Помислете за следната заявка на AdventureWorks, която връща идентификатори на транзакции в таблицата с история за продукт ID 421:
SELECT TH.TransactionID FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 421;
Оптимизаторът на заявки бързо намира ефективен план за изпълнение с оценка на кардиналността (брой редове), която е точно правилна, както е показано в SQL Sentry Plan Explorer:

Сега да кажем, че искаме да намерим идентификатори на транзакции в историята за продукта на AdventureWorks, наречен "Metal Plate 2". Има много начини да изразите тази заявка в T-SQL. Една естествена формулировка е:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Планът за изпълнение е както следва:
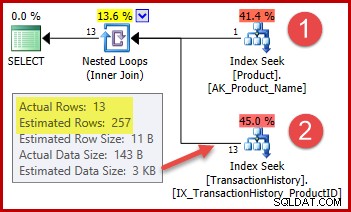
Стратегията е:
- Потърсете идентификатора на продукта в таблицата с продуктите от даденото име
- Намерете редове за този идентификатор на продукта в таблицата с история
Прогнозният брой редове за стъпка 1 е точно правилен, тъй като използваният индекс е деклариран като уникален и се въвежда само в името на продукта. Следователно тестът за равенство на „Metal Plate 2“ гарантирано ще върне точно един ред (или нула редове, ако посочим име на продукт, което не съществува).
Маркираната оценка за 257 реда за стъпка втора е по-малко точна:действително се срещат само 13 реда. Това несъответствие възниква, тъй като оптимизаторът не знае кой конкретен идентификатор на продукта е свързан с продукта, наречен "Metal Plate 2". Той третира стойността като неизвестна, генерирайки оценка на мощността, използвайки информация за средната плътност. Изчислението използва елементи от статистическия обект, показан по-долу:
DBCC SHOW_STATISTICS
(
'Production.TransactionHistory',
'IX_TransactionHistory_ProductID'
)
WITH STAT_HEADER, DENSITY_VECTOR;
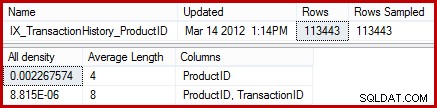
Статистиката показва, че таблицата съдържа 113443 реда с 441 уникални идентификатора на продукта (1 / 0,002267574 =441). Ако приемем, че разпределението на редовете между идентификаторите на продукти е равномерно, оценката на кардиналността очаква идентификатор на продукта да съвпада (113443 / 441) =средно 257,24 реда. Както се оказва, разпределението не е особено равномерно; има само 13 реда за продукта "Metal Plate 2".
Отстрани
Може би си мислите, че оценката за 257 реда трябва да е по-точна. Например, като се има предвид, че идентификаторите и имената на продуктите са ограничени да бъдат уникални, SQL Server може автоматично да поддържа информация за тази връзка един към един. Тогава той ще знае, че „Metal Plate 2“ е свързан с идентификатор на продукт 479, и ще използва това прозрение, за да генерира по-точна оценка, използвайки хистограмата на ProductID:
DBCC SHOW_STATISTICS
(
'Production.TransactionHistory',
'IX_TransactionHistory_ProductID'
)
WITH HISTOGRAM;
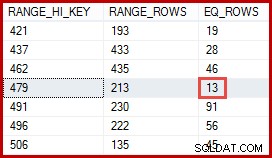
Оценката за 13 реда, получени по този начин, би била точно правилна. Независимо от това, оценката за 257 реда не беше неразумна, като се има предвид наличната статистическа информация и нормалните опростяващи допускания (като равномерно разпределение), прилагани от оценката на мощността днес. Точните оценки винаги са добри, но „разумните“ оценки също са напълно приемливи.
