Всички програми обработват данни в една или друга форма и много от тях трябва да могат да запазват и извличат тези данни от едно извикване до друго. Python, SQLite и SQLAlchemy дават функционалност на базата данни на програмите ви, което ви позволява да съхранявате данни в един файл, без да е необходим сървър на база данни.
Можете да постигнете подобни резултати, като използвате плоски файлове в произволен брой формати, включително CSV, JSON, XML и дори персонализирани формати. Плоските файлове често са четими от човека текстови файлове — въпреки че могат да бъдат и двоични данни — със структура, която може да бъде анализирана от компютърна програма. По-долу ще разгледате използването на SQL бази данни и плоски файлове за съхранение и манипулиране на данни и ще научите как да решите кой подход е подходящ за вашата програма.
В този урок ще научите как да използвате:
- Плоски файлове за съхранение на данни
- SQL за подобряване на достъпа до постоянни данни
- SQLite за съхранение на данни
- SQLAlchemy за работа с данни като Python обекти
Можете да получите целия код и данни, които ще видите в този урок, като щракнете върху връзката по-долу:
Изтеглете примерния код: Щракнете тук, за да получите кода, който ще използвате, за да научите за управлението на данни с SQLite и SQLAlchemy в този урок.
Използване на плоски файлове за съхранение на данни
Пплосък файл е файл, съдържащ данни без вътрешна йерархия и обикновено без препратки към външни файлове. Плоските файлове съдържат четими знаци и са много полезни за създаване и четене на данни. Тъй като не е необходимо да използват фиксирани ширини на полета, плоските файлове често използват други структури, за да направят възможно програмата да анализира текста.
Например, файловете със стойности, разделени със запетая (CSV) са редове от обикновен текст, в които символът запетая разделя елементите с данни. Всеки ред от текст представлява ред с данни, а всяка стойност, разделена със запетая, е поле в този ред. Разделителят на знаците запетая показва границата между стойностите на данните.
Python се отличава с четене от и записване във файлове. Възможността да четете файлове с данни с Python ви позволява да възстановите приложение в полезно състояние, когато го стартирате отново по-късно. Възможността да запазвате данни във файл ви позволява да споделяте информация от програмата между потребители и сайтове, където се изпълнява приложението.
Преди една програма да може да прочете файл с данни, тя трябва да може да разбере данните. Обикновено това означава, че файлът с данни трябва да има някаква структура, която приложението може да използва, за да чете и анализира текста във файла.
По-долу е даден CSV файл с име author_book_publisher.csv , използван от първата примерна програма в този урок:
first_name,last_name,title,publisher
Isaac,Asimov,Foundation,Random House
Pearl,Buck,The Good Earth,Random House
Pearl,Buck,The Good Earth,Simon & Schuster
Tom,Clancy,The Hunt For Red October,Berkley
Tom,Clancy,Patriot Games,Simon & Schuster
Stephen,King,It,Random House
Stephen,King,It,Penguin Random House
Stephen,King,Dead Zone,Random House
Stephen,King,The Shining,Penguin Random House
John,Le Carre,"Tinker, Tailor, Soldier, Spy: A George Smiley Novel",Berkley
Alex,Michaelides,The Silent Patient,Simon & Schuster
Carol,Shaben,Into The Abyss,Simon & Schuster
Първият ред предоставя разделен със запетая списък с полета, които са имената на колоните за данните, които следват в останалите редове. Останалите редове съдържат данните, като всеки ред представлява един запис.
Забележка: Въпреки че всички автори, книги и издатели са реални, връзките между книгите и издателите са измислени и са създадени за целите на този урок.
След това ще разгледате някои от предимствата и недостатъците на използването на плоски файлове като горния CSV за работа с вашите данни.
Предимства на плоските файлове
Работата с данни в плоски файлове е управляема и лесна за изпълнение. Наличието на данните в четим от човека формат е полезно не само за създаване на файла с данни с текстов редактор, но и за разглеждане на данните и търсене на всякакви несъответствия или проблеми.
Много приложения могат да експортират плоски файлови версии на данните, генерирани от файла. Например, Excel може да импортира или експортира CSV файл към и от електронна таблица. Плоските файлове също имат предимството, че са самостоятелни и прехвърляеми, ако искате да споделите данните.
