Миналия октомври предизвикахме аудиторията на PyBites да направи уеб приложение за по-добро навигиране в емисията Daily Python Tip. В тази статия ще споделя какво построих и научих по пътя.
В тази статия ще научите:
- Как да клонирате репо проекта и да настроите приложението.
- Как да използвам API на Twitter чрез модула Tweepy за зареждане в туитовете.
- Как да използвам SQLAlchemy за съхраняване и управление на данните (съвети и хештагове).
- Как да създадете просто уеб приложение с Bottle, микро уеб рамка, подобна на Flask.
- Как да използвам рамката на pytest за добавяне на тестове.
- Как насоките на Better Code Hub доведоха до по-поддържаем код.
Ако искате да следвате, четейки кода в детайли (и евентуално да допринесете), предлагам ви да разделите репото. Да започваме.
Настройка на проекта
Първо, Пространствата от имена са една страхотна идея така че нека да свършим работата си във виртуална среда. Използвайки Anaconda, го създавам така:
$ virtualenv -p <path-to-python-to-use> ~/virtualenvs/pytip
Създайте производствена и тестова база данни в Postgres:
$ psql
psql (9.6.5, server 9.6.2)
Type "help" for help.
# create database pytip;
CREATE DATABASE
# create database pytip_test;
CREATE DATABASE
Ще ни трябват идентификационни данни, за да се свържем с базата данни и API на Twitter (първо създайте ново приложение). Според най-добрите практики конфигурацията трябва да се съхранява в средата, а не в кода. Поставете следните env променливи в края на ~/virtualenvs/pytip/bin/activate , скриптът, който обработва активирането/деактивирането на вашата виртуална среда, като не забравяйте да актуализирате променливите за вашата среда:
export DATABASE_URL='postgres://postgres:password@localhost:5432/pytip'
# twitter
export CONSUMER_KEY='xyz'
export CONSUMER_SECRET='xyz'
export ACCESS_TOKEN='xyz'
export ACCESS_SECRET='xyz'
# if deploying it set this to 'heroku'
export APP_LOCATION=local
Във функцията за деактивиране на същия скрипт ги деактивирам, така че да държим нещата извън обхвата на обвивката, когато деактивираме (напускаме) виртуалната среда:
unset DATABASE_URL
unset CONSUMER_KEY
unset CONSUMER_SECRET
unset ACCESS_TOKEN
unset ACCESS_SECRET
unset APP_LOCATION
Сега е подходящ момент да активирате виртуалната среда:
$ source ~/virtualenvs/pytip/bin/activate
Клонирайте репо и с активирана виртуална среда инсталирайте изискванията:
$ git clone https://github.com/pybites/pytip && cd pytip
$ pip install -r requirements.txt
След това импортираме колекцията от туитове с:
$ python tasks/import_tweets.py
След това проверете дали таблиците са създадени и туитовете са добавени:
$ psql
\c pytip
pytip=# \dt
List of relations
Schema | Name | Type | Owner
--------+----------+-------+----------
public | hashtags | table | postgres
public | tips | table | postgres
(2 rows)
pytip=# select count(*) from tips;
count
-------
222
(1 row)
pytip=# select count(*) from hashtags;
count
-------
27
(1 row)
pytip=# \q
Сега нека стартираме тестовете:
$ pytest
========================== test session starts ==========================
platform darwin -- Python 3.6.2, pytest-3.2.3, py-1.4.34, pluggy-0.4.0
rootdir: realpython/pytip, inifile:
collected 5 items
tests/test_tasks.py .
tests/test_tips.py ....
