Въведение
Съхраняването на данни е едно нещо; съхраняване смислено, полезно, правилно данните са съвсем други. Докато значението и полезността сами по себе си са субективни качества, коректността поне може да бъде логически дефинирана и наложена. Типовете вече гарантират, че числата са числа, а датите са дати, но не могат да гарантират, че теглото или разстоянието са положителни числа или предотвратяват припокриването на диапазони от дати. Ограниченията за кортежи, таблица и база данни прилагат правила към съхраняваните данни и отхвърлят стойности или комбинации от стойности, които не преминават проверка.
Ограниченията не правят други техники за валидиране на входа безполезни по никакъв начин, дори когато тестват едни и същи твърдения. Времето, прекарано в опити и неуспех за съхраняване на невалидни данни, е загубено време. Съобщения за нарушение, като assert в системите и езиците за приложно програмиране, разкрива само първия проблем с първия запис на кандидата много по-подробно от всеки, който не е свързан непосредствено с нуждите на базата данни. Но що се отнася до коректността на данните, ограниченията са законови, за добро или за лошо; всичко друго е съвет.
На кортежи:Not Null, Default и Check
Ненулевите ограничения са най-простата категория. Кортежът трябва да има стойност за ограничен атрибут или казано по друг начин, наборът от разрешени стойности за колоната вече не включва празния набор. Без стойност означава липса на кортеж:вмъкването или актуализацията се отхвърлят.
Защитата срещу нулеви стойности е толкова лесна, колкото да декларирате column_name COLUMN_TYPE NOT NULL в CREATE TABLE или ADD COLUMN . Нулевите стойности причиняват цели категории проблеми между базата данни и крайните потребители, така че рефлексивното дефиниране на ненулеви ограничения върху която и да е колона без основателна причина за разрешаване на null е добър навик за навлизане.
Предоставянето на стойност по подразбиране, ако нищо не е посочено (чрез пропускане или изричен NULL). ) във вмъкване или актуализация не винаги се счита за ограничение, тъй като кандидат-записите се променят и съхраняват, вместо да се отхвърлят. В много СУБД стойностите по подразбиране могат да бъдат генерирани от функция, въпреки че MySQL не позволява дефинирани от потребителя функции за тази цел.
Всяко друго правило за валидиране, което зависи само от стойностите в рамките на един кортеж, може да бъде приложено като CHECK ограничение. В известен смисъл NOT NULL сама по себе си е съкращение за CHECK (column_name IS NOT NULL); съобщението за грешка, получено в нарушение, прави по-голямата част от разликата. CHECK , обаче, може да приложи и наложи истинността на всеки булев предикат върху един кортеж. Например, таблица, съхраняваща географски местоположения, трябва CHECK (latitude >= -90 AND latitude < 90) , и по подобен начин за дължина между -180 и 180 -- или, ако е налично, използвайте и потвърдете GEOGRAPHY тип данни.
На таблици:Уникални и изключване
Ограниченията на ниво таблица тестват кортежи един срещу друг. При уникално ограничение само един запис може да има даден набор от стойности за ограничените колони. Нулирането може да причини проблеми тук, тъй като NULL никога не е равно на нищо друго, до и включително NULL себе си. Уникално ограничение за (batman, robin) следователно позволява безкрайни копия на всеки Батман без Робин.
Ограниченията за изключване се поддържат само в PostgreSQL и DB2, но запълват много полезна ниша:те могат да предотвратят припокривания. Посочете ограничените полета и операциите, чрез които всяко от тях ще бъде оценено, и нов запис ще бъде приет само ако нито един съществуващ запис не се сравнява успешно с всяко поле и операция. Например, schedules таблицата може да бъде конфигурирана да отхвърля конфликти:
-- text, int, etc. comparisons in exclusion constraints require this-- Postgres extensionCREATE EXTENSION btree_gist;CREATE TABLE schedules ( schedule_id SERIAL NOT NULL PRIMARY KEY, room_number TEXT NOT NULL, -- a range of TIMESTAMP WITH TIME ZONE provides both start and end duration TSTZRANGE, -- table-level constraints imply an index, since otherwise they'd -- have to search the entire table to validate a candidate record; -- GiST (generalized search tree) indexes are usually used in -- Postgres EXCLUDE USING GIST ( room_number WITH =, duration WITH && ));INSERT INTO schedules (room_number, duration)VALUES ('32A', '[2020-08-20T10:00:00Z,2020-08-20T11:00:00Z)');-- the same time in a different room: acceptedINSERT INTO schedules (room_number, duration)VALUES ('32B', '[2020-08-20T10:00:00Z,2020-08-20T11:00:00Z)');-- a half-hour overlap for an already-scheduled room: rejectedINSERT INTO schedules (room_number, duration)VALUES ('32A', '[2020-08-20T10:30:00Z,2020-08-20T11:30:00Z)');
Upsert операции като ON CONFLICT на PostgreSQL клауза или ON DUPLICATE KEY UPDATE на MySQL използвайте ограничение на ниво таблица за откриване на конфликти. И като ненулеви ограничения могат да бъдат изразени като CHECK ограничения, уникално ограничение може да бъде изразено като ограничение за изключване на равенството.