Комбиниране на двете заявки
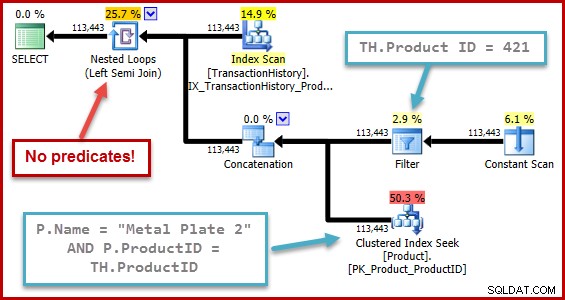
Да кажем, че сега искаме да видим всички идентификатори на историята на транзакциите, където идентификационният номер на продукта е 421 ИЛИ името на продукта е "Metal Plate 2". Естествен начин за комбиниране на двете предишни заявки е:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
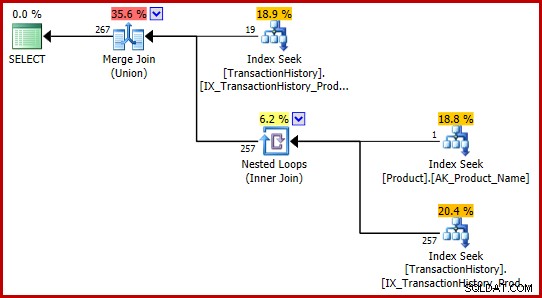
); Планът за изпълнение сега е малко по-сложен, но все още съдържа разпознаваеми елементи от плановете с един предикат:
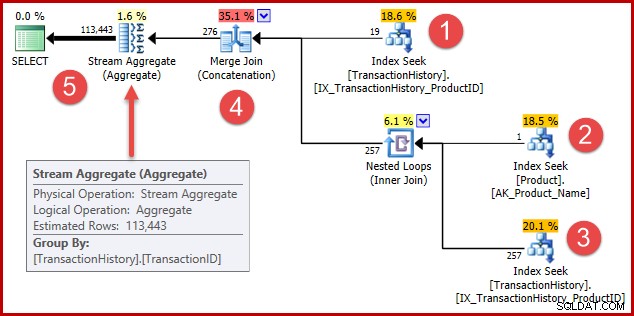
Стратегията е:
- Намерете записи в историята за продукт 421
- Потърсете идентификационния номер на продукта, наречен „Metal Plate 2“
- Намерете записи в историята за идентификатора на продукта, намерен в стъпка 2
- Комбинирайте редове от стъпки 1 и 3
- Отстранете всички дубликати (защото продукт 421 може също да е този, наречен „Метална плоча 2“)
Стъпки 1 до 3 са абсолютно същите като преди. Същите оценки се правят по същите причини. Стъпка 4 е нова, но много проста:тя обединява очакваните 19 реда с очакваните 257 реда, за да даде оценка от 276 реда.
Стъпка 5 е най-интересната. Агрегатът на потока за премахване на дубликати има приблизителен вход от 276 реда и очакван изход от 113443 реда. Агрегат, който извежда повече редове, отколкото получава, изглежда невъзможен, нали?
* Тук ще видите приблизителна оценка от 102099 реда, ако използвате модела за оценка на мощността преди 2014 г.
Бъг в оценката на кардиналността
Невъзможната оценка на Stream Aggregate в нашия пример е причинена от грешка в оценката на мощността. Това е интересен пример, така че ще го проучим малко по-подробно.
Премахване на подзаявка
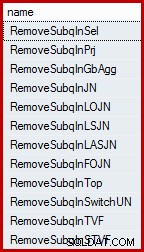
Може да ви изненада да научите, че оптимизаторът на заявки на SQL Server не работи директно с подзаявки. Те се премахват от дървото на логическата заявка в началото на процеса на компилация и се заменят с еквивалентна конструкция, с която оптимизаторът е настроен да работи и да разсъждава. Оптимизаторът има редица правила, които премахват подзаявки. Те могат да бъдат изброени по име, като се използва следната заявка (посоченият DMV е минимално документиран, но не се поддържа):
SELECT name FROM sys.dm_exec_query_transformation_stats WHERE name LIKE 'RemoveSubq%';
Резултати (на SQL Server 2014):
Комбинираната тестова заявка има два предиката („селекции“ в релационни термини) в таблицата на историята, свързани с OR . Един от тези предикати включва подзаявка. Цялото поддърво (както предикати, така и подзаявката) се трансформира от първото правило в списъка („премахване на подзаявката при избор“) до полусъединяване върху обединението на отделните предикати. Въпреки че не е възможно да се представи резултатът от тази вътрешна трансформация точно с помощта на синтаксис на T-SQL, той е доста близо до това:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE EXISTS
(
SELECT 1
WHERE TH.ProductID = 421
UNION ALL
SELECT 1
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
AND P.ProductID = TH.ProductID
)
OPTION (QUERYRULEOFF ApplyUAtoUniSJ); Малко е жалко, че моето T-SQL приближение на вътрешното дърво след премахване на подзаявка съдържа подзаявка, но на езика на процесора на заявки не го (това е полусъединяване). Ако предпочитате да видите необработената вътрешна форма вместо моя опит за еквивалент на T-SQL, моля, бъдете сигурни, че ще се появи за момент.