Почти всеки език за програмиране има инструменти и библиотеки, които улесняват работата с CSV файлове. Python има вградения csv наличен модул и мощният модул pandas, което прави работата с CSV файлове мощно решение.
Недостатъци на плоските файлове
Предимствата на работата с плоски файлове започват да намаляват с увеличаването на данните. Големите файлове все още са четими от човека, но редактирането им за създаване на данни или търсене на проблеми става по-трудна задача. Ако приложението ви ще промени данните във файла, тогава едно решение би било да прочетете целия файл в паметта, да направите промените и да запишете данните в друг файл.
Друг проблем с използването на плоски файлове е, че ще трябва изрично да създавате и поддържате всякакви връзки между части от вашите данни и приложната програма в синтаксиса на файла. Освен това ще трябва да генерирате код в приложението си, за да използвате тези връзки.
Последното усложнение е, че хората, с които искате да споделите своя файл с данни, също ще трябва да знаят за структурите и взаимоотношенията, които сте създали в данните, и да действат според тях. За да имат достъп до информацията, тези потребители ще трябва да разберат не само структурата на данните, но и инструментите за програмиране, необходими за достъп до тях.
Пример за плосък файл
Примерната програма examples/example_1/main.py използва author_book_publisher.csv файл, за да получите данните и връзките в него. Този CSV файл поддържа списък с автори, книгите, които са публикували, и издателите за всяка от книгите.
Забележка: Файловете с данни, използвани в примерите, са налични в project/data директория. Има и програмен файл в project/build_data директория, която генерира данните. Това приложение е полезно, ако промените данните и искате да се върнете към известно състояние.
За да получите достъп до файловете с данни, използвани в този раздел и в целия урок, щракнете върху връзката по-долу:
Изтеглете примерния код: Щракнете тук, за да получите кода, който ще използвате, за да научите за управлението на данни с SQLite и SQLAlchemy в този урок.
Представеният по-горе CSV файл е доста малък файл с данни, съдържащ само няколко автори, книги и издатели. Трябва също да забележите някои неща за данните:
-
Авторите Стивън Кинг и Том Кланси се появяват повече от веднъж, защото в данните са представени множество книги, които са публикували.
-
Авторите Стивън Кинг и Пърл Бък имат една и съща книга, публикувана от повече от едно издателство.
Тези дублирани полета с данни създават връзки между други части от данните. Един автор може да напише много книги, а един издател може да работи с множество автори. Авторите и издателите споделят връзки с отделни книги.
Връзките в author_book_publisher.csv файл са представени от полета, които се появяват няколко пъти в различни редове на файла с данни. Поради тази излишност на данните, данните представляват повече от една двуизмерна таблица. Ще видите повече от това, когато използвате файла за създаване на файл с база данни на SQLite.
Примерната програма examples/example_1/main.py използва връзките, вградени в author_book_publisher.csv файл за генериране на някои данни. Първо представя списък на авторите и броя на книгите, които всеки е написал. След това показва списък с издатели и броя на авторите, за които всеки е публикувал книги.
Той също така използва treelib модул за показване на йерархия на дървото на авторите, книгите и издателите.
И накрая, той добавя нова книга към данните и отново показва йерархията на дървото с новата книга на място. Ето main() функция за входна точка за тази програма:
1def main():
2 """The main entry point of the program"""
3 # Get the resources for the program
4 with resources.path(
5 "project.data", "author_book_publisher.csv"
6 ) as filepath:
7 data = get_data(filepath)
8
9 # Get the number of books printed by each publisher
10 books_by_publisher = get_books_by_publisher(data, ascending=False)
11 for publisher, total_books in books_by_publisher.items():
12 print(f"Publisher: {publisher}, total books: {total_books}")
13 print()
14
15 # Get the number of authors each publisher publishes
16 authors_by_publisher = get_authors_by_publisher(data, ascending=False)
17 for publisher, total_authors in authors_by_publisher.items():
18 print(f"Publisher: {publisher}, total authors: {total_authors}")
19 print()
20
21 # Output hierarchical authors data
22 output_author_hierarchy(data)
23
24 # Add a new book to the data structure
25 data = add_new_book(
26 data,
27 author_name="Stephen King",
28 book_title="The Stand",
29 publisher_name="Random House",
30 )
31
32 # Output the updated hierarchical authors data
33 output_author_hierarchy(data)
Кодът на Python по-горе извършва следните стъпки:
- Редове от 4 до 7 прочетете
author_book_publisher.csvфайл в pandas DataFrame. - Редове от 10 до 13 отпечатайте броя на книгите, публикувани от всяко издателство.