Първичният ключ
Уникалните ограничения имат особено полезен специален случай. С допълнително ненулево ограничение за уникалната колона или колони, всеки запис в таблицата може да бъде единично идентифициран чрез своите стойности за ограничените колони, които заедно се наричат ключ . Множество кандидат-ключове могат да съществуват едновременно в таблица, като users все още понякога има различен уникален и ненулев email s и username с; но декларирането на първичен ключ установява единен критерий, чрез който записите са публично и изключително известни. Някои RDBMS дори организират редове на страници по първичен ключ, наречен за тази цел клъстериран индекс , за да направите търсенето по стойности на първичен ключ възможно най-бързо.
Има два вида първичен ключ. Естествен ключ се дефинира върху колона или колони, „естествено“ включени в данните на таблицата, докато сурогатен или синтетичен ключ се измисля единствено с цел да стане ключ. Естествените ключове изискват грижи - повече неща могат да се променят, отколкото дизайнерите на бази данни често кредитират, от имена до схеми за номериране. Таблица за справка, съдържаща имена на държави и региони, може да използва съответните им кодове по ISO 3166 като безопасен естествен първичен ключ, но users таблица с естествен ключ, базиран на променящи се стойности като имена или имейл адреси, предизвиква проблеми. Когато се съмнявате, създайте сурогатен ключ.
Ако естествен ключ обхваща множество колони, винаги трябва да се има предвид сурогатен ключ, тъй като ключовете с няколко колони изискват повече усилия за управление. Ако естественият ключ подхожда обаче, колоните трябва да бъдат подредени с нарастваща специфичност, точно както са в индексите:код на държавата след това регионален код, а не обратното.
Сурогатният ключ исторически е бил една колона с цяло число или BIGINT където милиарди в крайна сметка ще бъдат разпределени. Релационните бази данни могат автоматично да попълват сурогатните ключове със следващото цяло число в поредица, функция, която обикновено се нарича SERIAL или IDENTITY .
Автоматично нарастващият числов брояч не е лишен от недостатъци:добавянето на записи с предварително генерирани ключове може да причини конфликти и ако последователните стойности са изложени на потребителите, за тях е лесно да отгатнат какви други валидни ключове могат да бъдат. Универсалните уникални идентификатори или UUID избягват тези слабости и са се превърнали в често срещан избор за сурогатни ключове, въпреки че те също са много по-големи в страницата от обикновено число. Типовете UUID v1 (базирани на MAC адрес) и v4 (псевдослучайни) се използват най-често.
