Релационният модел за управление на данни е разработен за първи път от д-р Едгар Ф. Код през 1969 г. Съвременните системи за управление на релационни бази данни (RDBMS) са в съответствие с парадигмата. Ключовата структура, идентифицирана с RDBMS, е логическата структура, наречена „таблица“. Таблиците се състоят предимно от редове и колони (наричани още записи и атрибути или кортежи и полета). В строг математически смисъл, терминът таблица всъщност се нарича връзка и отчита термина „релационен модел“. В математиката релацията е представяне на множество.
Атрибутът израз дава добро описание на предназначението на колона – характеризира набора от редове, свързани с нея. Всяка колона трябва да бъде от определен тип данни и всеки ред трябва да има някои уникални идентификационни характеристики, наречени „ключове“. Промяната на данни обикновено е по-ефективна, когато се извършва с помощта на релационния модел, докато извличането на данни може да бъде по-бързо с по-стария йерархичен модел, който е предефиниран в модели NoSQL системи.
Нормализацията на данните е математически процес на моделиране на бизнес данни във форма, която гарантира, че всеки обект е представен от една връзка (таблица). Първите привърженици на релационния модел предложиха концепция за нормални форми. Едгар Код дефинира първата, втората и третата нормални форми. След това към него се присъединява Реймънд Ф. Бойс. Заедно те дефинират нормалната форма на Бойс-Код. Досега шест нормални форми са дефинирани теоретично, но в повечето практически приложения обикновено разширяваме нормализирането до третата нормална форма. Всяка нормална форма се стреми да избегне аномалии по време на модифициране на данни, да намали излишъка и зависимостта на данните в таблицата. Всяко ниво на нормализиране има тенденция да въвежда повече таблици, намалява излишъка, увеличава простотата на всяка таблица, но също така увеличава сложността на цялата система за управление на релационна база данни. Така че структурно RDBM системите обикновено са по-сложни от йерархичните системи.
Защо нормализиране на базата данни:четири аномалии
Съхранението на данни без нормализиране причинява редица проблеми с консумацията на данни. Привържениците на нормализирането нарекоха подобни проблеми аномалии. За да опишем тези аномалии, нека разгледаме данните, представени на фиг. 1.

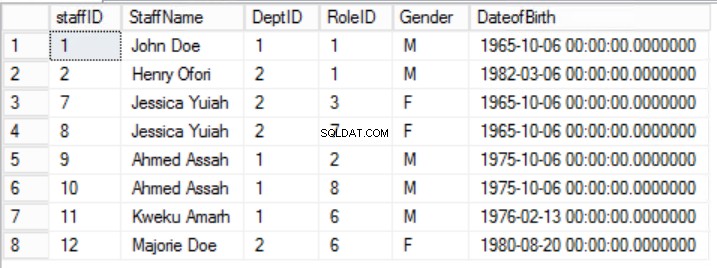
Фиг. 1 Таблица за служители
Списък 1. Основна таблица за демонстриране на нормализиране на базата данни.
1.1. Създаване на таблица
use privatework go create table staffers ( staffID int identity (1,1) ,StaffName varchar(50) ,Role varchar(50) ,Department varchar (100) ,Manager varchar (50) ,Gender char(1) ,DateofBirth datetime2 )
1.2. Вмъкване на редове
insert into staffers values ('John Doe','Engineering','Kweku Amarh','M','06-Oct-1965');
insert into staffers values ('Henry Ofori','Engineering','Kweku Amarh','M','06-Mar-1982');
insert into staffers values ('Jessica Yuiah','Engineering','Kweku Amarh','F','06-Oct-1965');
insert into staffers values ('Ahmed Assah','Engineering','Kweku Amarh','M','06-Oct-1965'); 1.3. Запитване в таблицата
select * from staffers;
Тази таблица представлява по същество два набора от данни, които са били комбинирани по невнимание:имена на служители и отдели. Забележете, че целият персонал е от един и същи отдел:Инженеринг. Това беше направено за простота и за да се демонстрира нормализиране. Има три основни проблема, свързани с манипулирането на тази структура:
Аномалията при вмъкване
За да вмъкнем нов запис, трябва непрекъснато да повтаряме имената на отделите и мениджърите.