- Редове от 16 до 19 отпечатайте броя на авторите, свързани с всеки издател.
- Ред 22 извежда данните от книгата като йерархия, сортирана по автори.
- Редове от 25 до 30 добавете нова книга към структурата в паметта.
- Ред 33 извежда данните за книгата като йерархия, сортирана по автори, включително новодобавената книга.
Изпълнението на тази програма генерира следния изход:
$ python main.py
Publisher: Simon & Schuster, total books: 4
Publisher: Random House, total books: 4
Publisher: Penguin Random House, total books: 2
Publisher: Berkley, total books: 2
Publisher: Simon & Schuster, total authors: 4
Publisher: Random House, total authors: 3
Publisher: Berkley, total authors: 2
Publisher: Penguin Random House, total authors: 1
Authors
├── Alex Michaelides
│ └── The Silent Patient
│ └── Simon & Schuster
├── Carol Shaben
│ └── Into The Abyss
│ └── Simon & Schuster
├── Isaac Asimov
│ └── Foundation
│ └── Random House
├── John Le Carre
│ └── Tinker, Tailor, Soldier, Spy: A George Smiley Novel
│ └── Berkley
├── Pearl Buck
│ └── The Good Earth
│ ├── Random House
│ └── Simon & Schuster
├── Stephen King
│ ├── Dead Zone
│ │ └── Random House
│ ├── It
│ │ ├── Penguin Random House
│ │ └── Random House
│ └── The Shining
│ └── Penguin Random House
└── Tom Clancy
├── Patriot Games
│ └── Simon & Schuster
└── The Hunt For Red October
└── Berkley
Йерархията на автора по-горе е представена два пъти в изхода, с добавката на The Stand на Стивън Кинг , публикуван от Random House. Действителният изход по-горе е редактиран и показва само първия йерархичен изход за спестяване на място.
main() извиква други функции за извършване на по-голямата част от работата. Първата функция, която извиква, е get_data() :
def get_data(filepath):
"""Get book data from the csv file"""
return pd.read_csv(filepath)
Тази функция приема пътя на файла към CSV файла и използва pandas, за да го прочете в pandas DataFrame, който след това предава обратно на повикващия. Връщаната стойност на тази функция се превръща в структурата на данните, предавана на другите функции, които съставляват програмата.
get_books_by_publisher() изчислява броя на издадените книги от всяко издателство. Получената серия pandas използва функционалността pandas GroupBy за групиране по издател и след това сортиране въз основа на ascending флаг:
def get_books_by_publisher(data, ascending=True):
"""Return the number of books by each publisher as a pandas series"""
return data.groupby("publisher").size().sort_values(ascending=ascending)
get_authors_by_publisher() прави по същество същото нещо като предишната функция, но за автори:
def get_authors_by_publisher(data, ascending=True):
"""Returns the number of authors by each publisher as a pandas series"""
return (
data.assign(name=data.first_name.str.cat(data.last_name, sep=" "))
.groupby("publisher")
.nunique()
.loc[:, "name"]
.sort_values(ascending=ascending)
)
add_new_book() създава нова книга в pandas DataFrame. Кодът проверява дали авторът, книгата или издателят вече съществуват. Ако не, тогава създава нова книга и я добавя към DataFrame на pandas:
def add_new_book(data, author_name, book_title, publisher_name):
"""Adds a new book to the system"""