В базата данни:Външни ключове
Релационните бази данни прилагат само един клас ограничение за множество таблици,
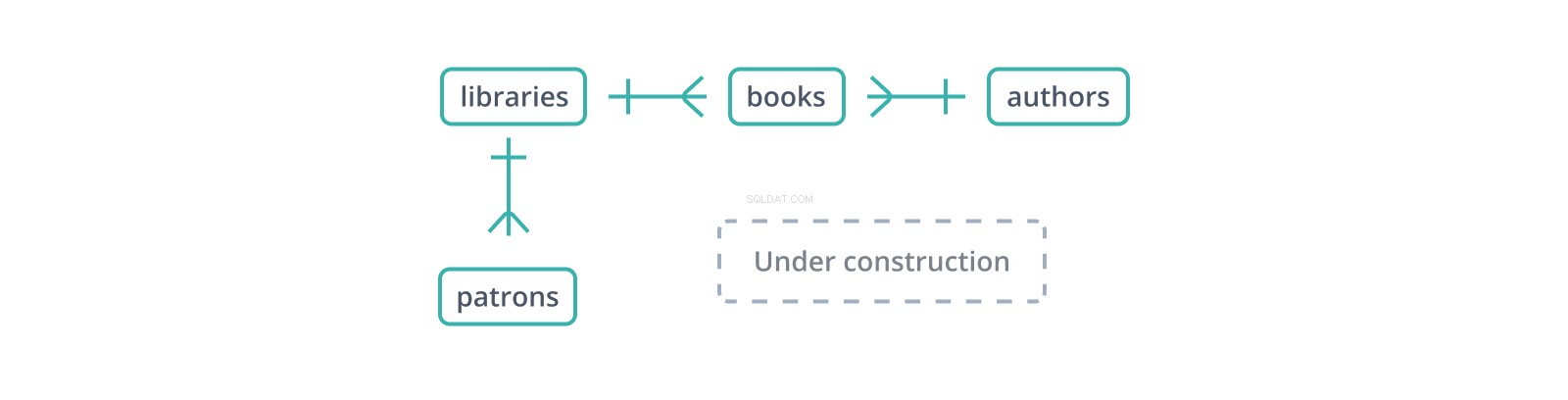
Тази неформална "диаграма на взаимоотношенията между субекти" или ERD показва началото на схема за база данни от библиотеки и техните колекции и покровители. Всеки ръб представлява връзка между таблиците, които свързва. | Глифът показва един запис отстрани, докато глифът "пачи крак" представлява множество:библиотеката съдържа много книги и има много покровители.
Външният ключ е копие на първичния ключ на друга таблица, колона за колона (точка в полза на сурогатните ключове:само една колона за копиране и препратка), със стойности, свързващи записи в тази таблица с "родителски" записи в нея. В схемата по-горе, books таблицата поддържа library_id външен ключ към libraries , които съдържат книги и author_id до authors , които ги пишат. Но какво се случва, ако книга се вмъкне с author_id който не съществува в authors ?
Ако външният ключ не е ограничен – т.е. това е просто друга колона или колони – книгата може да има автор, който не съществува. Това е проблем:ако някой се опита да последва връзката между books и authors , те не стигат до никъде. Ако authors.author_id е серийно цяло число, има също така възможността никой да не забележи до фалшивия author_id в крайна сметка е назначен и вие получавате конкретно копие на Дон Кихот първо се приписва на никой непознат, а след това на Пиер Менар, като Мигел Сервантес не може да бъде намерен никъде.
Ограничаването на външния ключ не може да предотврати неправилно приписване на книга в случай на погрешен author_id насочете към съществуващ запис в authors , така че другите проверки и тестове остават важни. Въпреки това наборът от съществуващи стойности на външния ключ почти винаги е малко подмножество от възможните стойности на външния ключ, така че ограниченията на външния ключ ще уловят и предотвратят повечето грешни стойности. С ограничение за външен ключ, Quixote с несъществуващ автор ще бъде отхвърлен вместо записан.
От тук ли идва „Relational“ в „Relational Database“?
Външните ключове създават връзки между таблиците, но таблиците, каквито ги познаваме, са математически отношения сред наборите от възможни стойности за всеки атрибут. Единичен кортеж свързва стойност за колона A със стойност за колона B и нататък. В оригиналния документ на E.F. Codd се използва „релационен“ в този смисъл.
Това не доведе до край на объркване и вероятно ще продължи да го прави завинаги.
За определени стойности на правилните
Има много повече начини, по които данните могат да бъдат неправилни, отколкото адресирани тук. Ограниченията помагат, но дори и те са толкова гъвкави; много често срещани спецификации в таблицата, като ограничение от две или по-високо за броя пъти, в които дадена стойност може да се появи в колона, могат да бъдат наложени само с тригери.
Но има и начини, по които самата структура на таблицата може да доведе до несъответствия. За да предотвратим това, ще трябва да маршалираме както първичния, така и външния ключ не само за дефиниране и валидиране, но и за нормализиране връзките между таблиците. Първо обаче, ние едва надраскахме повърхността на това как връзките между таблиците определят структурата на самата база данни.