За да внедрите многоезична поддръжка във вашия модел на данни, не е необходимо да изобретявате колелото. Тази статия ще ви покаже различните начини да го направите и ще ви помогне да изберете този, който работи най-добре за вас.
Концепцията за локализация е жизненоважна за разработването на софтуерно приложение, особено когато обхватът на това приложение е глобален. Поддръжката на множество езици е основният аспект, който трябва да се вземе предвид; дизайн на база данни, който поддържа многоезично приложение, ви позволява да разнообразите целевите си пазари и по този начин да достигнете до много повече клиенти. Освен това такъв дизайн на база данни може да бъде част от вашата дългосрочна стратегия за проектиране на системи, готови за локализация.
Ключът към включването на многоезична поддръжка във вашето приложение е да го направите по начин, който не увеличава драстично разходите за разработка или поддръжка. Тъй като моделирането на база данни е неразделна част от процеса на разработка на софтуер, трябва да помислите за най-добрата стратегия за проектиране на модел на данни, за да осигурите многоезична поддръжка на вашето приложение.
Правилният модел на данни трябва да ви позволи да модифицирате приложението или да добавяте нова функционалност, като същевременно поддържате многоезична поддръжка – без да добавяте допълнителни усилия или разходи. Освен това трябва да ви позволява да включвате нови езици, без да докосвате приложението; трябва само да добавите съответните данни за превод към базата данни.
Просто внедряване срещу гъвкавост и функционалност
Има различни подходи за създаване на дизайн на база данни за многоезични приложения. Всеки има своите предимства и недостатъци. Тези, които са по-лесни за изпълнение, предлагат по-малко гъвкавост и по-малко функционалност; тези, които предлагат повече гъвкавост и функционалност, имат по-сложни реализации.
Моят съвет тук е винаги да избирате тези, които предлагат повече функционалност и гъвкавост , дори ако са по-скъпи за изпълнение. Понякога правим грешката да мислим, че дадено приложение е твърде малко, че не си струва да прилагаме сложни схеми за решаване на неща като многоезична поддръжка. Но в крайна сметка това приложение ще нарасне и ще съжаляваме, че сме избрали „бърз и мръсен“ подход, който изглеждаше по-прост и по-евтин.
Идеалното за внедряване на допълнителна функционалност към приложение – било то многоезична поддръжка, регистриране на промени, удостоверяване на потребителя или нещо друго – е тази функционалност да има своя собствена подсхема и нейната логика, капсулирана в компоненти за многократна употреба. По този начин както функционалността на аксесоарите, така и нейната подсхема могат да бъдат включени във всяко ново приложение с минимални усилия.
Интелигентен инструмент за проектиране на база данни и моделиране на данни като Vertabelo е чудесна помощ за ефективното управление на вашите схеми и подсхеми. Също така, разгледайте тези съвети за по-добър дизайн на база данни и се уверете, че следвате всички от тях. Преди да започнете да рисувате диаграмата си за бърза помощ, ви предлагам да разгледате тази основна серия от съвети за моделиране на база данни.
Някои привлекателни (но непрепоръчителни) решения за проектиране на многоезични бази данни
Най-лесно – но най-малко препоръчително
Нека започнем с най-малко препоръчания, но най-лесният начин за внедряване на многоезична база данни с приложения. Тя ви позволява бързо да решите нуждата от поддръжка на многоезично приложение, но ще ви донесе проблеми, когато приложението нарасне във функционалност или географско покритие.
Тази проста стратегия се състои в добавяне на допълнителна колона за всяка колона с текст, която се нуждае от превод, и за всеки език, на който трябва да бъдат преведени текстовете.
Например в Movies таблицата по-долу има OriginalTitle поле. Допълнителна колона за заглавие е добавена за всеки език за превод:
| MovieId | OriginalTitle | Title_sp | Title_it | Title_fr |
|---|---|---|---|---|
| 1 | Умирай трудно | Дуро де матар | Trappola di cristallo | Piege de cristal |
| 2 | Назад в бъдещето | Volver al futuro | Ritorno al futuro | Връщане към бъдещето |
| 3 | Джурасик парк | Jurásico Parque | Джурасико парко | Парк Юрасик |
Приложението трябва да получи данните за описание от колоната, съответстваща на езика, избран от потребителя. Когато трябва да добавите нов език, трябва да добавите допълнителна колона към таблицата, която да съдържа текстовете, преведени на новия език. Трябва също да адаптирате приложението, за да потвърдите добавения език и колони.
Това решение не изисква сложни JOIN за получаване на преведените текстове, нито изисква дублирани записи – само репликация на колони с текстово съдържание. Но неговата приложимост е ограничена до ситуации, в които трябва да бъдат преведени само няколко таблици.