# Does the book exist?
first_name, _, last_name = author_name.partition(" ")
if any(
(data.first_name == first_name)
& (data.last_name == last_name)
& (data.title == book_title)
& (data.publisher == publisher_name)
):
return data
# Add the new book
return data.append(
{
"first_name": first_name,
"last_name": last_name,
"title": book_title,
"publisher": publisher_name,
},
ignore_index=True,
)
output_author_hierarchy() използва вложен for цикли за итерация през нивата на структурата на данните. След това използва treelib модул за извеждане на йерархичен списък на авторите, книгите, които са публикували, и издателите, които са публикували тези книги:
def output_author_hierarchy(data):
"""Output the data as a hierarchy list of authors"""
authors = data.assign(
name=data.first_name.str.cat(data.last_name, sep=" ")
)
authors_tree = Tree()
authors_tree.create_node("Authors", "authors")
for author, books in authors.groupby("name"):
authors_tree.create_node(author, author, parent="authors")
for book, publishers in books.groupby("title")["publisher"]:
book_id = f"{author}:{book}"
authors_tree.create_node(book, book_id, parent=author)
for publisher in publishers:
authors_tree.create_node(publisher, parent=book_id)
# Output the hierarchical authors data
authors_tree.show()
Това приложение работи добре и илюстрира мощността, с която разполагате с модула pandas. Модулът предоставя отлична функционалност за четене на CSV файл и взаимодействие с данните.
Нека продължим и създадем идентично функционираща програма, използвайки Python, версия на база данни на SQLite на данните за автора и публикацията и SQLAlchemy за взаимодействие с тези данни.
Използване на SQLite за запазване на данни
Както видяхте по-рано, има излишни данни в author_book_publisher.csv файл. Например цялата информация за The Good Earth на Pearl Buck е посочен два пъти, защото две различни издатели са публикували книгата.
Представете си, ако този файл с данни съдържа повече свързани данни, като адрес и телефонен номер на автора, дати на публикуване и ISBN номера за книги, или адреси, телефонни номера и може би годишни приходи за издателите. Тези данни ще бъдат дублирани за всеки основен елемент от данни, като автор, книга или издател.
Възможно е да се създават данни по този начин, но би било изключително тромаво. Помислете за проблемите с поддържането на този файл с данни актуален. Ами ако Стивън Кинг поиска да промени името си? Ще трябва да актуализирате няколко записа, съдържащи името му, и да се уверите, че няма правописни грешки.
По-лошо от дублирането на данни би било сложността на добавянето на други връзки към данните. Ами ако решите да добавите телефонни номера за авторите и те имат телефонни номера за дома, работата, мобилния и може би повече? Всяка нова връзка, която искате да добавите за който и да е основен елемент, ще умножи броя на записите по броя на елементите в тази нова връзка.
Този проблем е една от причините да съществуват връзки в системите за бази данни. Важна тема в инженерството на базата данни е нормализирането на базата данни , или процесът на разделяне на данни за намаляване на излишъка и повишаване на целостта. Когато структурата на базата данни е разширена с нови типове данни, нейното нормализиране предварително намалява промените в съществуващата структура до минимум.
Базата данни SQLite е налична в Python и според началната страница на SQLite тя се използва повече от всички други системи за бази данни, взети заедно. Той предлага пълнофункционална система за управление на релационна база данни (RDBMS), която работи с един файл, за да поддържа цялата функционалност на базата данни.
Освен това има предимството, че не изисква отделен сървър на база данни, за да функционира. Файловият формат на базата данни е междуплатформен и достъпен за всеки език за програмиране, който поддържа SQLite.
Всичко това е интересна информация, но как е свързана с използването на плоски файлове за съхранение на данни? Ще разберете по-долу!
Създаване на структура на база данни
Подходът с груба сила за получаване на author_book_publisher.csv данни в база данни на SQLite би било да се създаде една таблица, съответстваща на структурата на CSV файла. Правейки това ще игнорира голяма част от силата на SQLite.
Релационни бази данни предоставят начин за съхраняване на структурирани данни в таблици и установяване на връзки между тези таблици. Те обикновено използват Structured Query Language (SQL) като основен начин за взаимодействие с данните. Това е прекалено опростяване на това, което предоставят RDBMS, но е достатъчно за целите на този урок.
Базата данни на SQLite осигурява поддръжка за взаимодействие с таблицата с данни с помощта на SQL. Файлът с база данни на SQLite не само съдържа данните, но има и стандартизиран начин за взаимодействие с данните. Тази поддръжка е вградена във файла, което означава, че всеки език за програмиране, който може да използва SQLite файл, може също да използва SQL за работа с него.