Аномалията на изтриването
За да изтрием записа на служител, трябва също да изтрием свързания мениджър и отдел. Ако има нужда да премахнем ВСИЧКИ записи на служителите, ние също трябва да премахнем всички отдели и всички мениджъри.
Аномалията при актуализиране
Ако има нужда от смяна на мениджъра на някой отдел, трябва да направим промяната във всеки отделен ред на тази таблица, тъй като стойностите се дублират за всеки служител.
Нормални форми на базата данни
В следващите раздели на статията ще се опитаме да опишем 1-ва, 2-ра и 3-та нормални форми, които е много по-вероятно да се наблюдават в реални RDBM системи. Има и други разширения на теорията, като четвъртата, петата и нормалните форми на Бойс-Код, но в тази статия ще се ограничим до три нормални форми.
Първата нормална форма
Първата нормална форма се дефинира от четири правила:
Всяка колона трябва да съдържа стойности от един и същ тип данни.
Таблицата „Служители“ вече отговаря на това правило.
Всяка колона в таблица трябва да е атомарна.
Това по същество означава, че трябва да разделите съдържанието на колона, докато вече не може да бъде разделено. Обърнете внимание, че Ролята колона в Служители таблица нарушава правило 2 за реда със StaffID=3.
Всеки ред в таблица трябва да е уникален.
Уникалността в нормализираните таблици обикновено се постига с помощта на първични ключове. Първичен ключ уникално дефинира всеки ред в таблица. През повечето време първичният ключ се дефинира само от една колона. Първичен ключ, съставен от повече от една колона, се нарича композитен ключ.
Редът, в който се съхраняват записите, няма значение.
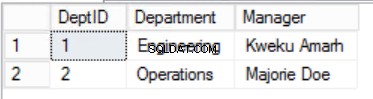
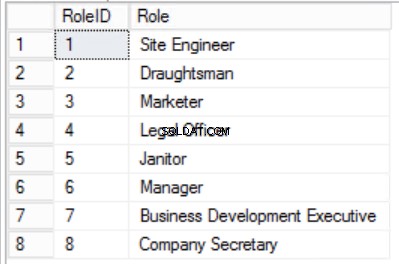
За подравняване на данните в Служители таблица с принципите на Първата нормална форма, ние трябва да разделим таблицата, както е показано на фигури 2, 3 и 4.
Фиг. Таблица с 2 служители
Стеснихме данните в Служители таблица и имплементира композитен първичен ключ, за да гарантира уникалност. Също така създадохме две допълнителни таблици Роли и Отдели които имат връзки с основните Служители таблица, реализирана с помощта на външни ключове. Прегледайте DDL в листинг 2.
Списък 2. DDL на нови Служители Таблица за първата нормална форма.
USE [PrivateWork] GO CREATE TABLE [dbo].[staffers]( [staffID] [int] IDENTITY(1,1) NOT NULL, [StaffName] [varchar](50) NULL, [DeptID] [int] NOT NULL, [RoleID] [int] NOT NULL, [Gender] [char](1) NULL, [DateofBirth] [datetime2](7) NULL, PRIMARY KEY CLUSTERED ( [staffID] ASC, [RoleID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[staffers1NF] WITH CHECK ADD FOREIGN KEY([DeptID]) REFERENCES [dbo].[Department] ([DeptID]) GO ALTER TABLE [dbo].[staffers1NF] WITH CHECK ADD FOREIGN KEY([RoleID]) REFERENCES [dbo].[Roles] ([RoleID]) GO
Фиг. Таблица 3 отделения
Фиг. Таблица с 4 роли
Втората нормална форма
Първият нормален формуляр вече трябва да е на мястото си.
Всяка неключова колона не трябва да има частична зависимост от първичния ключ.