Да предположим например, че имате Products таблица и Processes маса. Всеки от тях има поле Описание, което се нуждае от превод; изглежда достатъчно лесно, нали? Но ако цялото приложение (включително всички негови опции на менюто, съобщения за грешки и т.н.) трябва да е многоезично, това решение е неприложимо.
По-универсален, но също не е препоръчителен
Продължавайки с идеята за запазване на преводите в една и съща таблица, алтернатива на предишната опция е да увеличите текстовите полета. Това ще ни позволи да съхраняваме всички преводи в едно и също поле, организирайки ги в структура от данни (например XML документ или JSON обект). По-долу имаме пример:
| Идентификатор на филма | Оригинално заглавие | Преводи |
| 1 | Умирай трудно | [ {"language":"sp", "title":"Duro de matar"}, {"language":"it", "title":"Trappola di cristallo"}, {"language":"fr", "title":"Piège de cristal"} ] |
| 2 | Обратно в бъдещето | [ {"language":"sp", "title":"Volver al futuro"}, {"language":"it", "title":"Ritorno al futuro"}, {"language":"fr", "title":"Retour vers le futur"} ] |
| 3 | Джурасик парк | [ {"language":"sp", "title":"Parque jurásico"}, {"language":"it", "title":"Giurassico parco"}, {"language":"fr", "title":"Parc jurassique"} ] |
Тази опция не изисква допълнителни колони, но добавя сложност. Заявките за данни сега трябва да могат правилно да обработват и интерпретират структурата на данните, използвана за многоезична поддръжка. Например, ако JSON или XML се използват за съхраняване на преводи, SQL заявките трябва да използват SQL версия, която поддържа избрания тип данни.
Следната SQL команда използва MS SQL Server OPENJSON() функция за използване на съдържанието на Translations поле като подчинена таблица:
SELECT m.MovieId, m.OriginalTitle, t.TranslatedTitle FROM Movies AS m CROSS APPLY OPENJSON(m.Translations) WITH ( language char(2) '$.language', TranslatedTitle varchar(100) '$.title’ ) AS t WHERE t.language = 'fr';
Тъй като няма функции или оператори за манипулиране на JSON или XML форматирани данни в стандартния SQL, вие сте принудени да напишете вашите заявки за конкретна RDBMS, ако искате да използвате тази техника за съхраняване на преведени текстове. Например, предишната заявка не се поддържа от MySQL. Ако трябва да прочетете JSON данните в Movies таблица с MySQL, ще напишете тази заявка:
SELECT m.MovieId, m.OriginalTitle, JSON_EXTRACT(m.Translations, '$.title') AS TranslatedTitle FROM Movies AS m WHERE JSON_EXTRACT(m.Translations. '$.language') = 'fr';
Съхранение на преведен текст в различни записи
Можете също да изберете да използвате различни записи за всеки език. Въпреки това трябва да се примирите с загубата на нормализиране:едни и същи данни се повтарят в няколко записа, в които варира само преводът.
| MovieId | LanguageId | Заглавие |
|---|---|---|
| 1 | bg | Умирай трудно |
| 1 | sp | Дуро де матар |
| 1 | то | Trappola di cristallo |
| 1 | fr | Piege de cristal |
| 2 | bg | Назад в бъдещето |
| 2 | sp | Volver al futuro |
| 2 | то | Ritorno al futuro |
С тази опция можете да създадете изгледи на всяка таблица, които връщат само редовете на даден език:
CREATE VIEW Movies_en AS SELECT MovieId, Title FROM Movies WHERE LanguageId = 'en'; CREATE VIEW Movies_sp as SELECT MovieId, Title FROM Movies WHERE LanguageId = 'sp';
След това, за да направите заявка в таблицата, можете да използвате различен изглед според целевия език за превод. Но нормализирането на модела се губи и поддръжката на масата е ненужно сложна.
Съхранение на преведен текст в отделни таблици
Един от начините да съхранявате преведените текстове, без да нарушавате релационния модел, е да имате таблица с подробности за всяка таблица, съдържаща текстове за превод. Подчинената таблица, съдържаща преводите, трябва да има същите ключови полета като основната таблица плюс поле, указващо езика на превода.
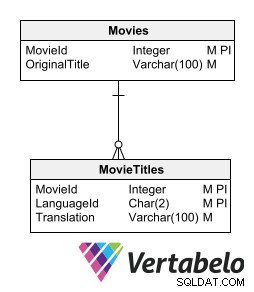
Подчинената таблица с преводи трябва да има същите ключови полета като основната таблица плюс поле, указващо езика на превода.
Тази опция позволява включване на нови езици, без да се променя структурата на таблицата. Не изисква генериране на излишна информация или нарушаване на нормализирането на модела.