Взаимодействие с база данни със SQL
SQL е декларативен език използва се за създаване, управление и запитване на данните, съдържащи се в база данни. Декларативният език описва какво трябва да се постигне, а не как трябва да бъде изпълнено. Ще видите примери за SQL изрази по-късно, когато започнете да създавате таблици на база данни.
Структуриране на база данни с SQL
За да се възползвате от силата на SQL, ще трябва да приложите известна нормализиране на базата данни към данните в author_book_publisher.csv файл. За да направите това, ще разделите авторите, книгите и издателите в отделни таблици на базата данни.
Концептуално данните се съхраняват в базата данни в двуизмерни таблични структури. Всяка таблица се състои от редове сзаписи и всеки запис се състои от колони или полета , съдържащи данни.
Данните, съдържащи се в полетата, са от предварително дефинирани типове, включително текст, цели числа, плаващи числа и др. CSV файловете са различни, тъй като всички полета са текстови и трябва да бъдат анализирани от програма, за да им бъде присвоен тип данни.
Всеки запис в таблицата има първичен ключ дефиниран, за да даде на записа уникален идентификатор. Първичният ключ е подобен на ключа в речника на Python. Самата база данни често генерира първичния ключ като нарастваща целочислена стойност за всеки запис, вмъкнат в таблицата на базата данни.
Въпреки че първичният ключ често се генерира автоматично от двигателя на базата данни, това не е задължително. Ако данните, съхранявани в поле, са уникални за всички останали данни в таблицата в това поле, тогава това може да бъде първичният ключ. Например таблица, съдържаща данни за книги, може да използва ISBN на книгата като основен ключ.
Създаване на таблици с SQL
Ето как можете да създадете трите таблици, представящи авторите, книгите и издателите в CSV файла с помощта на SQL изрази:
CREATE TABLE author (
author_id INTEGER NOT NULL PRIMARY KEY,
first_name VARCHAR,
last_name VARCHAR
);
CREATE TABLE book (
book_id INTEGER NOT NULL PRIMARY KEY,
author_id INTEGER REFERENCES author,
title VARCHAR
);
CREATE TABLE publisher (
publisher_id INTEGER NOT NULL PRIMARY KEY,
name VARCHAR
);
Забележете, че няма операции с файлове, няма създадени променливи и няма структури, които да ги задържат. Изявленията описват само желания резултат:създаването на таблица с определени атрибути. Машината на базата данни определя как да направите това.
След като създадете и попълните тази таблица с данни за автора от author_book_publisher.csv файл, можете да получите достъп до него с помощта на SQL изрази. Следното изявление (наричано още заявка ) използва заместващия знак (* ), за да получите всички данни в author таблица и я изведете:
SELECT * FROM author;
Можете да използвате sqlite3 инструмент от команден ред за взаимодействие с author_book_publisher.db база данни в project/data директория:
$ sqlite3 author_book_publisher.db
След като инструментът от командния ред на SQLite работи с отворена база данни, можете да въвеждате SQL команди. Ето горната SQL команда и нейния изход, последван от .q команда за излизане от програмата:
sqlite> SELECT * FROM author;
1|Isaac|Asimov
2|Pearl|Buck
3|Tom|Clancy
4|Stephen|King
5|John|Le Carre
6|Alex|Michaelides
7|Carol|Shaben
sqlite> .q
Забележете, че всеки автор съществува само веднъж в таблицата. За разлика от CSV файла, който имаше множество записи за някои от авторите, тук е необходим само един уникален запис на автор.
Поддържане на база данни с SQL
SQL предоставя начини за работа със съществуващи бази данни и таблици чрез вмъкване на нови данни и актуализиране или изтриване на съществуващи данни. Ето примерен SQL израз за вмъкване на нов автор в author таблица:
INSERT INTO author
(first_name, last_name)
VALUES ('Paul', 'Mendez');
Този SQL израз вмъква стойностите „Paul ‘ и „Mendez ‘ в съответните колони first_name и last_name на author маса.
Забележете, че author_id колоната не е посочена. Тъй като тази колона е първичният ключ, механизмът на базата данни генерира стойността и я вмъква като част от изпълнението на израза.
