, използваща набора от инструменти на SQL Sentry и виждам скок в изчакванията за I/O в изгледа на таблото на SQL Sentry, както е показано по-долу:
Забелязване на скок в I/O чака в SQL Sentry
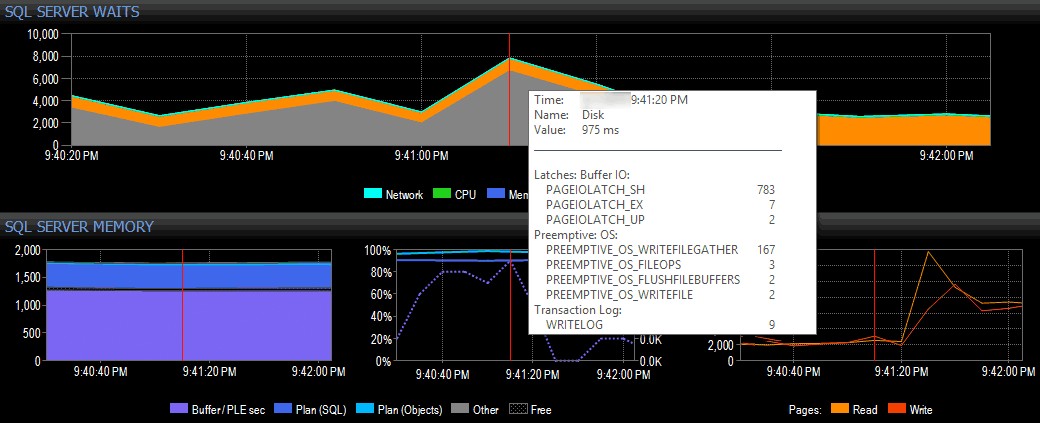
Решавам да проуча, като щракна с десния бутон върху избран интервал от време около момента на пика, след което прескоча към изгледа Top SQL, който ще ми покаже най-скъпите заявки, които са изпълнени:
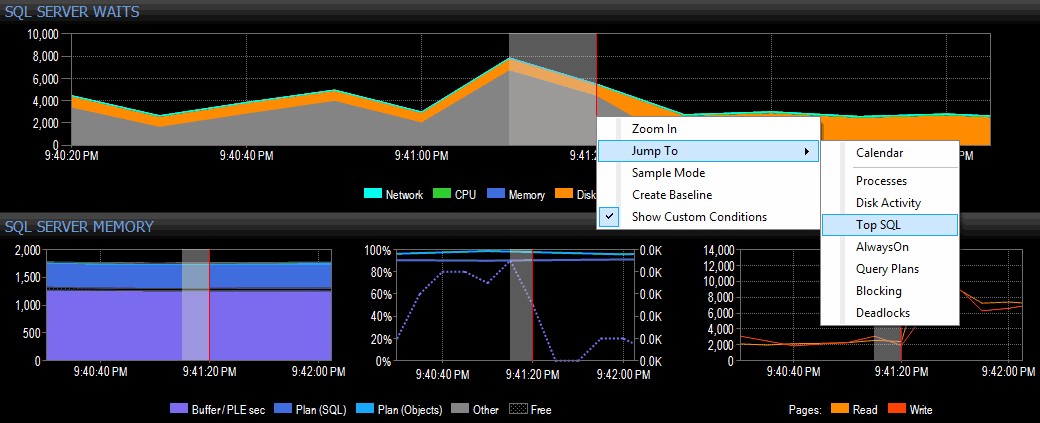
Открояване на времеви диапазон и навигация до Top SQL
В този изглед мога да видя кои продължителни или високи I/O заявки са се изпълнявали в момента на възникване на скок, и след това да избера да разгледам техните планове за заявки (в този случай има само една продължителна заявка, който продължи близо минута):
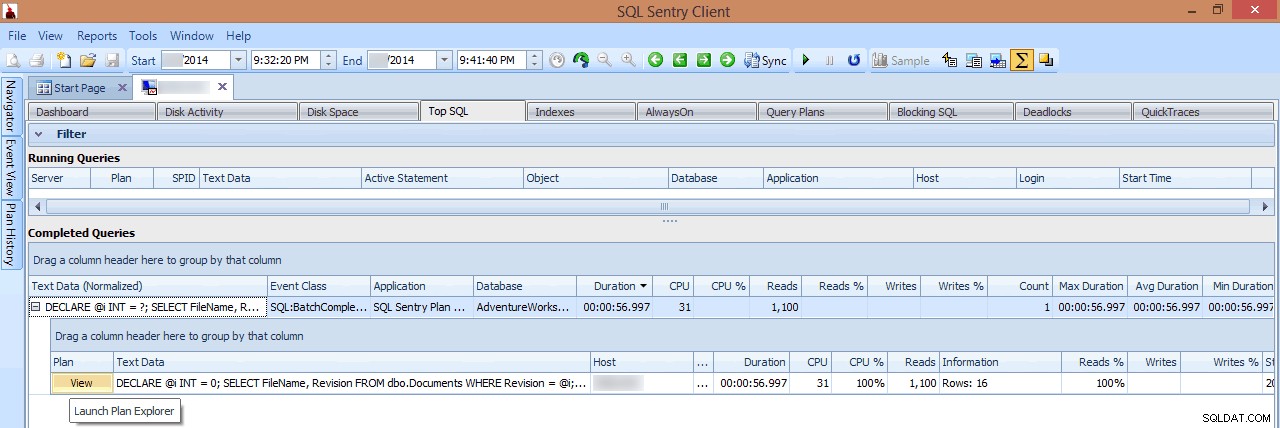
Преглед на продължителна заявка в Top SQL
Ако погледна плана в SQL Sentry клиента или го отворя в SQL Sentry Plan Explorer, веднага виждам множество проблеми. Броят четения, необходими за връщане на 7 реда, изглежда твърде висок, делтата между прогнозните и действителните редове е голяма и планът показва сканиране на индекса, което се извършва там, където бих очаквал търсене:
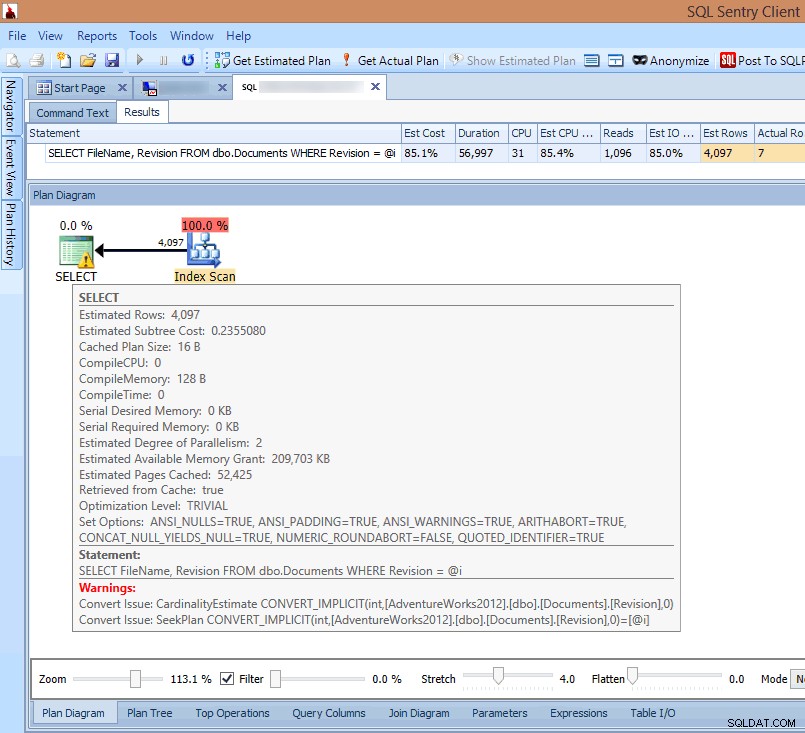
Виждане на неявни предупреждения за преобразуване в плана на заявката
Причината за всичко това е подчертана в предупреждението на SELECT оператор:Това е имплицитно преобразуване!
Неявните преобразувания са коварен проблем, причинен от несъответствие между типа данни на предиката за търсене и типа данни на колоната, която се търси, или изчисление, което се извършва върху колоната на таблицата, а не предиката за търсене. И в двата случая SQL Server не може да използва търсене на индекс в колоната на таблицата и вместо това трябва да използва сканиране.
