SQL Server предлага два метода за събиране на диагностични данни и данни за отстраняване на неизправности относно натоварването, изпълнено срещу сървъра:SQL Trace и Extended Events. Започвайки от SQL Server 2012, внедряването на разширени събития предоставя сравними възможности за събиране на данни с SQL Trace и може да се използва за сравнения на режийните разходи, понесени от тези две функции. В тази статия ще разгледаме сравняването на „режимите на наблюдателя“, които възникват при използване на SQL Trace и разширени събития в различни конфигурации, за да определим въздействието върху производителността, което събирането на данни може да окаже върху нашето работно натоварване чрез използването на натоварване за повторение заснемане и разпределено възпроизвеждане.
Тестовата среда
Тестовата среда се състои от шест виртуални машини, един контролер на домейн, един сървър на SQL Server 2012 Enterprise Edition и четири клиентски сървъра с инсталирана на тях клиентска услуга Distributed Replay. За тази статия бяха тествани различни конфигурации на хоста и подобни резултати бяха резултат от трите различни конфигурации, които бяха тествани въз основа на съотношението на въздействие. Сървърът на SQL Server Enterprise Edition е конфигуриран с 4 vCPU и 4 GB RAM. Останалите пет сървъра са конфигурирани с 1 vCPU и 1GB RAM. Услугата Distributed Replay контролер се изпълнява на сървъра на SQL Server 2012 Enterprise Edition, тъй като изисква Enterprise лиценз за използване на повече от един клиент за възпроизвеждане.
Тестово натоварване
Тестовото работно натоварване, използвано за заснемането на повторно възпроизвеждане, е работното натоварване на AdventureWorks Books Online, което създадох миналата година за генериране на фалшиви работни натоварвания срещу SQL Server. Това работно натоварване използва примерните заявки от Books Online срещу семейството бази данни AdventureWorks и се управлява от PowerShell. Работното натоварване беше настроено на всеки от четирите клиента за повторно възпроизвеждане и се изпълняваше с четири общи връзки към SQL Server от всеки от клиентските сървъри, за да се генерира 1GB заснемане на проследяване на повторение. Проследяването на възпроизвеждане е създадено с помощта на шаблона TSQL_Replay от SQL Server Profiler, експортирано в скрипт и конфигурирано като трасиране от страна на сървъра към файл. След като файлът за проследяване на възпроизвеждане е заловен, той е предварително обработен за използване с разпределено възпроизвеждане и след това данните за възпроизвеждане се използват като работно натоварване за възпроизвеждане за всички тестове.
Възпроизвеждане на конфигурация
Операцията по възпроизвеждане е конфигурирана да използва конфигурация на стресов режим, за да управлява максималното количество натоварване срещу тестовия екземпляр на SQL Server. Освен това, конфигурацията използва намалена времева скала за мислене и свързване, която регулира съотношението на времето между началото на проследяването на възпроизвеждането и кога действително е възникнало събитие към момента, когато то се възпроизведе по време на операцията за възпроизвеждане, за да позволи събитията да бъдат възпроизведени в максимален мащаб. Скалата на напрежението за повторението също се конфигурира за spid. Подробностите за конфигурационния файл за операцията по възпроизвеждане бяха както следва:
<?xml version="1.0" encoding="utf-8"?>
<Options>
<ReplayOptions>
<Server>SQL2K12-SVR1</Server>
<SequencingMode>stress</SequencingMode>
<ConnectTimeScale>1</ConnectTimeScale>
<ThinkTimeScale>1</ThinkTimeScale>
<HealthmonInterval>60</HealthmonInterval>
<QueryTimeout>3600</QueryTimeout>
<ThreadsPerClient>255</ThreadsPerClient>
<EnableConnectionPooling>Yes</EnableConnectionPooling>
<StressScaleGranularity>spid</StressScaleGranularity>
</ReplayOptions>
<OutputOptions>
<ResultTrace>
<RecordRowCount>No</RecordRowCount>
<RecordResultSet>No</RecordResultSet>
</ResultTrace>
</OutputOptions>
</Options> По време на всяка от операциите на повторение броячите на производителността се събират на интервали от пет секунди за следните броячи:
- Процесор\% Процесорно време\_Общо
- SQL Server\SQL Statistics\Batch Requests/sec
Тези броячи ще се използват за измерване на общото натоварване на сървъра и характеристиките на пропускателната способност на всеки от тестовете за сравнение.