Актуализирането на записи в таблица на база данни е неусложнен процес. Например, да предположим, че Стивън Кинг е искал да бъде известен с псевдонима си Ричард Бахман. Ето SQL израз за актуализиране на записа в базата данни:
UPDATE author
SET first_name = 'Richard', last_name = 'Bachman'
WHERE first_name = 'Stephen' AND last_name = 'King';
SQL операторът намира единствения запис за 'Stephen King' използвайки условния израз WHERE first_name = 'Stephen' AND last_name = 'King' и след това актуализира first_name и last_name полета с новите стойности. SQL използва знака за равенство (= ) като оператор за сравнение и оператор на присвояване.
Можете също да изтриете записи от база данни. Ето примерен SQL израз за изтриване на запис от author таблица:
DELETE FROM author
WHERE first_name = 'Paul'
AND last_name = 'Mendez';
Този SQL израз изтрива един ред от author таблица, където first_name е равно на 'Paul' и last_name е равно на 'Mendez' .
Бъдете внимателни при изтриване на записи! Условията, които задавате, трябва да са възможно най-конкретни. Условно условие, което е твърде широко, може да доведе до изтриване на повече записи, отколкото възнамерявате. Например, ако условието се основава само на реда first_name = 'Paul' , тогава всички автори с собствено име на Пол ще бъдат изтрити от базата данни.
Забележка: За да се избегне случайното изтриване на записи, много приложения изобщо не позволяват изтриване. Вместо това записът има друга колона, която показва дали се използва или не. Тази колона може да бъде наречена active и съдържат стойност, която се оценява на True или False, което показва дали записът трябва да бъде включен при запитване към базата данни.
Например, SQL заявката по-долу ще получи всички колони за всички активни записи в some_table :
SELECT
*
FROM some_table
WHERE active = 1;
SQLite няма булев тип данни, така че active колоната е представена с цяло число със стойност 0 или 1 за да посочите състоянието на записа. Други системи за бази данни могат или не могат да имат собствени булеви типове данни.
Напълно възможно е да се създават приложения за бази данни в Python, като се използват SQL изрази директно в кода. Това връща данни към приложението като списък със списъци или списък с речници.
Използването на необработен SQL е напълно приемлив начин за работа с данните, върнати от заявки към базата данни. Въпреки това, вместо да правите това, ще преминете директно към използването на SQLAlchemy за работа с бази данни.
Изграждане на взаимоотношения
Друга характеристика на системите за бази данни, която може да ви се стори дори по-мощна и полезна от запазването и извличането на данни, са връзките . Базите данни, които поддържат релации, ви позволяват да разбивате данни на множество таблици и да установявате връзки между тях.
Данните в author_book_publisher.csv файл представя данните и връзките чрез дублиране на данни. Базата данни се справя с това, като разделя данните на три таблици — author , book и publisher —и установяване на взаимоотношения между тях.
След като съберете всички данни, които искате, на едно място в CSV файла, защо искате да го разделите на няколко таблици? Няма ли да е повече работа за създаване и сглобяване отново? Това до известна степен е вярно, но предимствата на разбиването на данните и събирането им обратно с помощта на SQL могат да ви спечелят!
Връзки един към много
Аедин към много отношенията са като тези на клиент, който поръчва артикули онлайн. Един клиент може да има много поръчки, но всяка поръчка принадлежи на един клиент. author_book_publisher.db базата данни има връзка един към много под формата на автори и книги. Всеки автор може да напише много книги, но всяка книга е написана от един автор.
Както видяхте при създаването на таблицата по-горе, изпълнението на тези отделни обекти е да се постави всеки в таблица на база данни, един за автори и един за книги. Но как се реализира връзката едно към много между тези две таблици?
Не забравяйте, че всяка таблица в база данни има поле, определено като първичен ключ за тази таблица. Всяка таблица по-горе има поле за първичен ключ, наречено с помощта на този шаблон:<table name>_id .
book таблицата, показана по-горе, съдържа поле, author_id , който препраща към author маса. author_id поле установява връзка един към много между автори и книги, която изглежда така:

Диаграмата по-горе е проста диаграма на връзката между обекти (ERD), създадена с приложението JetBrains DataGrip, показваща таблиците author и book като полета със съответния им първичен ключ и полета за данни. Два графични елемента добавят информация за връзката:
-
Малките жълти и сини клавишни икони посочете съответно първичния и външния ключ за таблицата.
