IRI вече предоставя и функции за размито търсене, както в своята безплатна база данни и инструменти за профилиране на плосък файл, така и като налични библиотеки с функции на полето в IRI CoSort, FieldShield и Voracity, за да подобри качеството на данните, сигурността и възможностите на MDM. Това е първата от поредица статии за решенията за размито търсене на IRI, обхващащи прилагането им за подобряване на качеството на данните.
Въведение
Истинността или надеждността на данните на една от големите „V“ думи (заедно с обем, разнообразие, скорост и стойност), за които IRI и др. говорят в контекста на управлението на данни и корпоративна информация. Като цяло IRI дефинира съмнителните данни като притежаващи един или повече от следните атрибути:
- Ниско качество, защото е непоследователно, неточно или непълно
- Двусмислено (мисля за MDM), неточно (неструктурирано) или измамно (социални медии)
- Пристрастен (въпрос от анкетата), шумен (излишен или замърсен) или необичаен (отклонения)
- Невалидни по някаква друга причина (данните правилни ли са и точни за предназначението им?)
- Опасно – съдържа ли информация за лични данни или тайни и дали е правилно маскирана, обратима и т.н.?
Тази статия се фокусира само върху нови решения за размито търсене на първия проблем, качеството на данните. Други статии в този блог обсъждат как софтуерът на IRI се справя с другите четири проблема с достоверността; помолете за помощ при намирането им, ако не можете.
Относно размитото търсене
Размитите търсения намират думи или фрази (стойности), които са подобни, но не непременно идентични с други думи или фрази (стойности). Този тип търсене има много приложения, като например намиране на грешки в последователността, правописни грешки, транспонирани знаци и други, които ще разгледаме по-късно.
Извършването на размито търсене на приблизителни думи или фрази може да помогне за намирането на данни, които може да са дубликати на по-рано съхранени данни. Въпреки това въвеждането от потребителя или автоматичната корекция може да са променили данните по някакъв начин, за да направят записите да изглеждат независими.
Останалата част от статията ще обхване четири функции за размито търсене, които IRI сега поддържа, как да ги използвате, за да претърсите данните си и да върнете тези записи, приближаващи стойността на търсенето.
1. Левещайна
Алгоритъмът на Левенщайн работи, като взема две думи или фрази и брои колко стъпки за редактиране ще са необходими, за да превърне една дума или фраза в друга. Колкото по-малко стъпки ще предприеме, толкова по-вероятно е думата или фразата да съвпаднат. Стъпките, които функцията Левенщайн може да предприеме, са:
- Вмъкване на знак в думата или фразата
- Изтриване на знак от думата или фразата
- Замяна на един знак в дума или фраза с друг
Следва програма CoSort SortCL (скрипт за работа), която демонстрира как да използвате функцията за размито търсене на Левенщайн:
/INFILE=LevenshteinSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=LevenshteinOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(FS_RESULT=fs_levenshtein(NAME, "Barney Oakley"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE FS_RESULT GT 50
Има две части, които трябва да се използват за получаване на желания изход.
FS_Result=fs_levenshtein(NAME, "Barney Oakley")
Този ред извиква функцията fs_levenshtein и съхранява резултата в полето FS_RESULT. Функцията приема два входни параметъра:
- Полето за стартиране на размитото търсене (NAME в нашия пример)
- Низът, с който ще се сравнява полето за въвеждане („Barney Oakley“ в нашия пример).
/INCLUDE WHERE FS_RESULT GT 50
Този ред сравнява полето FS_RESULT и проверява дали е по-голямо от 50, след което се извеждат само записи с FS_RESULT повече от 50. По-долу е показан изходът от нашия пример.

Както показва изходът, този тип търсене е полезно за намиране на:
- Свързани имена
- Шум
- Правописни грешки
- Транспонирани знаци
- Грешки при транскрипция
- Грешки при въвеждане
Функцията Levenshtein е полезна и за идентифициране на често срещани грешки при въвеждане на данни. От четирите алгоритъма обаче отнема най-дълго време за изпълнение, тъй като сравнява всеки знак в единия низ с всеки знак в другия.
2. Коефициент на зара
Коефициентът на зарове или алгоритъмът на заровете разделя думите или фразите на двойки знаци, сравнява тези двойки и брои съвпаденията. Колкото повече съвпадения имат думите, толкова по-вероятно е самата дума да съвпадне.
Следният скрипт SortCL демонстрира функцията за размито търсене с коефициент на зарове.
/INFILE=DiceSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=DiceOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(FS_RESULT=fs_dice(NAME, "Robert Thomas Smith"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE FS_RESULT GT 50
Има две части, които трябва да се използват, за да ни дадат желания резултат.