Недокументираният намек за заявка, включен в T-SQL по-горе, има за цел да предотврати последваща трансформация за тези от вас, които искат да видят трансформираната логика във формата на план за изпълнение. Поясненията по-долу показват позициите на двата предиката след трансформацията:
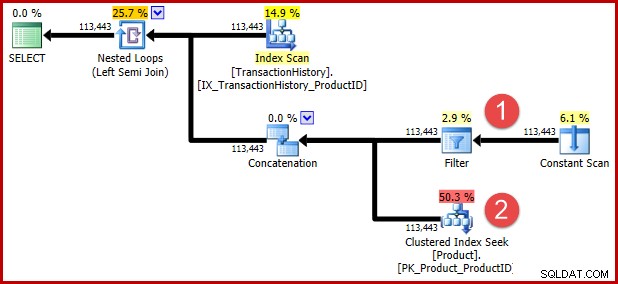
Интуицията зад трансформацията е, че исторически ред отговаря на изискванията, ако някой от предикатите е удовлетворен. Независимо от това колко полезна ви е моята приблизителна илюстрация на T-SQL и план за изпълнение, надявам се, че е поне разумно ясно, че пренаписването изразява същото изискване като оригиналната заявка.
Трябва да подчертая, че оптимизаторът не генерира буквално алтернативен синтаксис на T-SQL или произвежда пълни планове за изпълнение на междинни етапи. Представянията на T-SQL и плана за изпълнение по-горе са предназначени само за помощ за разбирането. Ако се интересувате от необработените подробности, обещаното вътрешно представяне на трансформираното дърво на заявката (леко редактирано за яснота/пространство) е:
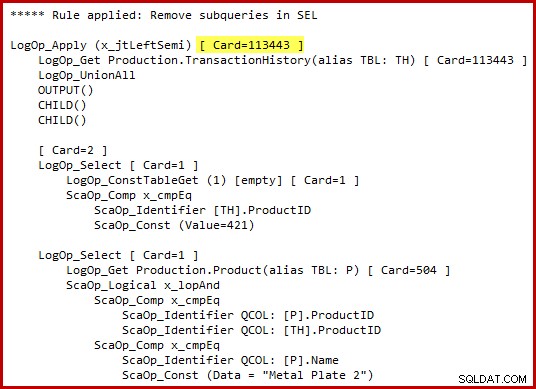
Обърнете внимание на маркираната оценка за мощност на прилагане на полусъединяване. Това е 113443 реда, когато се използва оценката на мощността за 2014 г. (102099 реда, ако се използва старата CE). Имайте предвид, че таблицата с историята на AdventureWorks съдържа общо 113443 реда, така че това представлява 100% селективност (90% за стария CE).
По-рано видяхме, че прилагането на който и да е от тези предикати самостоятелно води само до малък брой съвпадения:19 реда за продукт ID 421 и 13 реда (приблизително 257) за „Metal Plate 2“. Преценка, че дизюнкцията (OR) от двата предиката ще върне всички редове в основната таблица изглежда напълно безумно.
Подробности за грешка
Подробностите за изчисляването на селективността за полусъединяването са видими само в SQL Server 2014, когато се използва новият оценител на мощността с (недокументиран) флаг за проследяване 2363. Вероятно е възможно да видите нещо подобно с разширени събития, но изходът на флага за проследяване е по-удобен да използвате тук. Съответният раздел на изхода е показан по-долу:
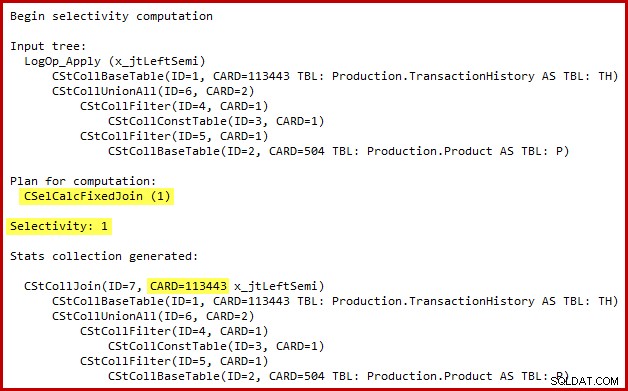
Оценителят на мощността използва калкулатора с фиксирано свързване със 100% селективност. В резултат на това изчислената мощност на изхода на полусъединяването е същата като входната му, което означава, че всички 113443 реда от таблицата с история се очаква да отговарят на изискванията.