-
Стрелката, свързваща
bookдоauthorпосочва връзката между таблиците въз основа наauthor_idвъншен ключ вbookтаблица.
Когато добавите нова книга към book таблица, данните включват author_id стойност за съществуващ автор в author маса. По този начин всички книги, написани от автор, имат връзка за търсене обратно към този уникален автор.
Сега, когато имате отделни таблици за автори и книги, как използвате връзката между тях? SQL поддържа това, което се нарича JOIN операция, която можете да използвате, за да кажете на базата данни как да свърже две или повече таблици.
SQL заявката по-долу се присъединява към author и book таблица заедно с помощта на приложението от командния ред SQLite:
sqlite> SELECT
...> a.first_name || ' ' || a.last_name AS author_name,
...> b.title AS book_title
...> FROM author a
...> JOIN book b ON b.author_id = a.author_id
...> ORDER BY a.last_name ASC;
Isaac Asimov|Foundation
Pearl Buck|The Good Earth
Tom Clancy|The Hunt For Red October
Tom Clancy|Patriot Games
Stephen King|It
Stephen King|Dead Zone
Stephen King|The Shining
John Le Carre|Tinker, Tailor, Soldier, Spy: A George Smiley Novel
Alex Michaelides|The Silent Patient
Carol Shaben|Into The Abyss
SQL заявката по-горе събира информация както от таблицата на автора, така и от таблицата на книгата, като съединява таблиците, използвайки връзката, установена между двете. Конкатенацията на SQL низове присвоява пълното име на автора на псевдонима author_name . Данните, събрани от заявката, се сортират във възходящ ред по last_name поле.
Има няколко неща, които трябва да забележите в SQL израза. Първо, авторите се представят с пълните си имена в една колона и се сортират по фамилните им имена. Също така, авторите се появяват в изхода няколко пъти поради връзката един към много. Името на автор се дублира за всяка книга, която е написал в базата данни.
Създавайки отделни таблици за автори и книги и установявайки връзката между тях, намалявате излишъка в данните. Сега трябва само да редактирате авторски данни на едно място и тази промяна се появява във всяка SQL заявка, която осъществява достъп до данните.
Връзки много към много
Много към много връзки съществуват в author_book_publisher.db база данни между автори и издатели, както и между книги и издатели. Един автор може да работи с много издатели, а един издател може да работи с много автори. По същия начин една книга може да бъде публикувана от много издатели, а един издател може да публикува много книги.
Обработката на тази ситуация в базата данни е по-ангажираща от връзката един към много, тъй като връзката върви и в двете посоки. Many-to-many relationships are created by an association table acting as a bridge between the two related tables.
The association table contains at least two foreign key fields, which are the primary keys of each of the two associated tables. This SQL statement creates the association table relating the author and publisher tables:
CREATE TABLE author_publisher (
author_id INTEGER REFERENCES author,
publisher_id INTEGER REFERENCES publisher
);
The SQL statements create a new author_publisher table referencing the primary keys of the existing author and publisher маси. The author_publisher table is an association table establishing relationships between an author and a publisher.
Because the relationship is between two primary keys, there’s no need to create a primary key for the association table itself. The combination of the two related keys creates a unique identifier for a row of data.
As before, you use the JOIN keyword to connect two tables together. Connecting the author table to the publisher table is a two-step process:
JOINtheauthortable with theauthor_publisherмаса.JOINtheauthor_publishertable with thepublishertable.