Смисълът на второто правило е, че всички колони на таблицата трябва да зависят от всички колони, които заедно съставляват първичния ключ. Поглеждайки назад към таблиците на фигури 2, 3 и 4, откриваме, че сме постигнали всички изисквания на Първата нормална форма. Постигнахме и изискванията на втората нормална форма за две таблици Роли и Отдели . Въпреки това, в случая на Служителите маса, все още имаме проблем. Нашият първичен ключ се състои от колоните StaffID и RoleID.
Правило 2 от втората нормална форма тук е нарушено от факта, че полът и датата на раждане на персонала не зависят от RoleID. Има частична зависимост.
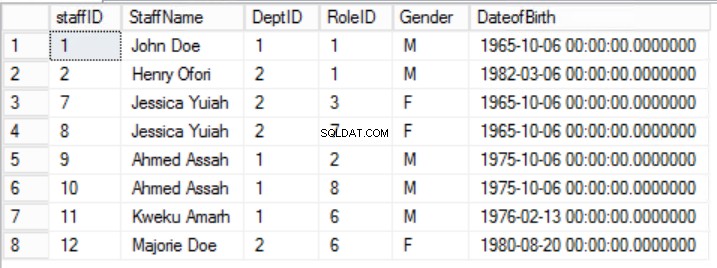
Фиг. 5 служители за първа нормална форма
В дадения пример можем да се опитаме да поправим това, като премахнем RoleID от първичния ключ, но ако направим това, ще нарушим друго правило:ролята на уникалността, посочена в Първата нормална форма. Трябва да вземем друг подход. Ще променим Служителите таблица с разбирането, че един служител може да играе повече от една роля. Вижте фиг. 6.
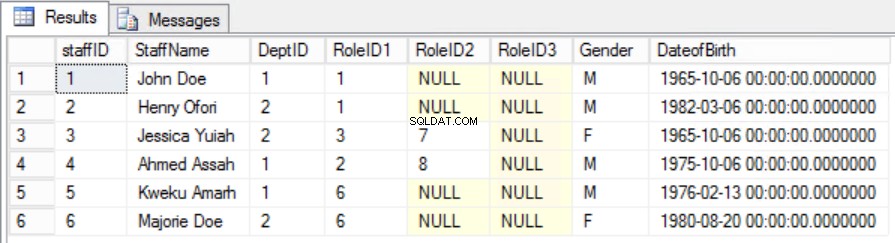
Фиг. Таблица с 6 служители за втората нормална форма
Успяхме да запазим уникалността, както и да премахнем частичната зависимост.
Листинг 3. DDL на таблица за нови служители за втората нормална форма.
USE [PrivateWork] GO CREATE TABLE [dbo].[staffers2NF]( [staffID] [int] IDENTITY(1,1) NOT NULL, [StaffName] [varchar](50) NULL, [DeptID] [int] NOT NULL, [RoleID1] [int] NOT NULL, [RoleID2] [int] NULL, [RoleID3] [int] NULL, [Gender] [char](1) NULL, [DateofBirth] [datetime2](7) NULL, PRIMARY KEY CLUSTERED ( [staffID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([DeptID]) REFERENCES [dbo].[Department] ([DeptID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID1]) REFERENCES [dbo].[Roles] ([RoleID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID2]) REFERENCES [dbo].[Roles] ([RoleID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID3]) REFERENCES [dbo].[Roles] ([RoleID]) GO
Третата нормална форма
Вторият нормален формуляр вече трябва да е на мястото си.
Всяка неключова колона не трябва да има транзитивна зависимост от първичния ключ.
Смисълът на третата нормална форма е, че не трябва да има колони, които зависят от неключови колони, дори ако тези неключови колони вече зависят от първичния ключ.
Като пример да приемем, че сме решили да добавим допълнителна колона към Служители таблица, както е показано на фиг. 7, за да видите ясно мениджъра на персонала. По този начин щяхме да нарушим второто правило за трета нормална форма, тъй като името на мениджъра зависи от DeptID, а DeptID от своя страна зависи от StaffID. Това е преходна зависимост.