========================== 5 passed in 0.61 seconds ==========================
И накрая стартирайте приложението Bottle с:
$ python app.py
Прегледайте https://localhost:8080 и voilà:трябва да видите съветите, сортирани според популярността. Щраквайки върху връзка с хештаг вляво или с помощта на полето за търсене, можете лесно да ги филтрирате. Тук виждаме пандите съвети например:
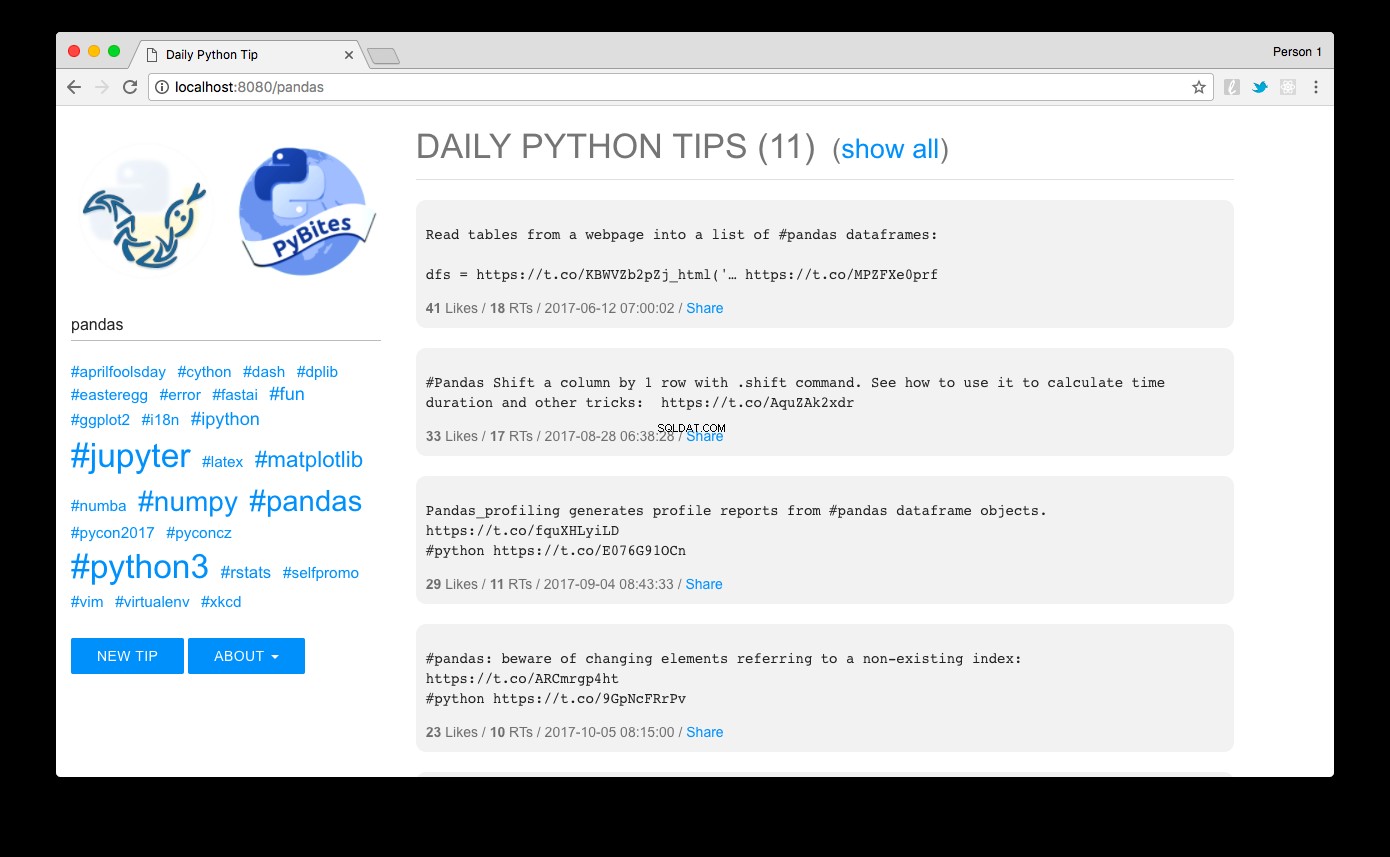
Дизайнът, който направих с MUI – лека CSS рамка, която следва указанията на Google Material Design.