Точното естество на грешката е, че изчислението на селективността на полусъединяване пропуска всички предикати, позиционирани извън обединение, всички във входното дърво. В илюстрацията по-долу липсата на предикати в самото полусъединяване се приема, че означава, че всеки ред ще отговаря на изискванията; той игнорира ефекта на предикатите под конкатенацията (обединение на всички).
Това поведение е още по-изненадващо, когато вземете предвид, че изчисляването на селективността работи върху представяне на дърво, което оптимизаторът е генерирал сам (формата на дървото и позиционирането на предикатите е резултат от премахването на подзаявката).
Подобен проблем възниква и с оценката на мощността от преди 2014 г., но крайната оценка вместо това е фиксирана на 90% от предполагаемия вход за полусъединяване (по забавни причини, свързани с инверсна фиксирана предикатна оценка от 10%, която е твърде голямо отклонение, за да се получи в).
Примери
Както бе споменато по-горе, тази грешка се проявява, когато оценката се извършва за полусъединяване със свързани предикати, позиционирани извън обединението all. Дали това вътрешно подреждане се случва по време на оптимизацията на заявки зависи от оригиналния синтаксис на T-SQL и точната последователност от операции за вътрешна оптимизация. Следните примери показват някои случаи, когато грешката се появява и не се появява:
Пример 1
Този първи пример включва тривиална промяна в тестовата заявка:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = (SELECT 421) -- The only change
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Прогнозният план за изпълнение е:
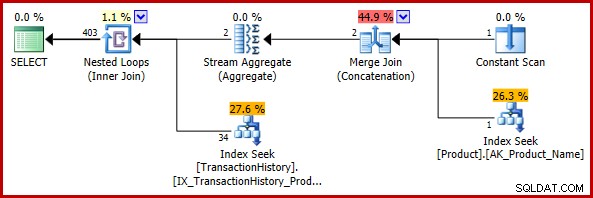
Окончателната оценка от 403 реда е несъвместима с входните оценки на присъединяването на вложени цикли, но все пак е разумна (в смисъла, обсъден по-рано). Ако се срещне грешката, крайната оценка ще бъде 113443 реда (или 102099 реда, когато се използва моделът отпреди 2014 г. CE).
Пример 2
В случай, че сте на път да се втурнете и да пренапишете всичките си постоянни сравнения като тривиални подзаявки, за да избегнете тази грешка, вижте какво ще се случи, ако направим друга тривиална промяна, като този път заменим теста за равенство във втория предикат с IN. Значението на заявката остава непроменено:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = (SELECT 421) -- Change 1
OR TH.ProductID IN -- Change 2
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Грешката връща:
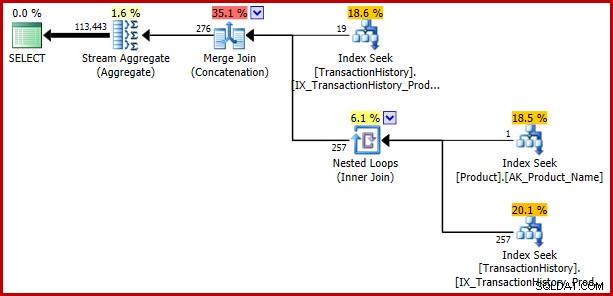
Пример 3
Въпреки че тази статия досега се концентрира върху дизюнктивен предикат, съдържащ подзаявка, следващият пример показва, че същата спецификация на заявката, изразена с EXISTS и UNION ALL, също е уязвима:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE EXISTS
(
SELECT 1
WHERE TH.ProductID = 421
UNION ALL
SELECT 1
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
AND P.ProductID = TH.ProductID
); План за изпълнение:
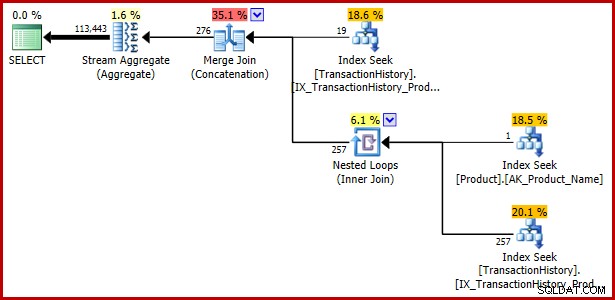
Пример 4
Ето още два начина за изразяване на същата логическа заявка в T-SQL:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
UNION
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
);
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
UNION
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
JOIN Production.Product AS P
ON P.ProductID = TH.ProductID
AND P.Name = N'Metal Plate 2'; Нито една заявка не среща грешката и двете произвеждат един и същ план за изпълнение:
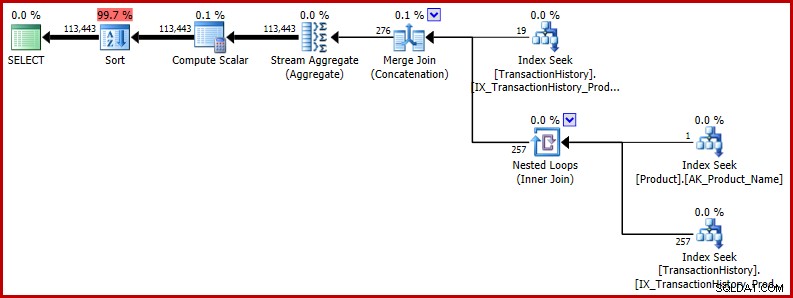
Тези T-SQL формулировки създават план за изпълнение с напълно последователни (и разумни) оценки.