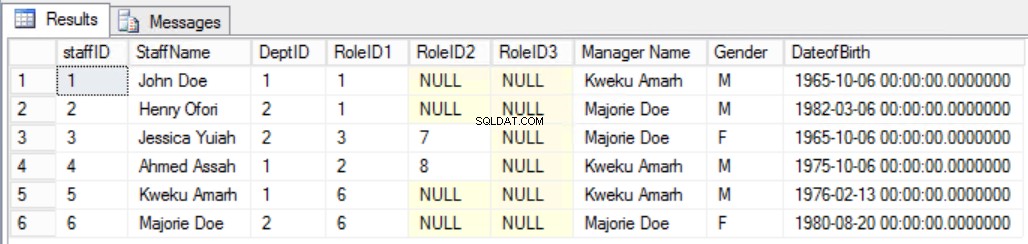
Фиг. Таблица от 7 служители за третата нормална форма (нарушено правило)
Би било по-добре да запазите стария формуляр и да покажете необходимата информация, като използвате свързване между таблицата на служителите и таблицата на отделите.
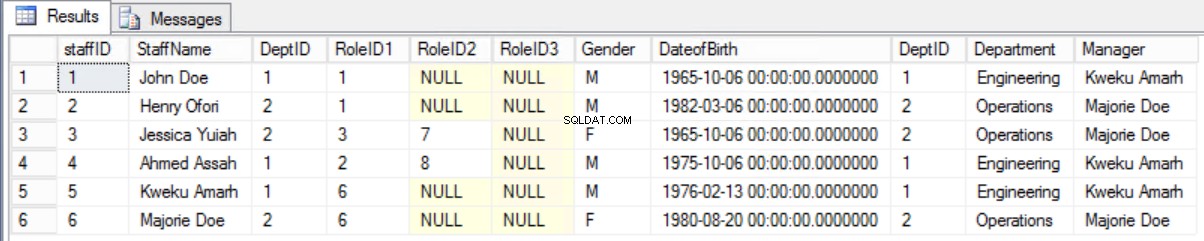
Фиг. 8 Присъединете се между служители и отдели
Обява 4. Запитване към персонала и мениджърите на дисплея.
select * from staffers2NF s join Department d on s.DeptID=d.DeptID;
Практическо приложение
Повечето зрели приложения прилагат правилата за нормализиране в разумна степен. Виждаме, че прилагането на нормализиране на данните води до използването на ограничения на първичния ключ и ограничения на външния ключ. В допълнение, такива проблеми като индексирането на чужди ключове също се появяват, когато навлизаме по-дълбоко в темата. По-рано споменахме как липсата на нормализиране може да повлияе на гладкото манипулиране на данни, както е описано в аномалиите при вмъкване, изтриване и актуализиране. Липсата на подходящо нормализиране също може косвено да повлияе на производителността на заявката.
Наскоро попаднах на таблица с формата, показана в таблица 1, която ще наречем Customer_Accounts.
S/No | Име | Account_No | Телефонен номер |
1 | Кенет Игири | 9922344592 | 2348039988456, 2348039988456, 2348039988456 |
2 | Ърнест Доу | 6677554897 | 2348022887546, 2348039988456 |
Таблица 1 Клиентски_профили
Основният проблем с тази таблица е, че нарушава второто правило на Първата нормална форма. Резултатът в нашия случай беше, че търсенето на клиенти въз основа на техните телефонни номера изискваше използването на LIKE в клаузата WHERE и водещ %.
Select account_no from Customer_Accounts where Phone_No like ‘%2348039988456%’;
Въздействието на горната конструкция беше, че оптимизаторът никога не е използвал индекс, което е огромен проблем с производителността.
Заключение
Нормализацията на данните е в сферата на дизайна на базата данни и както разработчиците, така и администраторите на данни трябва да обърнат внимание на правилата, описани в тази статия. Винаги е по-добре да се направи нормализиране, преди базата данни да влезе в производство. Предимствата на правилно проектираната система за управление на релационни бази данни просто си заслужават усилията.