Подробности за внедряването
БД и SQLAlchemy
Използвах SQLAlchemy за взаимодействие с DB, за да предотвратя необходимостта от писане на много (излишен) SQL.
В tips/models.py , дефинираме нашите модели - Hashtag и Tip - че SQLAlchemy ще преобразува в DB таблици:
from sqlalchemy import Column, Sequence, Integer, String, DateTime
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Hashtag(Base):
__tablename__ = 'hashtags'
id = Column(Integer, Sequence('id_seq'), primary_key=True)
name = Column(String(20))
count = Column(Integer)
def __repr__(self):
return "<Hashtag('%s', '%d')>" % (self.name, self.count)
class Tip(Base):
__tablename__ = 'tips'
id = Column(Integer, Sequence('id_seq'), primary_key=True)
tweetid = Column(String(22))
text = Column(String(300))
created = Column(DateTime)
likes = Column(Integer)
retweets = Column(Integer)
def __repr__(self):
return "<Tip('%d', '%s')>" % (self.id, self.text)
В tips/db.py , ние импортираме тези модели и сега е лесно да работим с DB, например да взаимодействаме с Hashtag модел:
def get_hashtags():
return session.query(Hashtag).order_by(Hashtag.name.asc()).all()
И:
def add_hashtags(hashtags_cnt):
for tag, count in hashtags_cnt.items():
session.add(Hashtag(name=tag, count=count))
session.commit()
Направете заявка за API на Twitter
Трябва да извлечем данните от Twitter. За това създадох tasks/import_tweets.py . Опаковах това под задачи защото трябва да се изпълнява в ежедневен cronjob, за да се търсят нови съвети и да се актуализират статистики (брой харесвания и ретуитове) на съществуващи туитове. За по-голяма простота пресъздавам таблиците всеки ден. Ако започнем да разчитаме на FK релациите с други таблици, определено трябва да изберем инструкциите за актуализиране пред delete+add.
Използвахме този скрипт в настройката на проекта. Нека видим какво прави по-подробно.
Първо, създаваме обект на сесия на API, който предаваме на tweepy.Cursor. Тази функция на приложния програмен интерфейс (API) е наистина хубава:тя се занимава с пагинация, итерация през времевата линия. За количеството съвети - 222 по времето, когато пиша това - наистина е бързо. exclude_replies=True и include_rts=False аргументите са удобни, защото искаме само собствените туитове на Daily Python Tip (не повторно туитове).
Извличането на хештагове от съветите изисква много малко код.
Първо, дефинирах регулярен израз за маркер:
TAG = re.compile(r'#([a-z0-9]{3,})')
След това използвах findall за да получите всички маркери.
Предадох ги на collections.Counter, който връща обект като dict с тагове като ключове и се брои като стойности, подредени в низходящ ред по стойности (най-често срещаните). Изключих твърде често срещания маркер на Python, който би изкривил резултатите.
def get_hashtag_counter(tips):
blob = ' '.join(t.text.lower() for t in tips)
cnt = Counter(TAG.findall(blob))
if EXCLUDE_PYTHON_HASHTAG:
cnt.pop('python', None)
return cnt
И накрая, import_* функции в tasks/import_tweets.py направете действителното импортиране на туитовете и хештаговете, като извикате add_* DB методи на съветите директория/пакет.
Направете просто уеб приложение с Bottle
С тази предварителна работа, правенето на уеб приложение е изненадващо лесно (или не е толкова изненадващо, ако сте използвали Flask преди).
Първо се запознайте с бутилка:
Bottle е бърза, проста и лека WSGI микро уеб рамка за Python. Той се разпространява като модул с един файл и няма други зависимости освен стандартната библиотека на Python.
Хубаво. Полученото уеб приложение се състои от <30 LOC и може да бъде намерено в app.py.
За това просто приложение е необходим само един метод с допълнителен аргумент за маркер. Подобно на Flask, маршрутизирането се обработва с декоратори. Ако се извика с етикет, той филтрира съветите върху етикета, в противен случай ги показва всички. Декораторът на изглед дефинира шаблона, който да се използва. Подобно на Flask (и Django) ние връщаме dict за използване в шаблона.