Пример 5
Може да се чудите дали неточната оценка е важна. В представените дотук случаи не е, поне не директно. Проблеми възникват, когато грешката се появи в по-голяма заявка и неправилната оценка засяга решенията на оптимизатора другаде. Като минимално разширен пример, помислете за връщане на резултатите от нашата тестова заявка в произволен ред:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
)
ORDER BY NEWID(); -- New Планът за изпълнение показва, че неправилната оценка засяга по-късните операции. Например, това е основата за предоставянето на памет, запазено за сортирането:
Ако искате да видите по-реален пример за потенциалното въздействие на тази грешка, разгледайте този скорошен въпрос от Ричард Менсел на сайта за въпроси и отговори на SQLPerformance.com, answers.SQLPerformance.com.
Обобщение и заключителни мисли
Тази грешка се задейства, когато оптимизаторът извършва оценка на мощността за полусъединяване при специфични обстоятелства. Това е предизвикателна грешка за откриване и заобикаляне поради редица причини:
- Няма изричен синтаксис на T-SQL за определяне на полусъединяване, така че е трудно да се знае предварително дали конкретна заявка ще бъде уязвима към тази грешка.
- Оптимизаторът може да въведе полусъединяване при голямо разнообразие от обстоятелства, не всички от които са очевидни кандидати за полусъединяване.
- Проблемното полусъединяване често се трансформира в нещо друго чрез по-късна активност на оптимизатора, така че дори не можем да разчитаме, че в крайния план за изпълнение има операция за полусъединяване.
- Не всяка странно изглеждаща оценка на мощността е причинена от тази грешка. Наистина, много примери от този тип са очакван и безвреден страничен ефект от нормалната работа на оптимизатора.
- Грешната оценка на селективността на полусъединяване винаги ще бъде 90% или 100% от нейния вход, но това обикновено няма да съответства на мощността на таблица, използвана в плана. Освен това, използваната при изчислението входна мощност на полусъединяване може дори да не се вижда в крайния план за изпълнение.
- Обикновено има много начини за изразяване на една и съща логическа заявка в T-SQL. Някои от тях ще задействат грешката, докато други не.
Тези съображения затрудняват предлагането на практически съвети за откриване или заобикаляне на този бъг. Със сигурност си струва да проверите плановете за изпълнение за „възмутителни“ оценки и да разследвате заявки с производителност, която е много по-лоша от очакваната, но и двете може да имат причини, които не са свързани с тази грешка. Въпреки това си струва да проверите особено заявките, които включват дизюнкция на предикати и подзаявка. Както показват примерите в тази статия, това не е единственият начин да срещнете грешката, но очаквам тя да е често срещана.
Ако имате достатъчно късмет да използвате SQL Server 2014, с активиран новия оценител на мощността, може да успеете да потвърдите грешката, като ръчно проверите изхода на флаг за проследяване 2363 за фиксирана оценка на 100% селективност при полусъединяване, но това е едва ли е удобно. Естествено, няма да искате да използвате недокументирани флагове за проследяване в производствена система.
Докладът за грешка в User Voice за този проблем може да бъде намерен тук. Моля, гласувайте и коментирайте, ако искате този проблем да бъде проучен (и евентуално коригиран).