Това може да се появи в привидно невинен код и често срещан пример е използването на изчисление на дата. Ако имате таблица, която съхранява възрастта на клиентите, и искате да извършите изчисление, за да видите колко са на 21 години или повече днес, може да напишете код като този:
WHERE DATEADD (YEAR, 21, [MyTable].[BirthDate]) <= @today;
С този код изчислението е в колоната на таблицата и така търсенето на индекс не може да се използва, което води до нетърсен израз (технически известен като израз без SARG) и сканиране на таблица/клъстерен индекс. Това може да бъде решено чрез преместване на изчислението от другата страна на оператора:
WHERE [MyTable].[BirthDate] <= DATEADD (YEAR, -21, @today);
По отношение на това кога едно основно сравнение на колони изисква преобразуване на тип данни, което може да причини имплицитно преобразуване, моят колега Джонатан Кехайяс написа отлична публикация в блога, която сравнява всяка комбинация от типове данни и отбелязва кога ще е необходимо имплицитно преобразуване.
Резюме
Не попадайте в капана на мисълта, че прекомерното PAGEIOLATCH_XX изчакванията са причинени от I/O подсистемата. Според моя опит те обикновено са причинени от нещо, свързано със SQL Server и оттам бих започнал да отстранявам неизправности.
Що се отнася до общата статистика за чакане, можете да намерите повече информация за използването им за отстраняване на неизправности в производителността в:
- Моята серия от публикации в блога на SQLskills, започваща със статистически данни за чакане или моля, кажете ми къде боли
- Моята библиотека за типове чакане и класове за заключване тук
- Моят онлайн курс за обучение на Pluralsight SQL Server:Отстраняване на проблеми с производителността с помощта на статистика за чакане
- SQL Sentry
В следващата статия от поредицата ще обсъдя друг тип изчакване, който е често срещана причина за реакции на коляно. Дотогава, щастливо отстраняване на неизправности!