FS_Result=fs_dice(NAME, "Robert Thomas Smith")
Този ред извиква функцията fs_dice и съхранява резултата в полето FS_RESULT. Функцията приема два входни параметъра:
- Полето за стартиране на размитото търсене (NAME в нашия пример).
- Низът, с който ще се сравнява полето за въвеждане („Робърт Томас Смит“ в нашия пример).
/INCLUDE WHERE FS_RESULT GT 50
Този ред сравнява полето FS_RESULT и проверява дали е по-голямо от 50, след което се извеждат само записи с FS_RESULT повече от 50. По-долу е показан изходът от нашия пример.
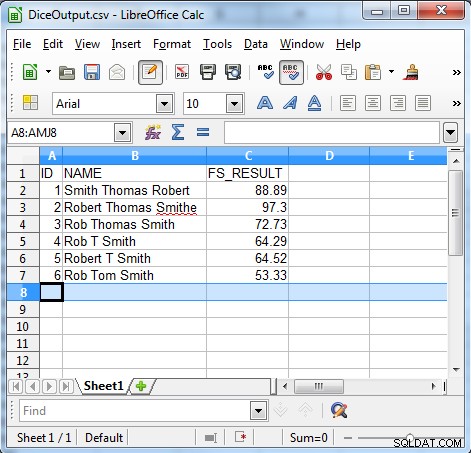
Както показва изходът, алгоритъмът на коефициента на зарове е полезен за намиране на непоследователни данни, като например:
- Грешки в последователността
- Неволни корекции
- Прякори
- Инициали и прякори
- Непредвидимо използване на инициали
- Локализация
Алгоритъмът на заровете е по-бърз от Levenshtein, но може да стане по-малко точен, когато има много прости грешки, като печатни грешки.
3. Метафон и 4. Soundex
Алгоритмите Metaphone и Soundex сравняват думи или фрази въз основа на техните фонетични звуци. Soundex прави това, като чете думата или фразата и разглежда отделни знаци, докато Metaphone разглежда както отделни знаци, така и групи от знаци. След това и двете дават кодове въз основа на изписването и произношението на думата.
Следният скрипт SortCL демонстрира функциите за търсене на Soundex и Metasphone:
/INFILE=SoundexSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=SoundexOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(SE_RESULT=fs_soundex(NAME, "John"), POSITION=3, SEPARATOR=",") /FIELD=(MP_RESULT=fs_metaphone(NAME, "John"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE (SE_RESULT GT 0) OR (MP_RESULT GT 0)
Във всеки случай има три части, които трябва да се използват, за да ни дадат желания резултат.
SE_RESULT=fs_soundex(NAME, "John") MP_RESULT=fs_metaphone(NAME, "John")
Редът извиква функцията и съхранява резултата в полето РЕЗУЛТАТ. И двете функции приемат два входни параметъра:
- Полето за стартиране на размитото търсене (NAME в нашия пример)
- Xstring, с който полето за въвеждане ще бъде сравнено („John“ в нашия пример)
/INCLUDE WHERE (SE_RESULT GT 0) OR (MP_RESULT GT 0)
Този ред сравнява полетата SE_RESULT и MP_RESULT и проверява и връща реда, ако едното е по-голямо от 0.
Soundex връща или 100 за съвпадение, или 0, ако не е съвпадение. Metaphone има по-конкретни резултати и връща 100 за силно съвпадение, 66 за нормално съвпадение и 33 за второстепенно съвпадение.
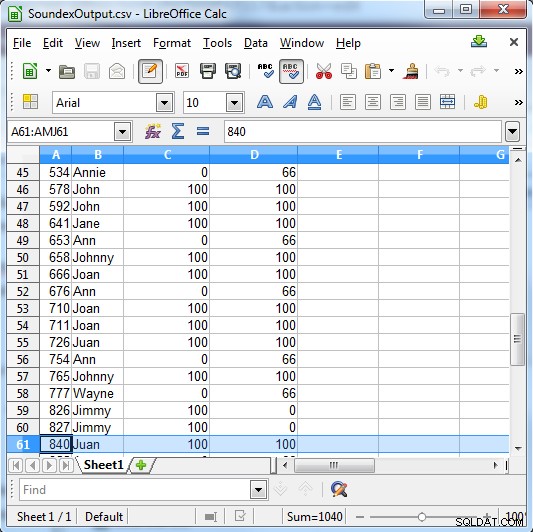
Колона C показва резултатите от Soundex. Сколона Г показва резултатите от метафона
Както показва изходът, този тип търсене е полезно за намиране на:
- Фонетични грешки
Моля, изпратете отзиви за тази статия по-долу и ако се интересувате от използването на тези функции, моля, свържете се с вашия представител на IRI. Вижте следващата ни статия за използването на тези алгоритми в съветника за консолидиране на данни (качество) на IRI Workbench.