@route('/')
@route('/<tag>')
@view('index')
def index(tag=None):
tag = tag or request.query.get('tag') or None
tags = get_hashtags()
tips = get_tips(tag)
return {'search_tag': tag or '',
'tags': tags,
'tips': tips}
Съгласно документацията, за да работите със статични файлове, добавяте този фрагмент в горната част, след импортирането:
@route('/static/<filename:path>')
def send_static(filename):
return static_file(filename, root='static')
И накрая, искаме да сме сигурни, че работим само в режим за отстраняване на грешки на localhost, следователно APP_LOCATION env променлива, която дефинирахме в настройката на проекта:
if os.environ.get('APP_LOCATION') == 'heroku':
run(host="0.0.0.0", port=int(os.environ.get("PORT", 5000)))
else:
run(host='localhost', port=8080, debug=True, reloader=True)
Шаблони за бутилки
Bottle идва с бърз, мощен и лесен за научаване вграден шаблонен двигател, наречен SimpleTemplate.
В поддиректорията views дефинирах header.tpl , index.tpl и footer.tpl . За облака от маркери използвах някакъв прост вграден CSS, увеличаващ размера на маркера по брой, вижте header.tpl :
% for tag in tags:
<a style="font-size: {{ tag.count/10 + 1 }}em;" href="/{{ tag.name }}">#{{ tag.name }}</a>
% end
В index.tpl преглеждаме съветите:
% for tip in tips:
<div class='tip'>
<pre>{{ !tip.text }}</pre>
<div class="mui--text-dark-secondary"><strong>{{ tip.likes }}</strong> Likes / <strong>{{ tip.retweets }}</strong> RTs / {{ tip.created }} / <a href="https://twitter.com/python_tip/status/{{ tip.tweetid }}" target="_blank">Share</a></div>
</div>
% end
Ако сте запознати с Flask и Jinja2, това трябва да изглежда много познато. Вграждането на Python е още по-лесно, с по-малко въвеждане—(% ... срещу {% ... %} ).
Всички css, изображения (и JS, ако го използваме) отиват в статичната подпапка.
И това е всичко, което трябва да направите, за да направите основно уеб приложение с Bottle. След като правилно дефинирате слоя данни, става доста лесно.
Добавяне на тестове с pytest
Сега нека направим този проект малко по-стабилен, като добавим някои тестове. Тестването на DB изискваше малко повече ровене в рамката на pytest, но накрая използвах декоратора pytest.fixture, за да настроя и съборя база данни с някои тестови туитове.
Вместо да извикам API на Twitter, използвах някои статични данни, предоставени в tweets.json .И вместо да използвате живата БД, в tips/db.py , проверявам дали pytest е повикващият (sys.argv[0] ). Ако е така, използвам тестовата БД. Вероятно ще преработя това, защото Bottle поддържа работа с конфигурационни файлове.
Частта с хештаг беше по-лесна за тестване (test_get_hashtag_counter ), защото мога просто да добавя някои хештагове към многоредов низ. Не са необходими осветителни тела.