Недостатъкът на тази опция е, че изисква създаването на подчинена таблица за всяка таблица, която съхранява текстови данни, изискващи превод. Въпреки това, идеята за съхраняване на преводи в свързани таблици ни доближава до най-препоръчителния начин за проектиране на многоезична база данни.
Универсалното решение:подсхема за превод
За да бъдат едно приложение и неговата база данни наистина многоезични, всички текстове трябва да имат превод на всеки поддържан език – не само текстовите данни в определена таблица. Това се постига с подсхема за превод, където се съхраняват всички данни с текстово съдържание, които могат да достигнат до очите на потребителя.
В уеб приложенията, предназначени за използване на различни езици, подсхемата за превод е необходимост, а не опция. Всичко друго ще доведе до сложности, които ще направят невъзможна правилната поддръжка на приложението.
Ключът за запазване на преводите в отделна схема е да поддържате индексиран каталог с всички текстове, които се нуждаят от превод, независимо дали са описания на обекти, съобщения за грешки или опции на менюто. Идеята е, че никакъв текст, който може да достигне до очите на потребителя, не се съхранява в таблица извън тази подсхема.
Един от начините да организирате каталога за преводи е да използвате три таблици:
- Основна таблица на езиците.
- Таблица с текстове на оригиналния език.
- Таблица с преведени текстове.
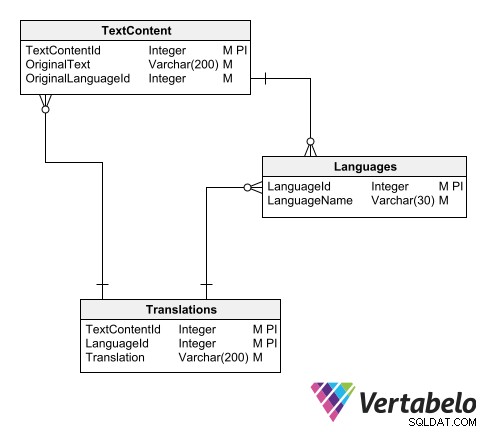
Схема за универсален каталог за преводи.
В основната таблица на езиците просто вмъкваме запис за всеки език, поддържан от модела на данни. Всеки има идентификационен код и име:
| LanguageId | Име на език |
|---|---|
| en | английски |
| sp | испански |
| то | италиански |
| fr | френски |
Текстовата таблица записва всички текстове, които изискват превод. Всеки запис има произволен идентификатор, оригинален текст и идентификатор на оригиналния език.
В TextContent таблица, оригиналният текст и идентификационният номер на оригиналния език не са строго необходими. Но те опростяват заявките, които не изискват превод. Например, когато правите заявки за статистически анализ или контрол на управлението (които обикновено са достъпни само за потребители, които разбират оригиналния език), заявките могат да бъдат опростени чрез използване на текстовете по подразбиране (непреведени).
Оригиналните текстове са полезни и за тези, които трябва да попълнят таблицата с преведени текстове. Въвеждането на данни за превод може да се извърши с помощта на мини приложение, показващо оригиналния текст и преводите на всички налични езици. Възможно е също така да се генерира информация за подсхемата за превод чрез автоматичен процес с помощта на API за превод.
Свързване с основната схема
В основната схема на приложението колоните с текстови стойности, които се нуждаят от превод, се заменят с идентификатори, които сочат към таблицата с преведени текстове:
Основната схема е свързана със схемата за превод чрез таблици с текстове, които се нуждаят от превод.
Можете да оставите оригиналното текстово поле в някои от основните таблици на схеми, за да улесните заявките, при които не се изисква превод, въпреки че това генерира излишна информация. Например, можем да запазим ProductDescription полето в Products таблица за улесняване на статистическите запитвания или за попълване на измеренията на хранилище за данни, оставяйки настрана подсхемата за превод, когато не е необходима.
- Дизайн на многоезична база данни:Направете го веднъж и го направете правилно
Видяхме няколко алтернативи за създаване на дизайн на многоезична база данни. Някои са по-лесни и по-бързи за изпълнение. Последното решение е малко по-сложно, но ви дава много по-голяма гъвкавост. Освен това ще ви спести проблеми, когато дойде време да поддържате приложението и базата данни. Така в дългосрочен план ще бъде много по-евтино.
Понякога най-краткият път в дизайна на база данни ви изкушава да повярвате, че ще спестите време и усилия. Но когато го изберете, пренебрегвате факта, че вероятно ще трябва да го спуснете няколко пъти. Ако пренебрегнете най-добрите практики за проектиране на многоезична база данни, вероятно в крайна сметка ще вършите същата работа отново и отново.