Тестови конфигурации
Общо седем различни конфигурации бяха тествани с Distributed Replay:
- Изходно ниво
- Проследяване от страна на сървъра
- Профил на сървъра
- Профилиране от разстояние
- Разширени събития към event_file
- Разширени събития към ring_buffer
- Разширени събития към event_stream
Всеки тест се повтаря три пъти, за да се гарантира, че резултатите са последователни в различните тестове и да се осигури среден набор от резултати за сравнение. За първоначалните базови тестове не беше конфигурирано допълнително събиране на данни за екземпляра на SQL Server, но колекциите от данни по подразбиране, които се доставят с SQL Server 2012, бяха оставени активирани:проследяването по подразбиране и сесията на събитието system_health. Това отразява общата конфигурация на повечето SQL сървъри, тъй като обикновено не се препоръчва да се деактивира сесията за проследяване по подразбиране или system_health поради предимствата, които предоставят на администраторите на бази данни. Този тест беше използван за определяне на общата изходна линия за сравнение с тестовете, при които се извършваше допълнително събиране на данни. Останалите тестове се основават на шаблона TSQL_SPs, който се доставя с SQL Server Profiler и събира следните събития:
- Одит на сигурността\Вход за одит
- Одит на сигурността\Изход от одит
- Сесии\ExistingConnection
- Съхранени процедури\RPC:Стартиране
- Съхранени процедури\SP:Завършено
- Съхранени процедури\SP:Стартиране
- Съхранени процедури\SP:StmtStarting
- TSQL\SQL:BatchStarting
Този шаблон е избран въз основа на работното натоварване, използвано за тестовете, което е предимно SQL партиди, които се улавят от SQL:BatchStarting събитие и след това редица събития, използващи различните методи на hierarchyid , които се улавят от SP:Starting , SP:StmtStarting и SP:Completed събития. Скрипт за проследяване от страна на сървъра беше генериран от шаблона с помощта на функционалността за експортиране в SQL Server Profiler и единствените промени, направени в скрипта, бяха задаване на maxfilesize параметър до 500 MB, активирайте преобръщане на файл за проследяване и посочете име на файл, в който е записана проследяването.
Третият и четвъртият тест използваха SQL Server Profiler за събиране на същите събития като проследяването от страна на сървъра за измерване на режийната ефективност на проследяването с помощта на приложението Profiler. Тези тестове бяха извършени с помощта на SQL Profiler локално на SQL Server и дистанционно от отделен клиент, за да се установи дали има разлика в режийните разходи, като Profiler работи локално или отдалечено.
Последните тестове, използвани Extended Events, събраха същите събития и същите колони въз основа на сесия на събитие, създадена с помощта на моя скрипт за преобразуване на Trace to Extended Events за SQL Server 2012. Тестовете включват оценка на event_file, ring_buffer и нов доставчик на стрийминг в SQL Server 2012 отделно, за да определи режийните разходи, които всяка цел може да наложи върху производителността на сървъра. Освен това сесията на събитието беше конфигурирана с опциите за буфер на паметта по подразбиране, но беше променена, за да посочи NO_EVENT_LOSS за EVENT_RETENTION_MODE опция за тестовете event_file и ring_buffer, за да съответстват на поведението на трасирането от страна на сървъра към файл, което също така гарантира липса на загуба на събитие.
Резултати
С едно изключение, резултатите от тестовете не бяха изненадващи. Базовият тест успя да изпълни натоварването за повторение за тринадесет минути и тридесет и пет секунди и средно 2345 пакетни заявки в секунда по време на тестовете. При работещ Trace от страна на сървъра, операцията по възпроизвеждане завърши за 16 минути и 40 секунди, което е 18,1% влошаване на производителността. Profiler Traces има най-лошо представяне като цяло и изисква 149 минути, когато Profiler се стартира локално на сървъра, и 123 минути и 20 секунди, когато Profiler е стартиран от разстояние, което дава съответно 90,8% и 87,6% влошаване на производителността. Тестовете с разширени събития се представиха най-добре, като отнеха 15 минути и 15 секунди за event_file и 15 минути и 40 секунди за целта ring_buffer, което доведе до 10,4% и 11,6% влошаване на производителността. Средните резултати за всички тестове са показани в Таблица 1 и диаграми на Фигура 2:
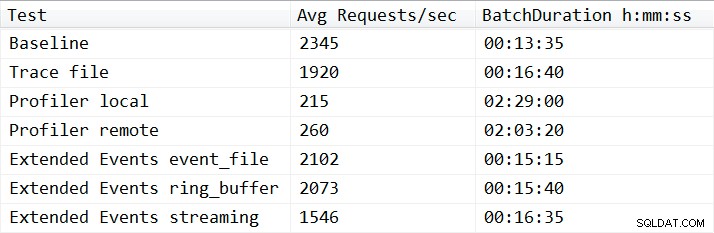
Таблица 1 – Средни резултати от всички тестове
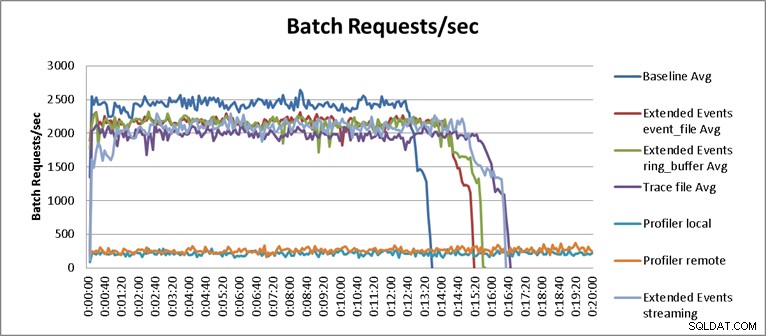
Фигура 2 – Диаграма с резултати
Тестът за поточно предаване на разширени събития не е съвсем справедлив резултат в контекста на извършените тестове и изисква малко повече обяснение, за да се разбере резултатът. От резултатите от таблицата можем да видим, че стрийминг тестовете за разширени събития завършиха за шестнадесет минути и тридесет и пет секунди, което се равнява на 34,1% влошаване на производителността. Въпреки това, ако увеличим диаграмата и променим нейния мащаб, както е показано на фигура 3, ще видим, че стриймингът е имал много по-голямо влияние върху производителността първоначално и след това започва да работи по начин, подобен на другите тестове за разширени събития :
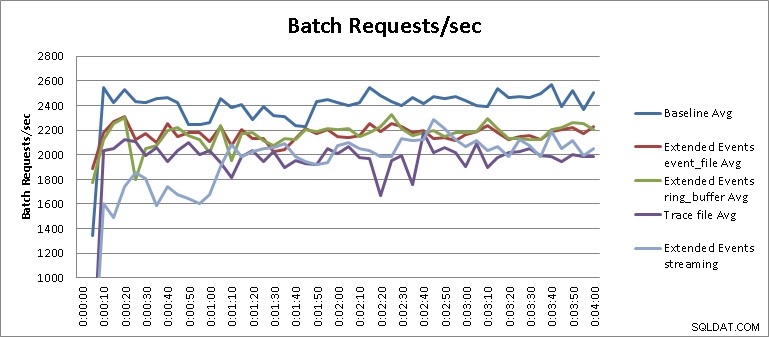
Фигура 3 – Увеличени резултати
Обяснението за това се намира в дизайна на новата цел за стрийминг на разширени събития в SQL Server 2012. Ако буферите на вътрешната памет за event_stream се запълнят и не се консумират от клиентското приложение достатъчно бързо, Database Engine ще прекъсне връзката на event_stream, за да предотвратите сериозно влияние върху производителността на сървъра. Това води до възникване на грешка в SQL Server 2012 Management Studio, подобна на грешката на фигура 4:
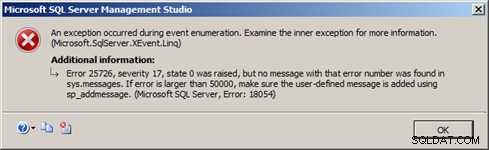
Фигура 4 – event_stream прекъснат от сървър
(Microsoft.SqlServer.XEvent.Linq)
Грешка 25726, сериозност 17, състояние 0 беше повдигнато, но не беше открито съобщение с този номер на грешка в sys.messages. Ако грешката е по-голяма от 50 000, уверете се, че дефинираното от потребителя съобщение е добавено чрез sp_addmessage.
(Microsoft SQL Server, грешка:18054)
Заключения
Всички методи за събиране на диагностични данни от SQL Server имат свързани с тях „режим на наблюдател“ и могат да повлияят на производителността на работно натоварване при голямо натоварване. За системи, работещи на SQL Server 2012, разширените събития осигуряват най-малко режийни разходи и предоставят подобни възможности за събития и колони като SQL Trace (някои събития в SQL Trace се събират в други събития в Extended Events). Ако SQL Trace е необходим за улавяне на данни за събития – което може да е така, докато инструментите на трети страни не бъдат прекодирани, за да използват данни за разширени събития – проследяването от страна на сървъра към файл ще доведе до най-малко разходи за производителност. SQL Server Profiler е инструмент, който трябва да се избягва на натоварени производствени сървъри, както се вижда от десетократното увеличение на продължителността и значителното намаляване на пропускателната способност за възпроизвеждането.
Въпреки че резултатите изглежда благоприятстват дистанционното стартиране на SQL Server Profiler, когато трябва да се използва Profiler, това заключение не може да бъде окончателно направено въз основа на специфичните тестове, които бяха извършени в този сценарий. Ще трябва да се извършат допълнителни тестове и събиране на данни, за да се определи дали резултатите от отдалеченото Profiler са резултат от по-ниско превключване на контекста на екземпляра на SQL Server или дали работата в мрежа между VM играе фактор за по-ниското въздействие върху производителността върху отдалеченото събиране. Целта на тези тестове беше да се покажат значителните разходи, които Profiler носи, независимо от това къде се изпълняваше Profiler. И накрая, потокът от събития на живо в разширени събития също има големи разходи, когато действително е свързан при събирането на данни, но както е показано в тестовете, Database Engine ще прекъсне връзката на поток на живо, ако изостане от събитията, за да предотврати сериозно въздействие върху производителност на сървъра.