Качеството на кода има значение – Better Code Hub
Better Code Hub ви напътства в писането, добре, по-добър код. Преди да напише тестовете, проектът получи 7:
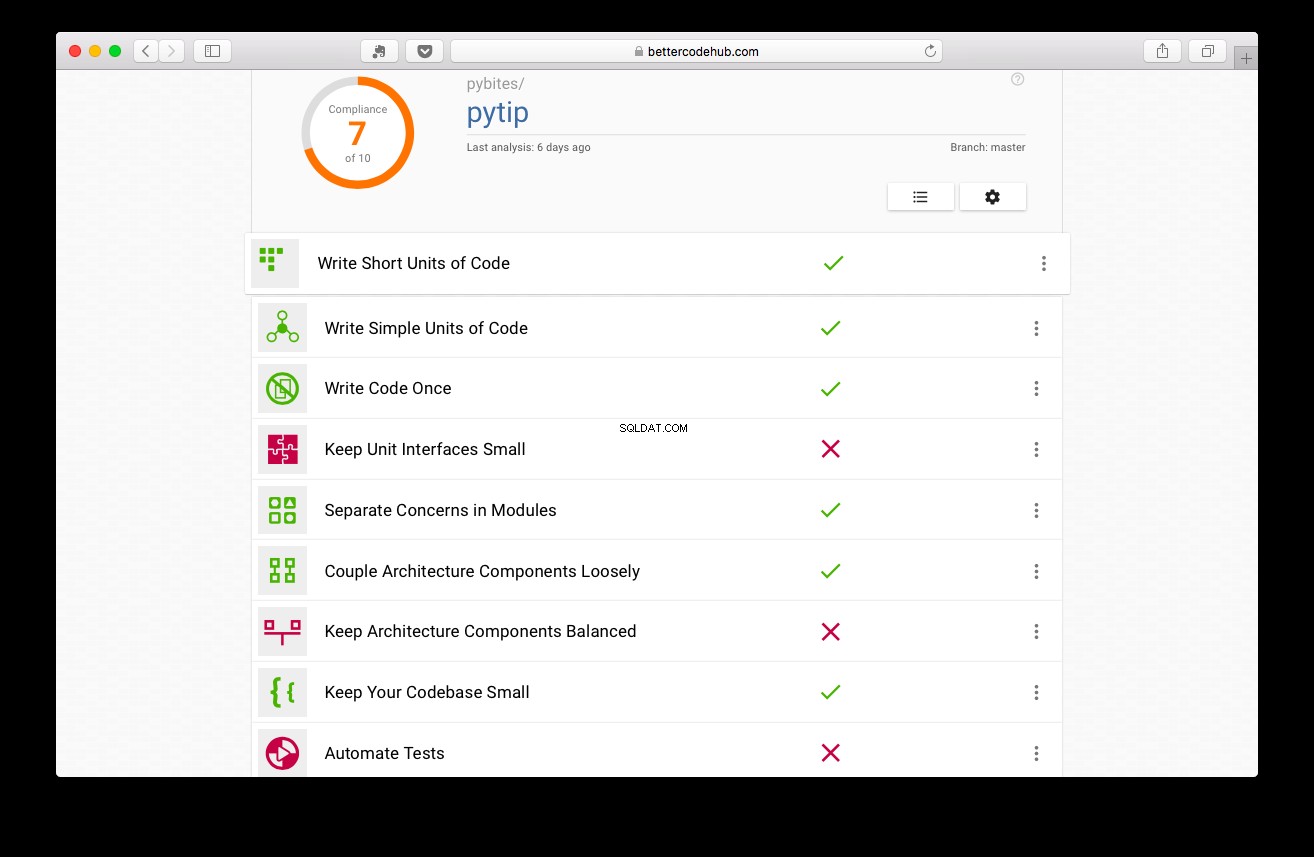
Не е лошо, но можем да направим по-добре:
-
Направих го до 9, като направих кода по-модулен, извадих логиката на DB от app.py (уеб приложение), поставих го в папката/пакета tips (рефакторинг 1 и 2)
-
След това с проведените тестове проектът получи 10:
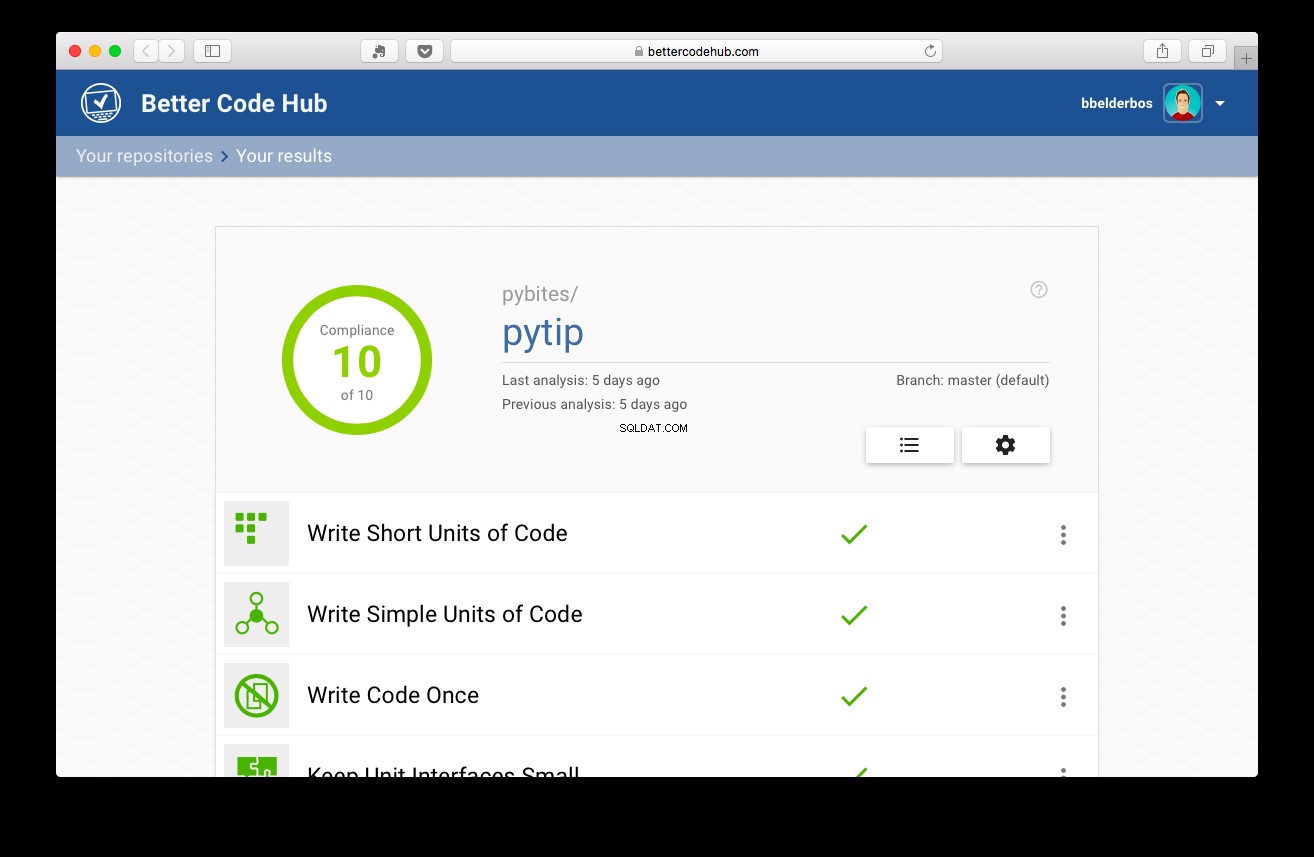
Заключение и учене
Нашето Code Challenge #40 предложи някои добри практики:
- Създадох полезно приложение, което може да бъде разширено (искам да добавя API).
- Използвах някои страхотни модули, които си заслужава да бъдат проучени:Tweepy, SQLAlchemy и Bottle.
- Научих още малко pytest, защото имах нужда от приспособления за тестване на взаимодействието с DB.
- Преди всичко, че трябваше да направи кода тестуем, приложението стана по-модулно, което го направи по-лесно за поддръжка. Better Code Hub беше от голяма помощ в този процес.
- Разположих приложението на Heroku, използвайки нашето ръководство стъпка по стъпка.
Ние ви предизвикваме
Най-добрият начин да научите и подобрите своите умения за кодиране е да практикувате. В PyBites затвърдихме тази концепция, като организирахме предизвикателства с кода на Python. Вижте нашата растяща колекция, разклонете репо и вземете кодиране!
Уведомете ни, ако изградите нещо страхотно, като направите заявка за изтегляне на вашата работа. Виждали сме как хора наистина се разтягат през тези предизвикателства, както и ние.
Приятно кодиране!