The author_publisher association table provides the bridge through which the JOIN connects the two tables. Here’s an example SQL query returning a list of authors and the publishers publishing their books:
1sqlite> SELECT
2 ...> a.first_name || ' ' || a.last_name AS author_name,
3 ...> p.name AS publisher_name
4 ...> FROM author a
5 ...> JOIN author_publisher ap ON ap.author_id = a.author_id
6 ...> JOIN publisher p ON p.publisher_id = ap.publisher_id
7 ...> ORDER BY a.last_name ASC;
8Isaac Asimov|Random House
9Pearl Buck|Random House
10Pearl Buck|Simon & Schuster
11Tom Clancy|Berkley
12Tom Clancy|Simon & Schuster
13Stephen King|Random House
14Stephen King|Penguin Random House
15John Le Carre|Berkley
16Alex Michaelides|Simon & Schuster
17Carol Shaben|Simon & Schuster
The statements above perform the following actions:
-
Line 1 starts a
SELECTstatement to get data from the database. -
Line 2 selects the first and last name from the
authortable using theaalias for theauthortable and concatenates them together with a space character. -
Line 3 selects the publisher’s name aliased to
publisher_name. -
Line 4 uses the
authortable as the first source from which to retrieve data and assigns it to the aliasa. -
Line 5 is the first step of the process outlined above for connecting the
authortable to thepublisherмаса. It uses the aliasapfor theauthor_publisherassociation table and performs aJOINoperation to connect theap.author_idforeign key reference to thea.author_idprimary key in theauthorтаблица. -
Line 6 is the second step in the two-step process mentioned above. It uses the alias
pfor thepublishertable and performs aJOINoperation to relate theap.publisher_idforeign key reference to thep.publisher_idprimary key in thepublisherтаблица. -
Line 7 sorts the data by the author’s last name in ascending alphabetical order and ends the SQL query.
-
Lines 8 to 17 are the output of the SQL query.
Note that the data in the source author and publisher tables are normalized, with no data duplication. Yet the returned results have duplicated data where necessary to answer the SQL query.
The SQL query above demonstrates how to make use of a relationship using the SQL JOIN keyword, but the resulting data is a partial re-creation of the author_book_publisher.csv CSV data. What’s the win for having done the work of creating a database to separate the data?
Here’s another SQL query to show a little bit of the power of SQL and the database engine:
1sqlite> SELECT
2 ...> a.first_name || ' ' || a.last_name AS author_name,
3 ...> COUNT(b.title) AS total_books
4 ...> FROM author a
5 ...> JOIN book b ON b.author_id = a.author_id
6 ...> GROUP BY author_name
7 ...> ORDER BY total_books DESC, a.last_name ASC;
8Stephen King|3
9Tom Clancy|2
10Isaac Asimov|1
11Pearl Buck|1
12John Le Carre|1
13Alex Michaelides|1
14Carol Shaben|1
The SQL query above returns the list of authors and the number of books they’ve written. The list is sorted first by the number of books in descending order, then by the author’s name in alphabetical order:
-
Line 1 begins the SQL query with the
SELECTkeyword. -
Line 2 selects the author’s first and last names, separated by a space character, and creates the alias
author_name. -
Line 3 counts the number of books written by each author, which will be used later by the
ORDER BYclause to sort the list. -
Line 4 selects the
authortable to get data from and creates theaalias. -
Line 5 connects to the related
booktable through aJOINto theauthor_idand creates thebalias for thebookтаблица. -
Line 6 generates the aggregated author and total number of books data by using the
GROUP BYkeyword.GROUP BYis what groups eachauthor_nameand controls what books are tallied byCOUNT()for that author. -
Line 7 sorts the output first by number of books in descending order, then by the author’s last name in ascending alphabetical order.
-
Lines 8 to 14 are the output of the SQL query.
In the above example, you take advantage of SQL to perform aggregation calculations and sort the results into a useful order. Having the database perform calculations based on its built-in data organization ability is usually faster than performing the same kinds of calculations on raw data sets in Python. SQL offers the advantages of using set theory embedded in RDBMS databases.
Entity Relationship Diagrams
An entity-relationship diagram (ERD) is a visual depiction of an entity-relationship model for a database or part of a database. The author_book_publisher.db SQLite database is small enough that the entire database can be visualized by the diagram shown below:

This diagram presents the table structures in the database and the relationships between them. Each box represents a table and contains the fields defined in the table, with the primary key indicated first if it exists.
The arrows show the relationships between the tables connecting a foreign key field in one table to a field, often the primary key, in another table. The table book_publisher has two arrows, one connecting it to the book table and another connecting it to the publisher маса. The arrow indicates the many-to-many relationship between the book and publisher маси. The author_publisher table provides the same relationship between author and publisher .
Working With SQLAlchemy and Python Objects
SQLAlchemy is a powerful database access tool kit for Python, with its object-relational mapper (ORM) being one of its most famous components, and the one discussed and used here.
When you’re working in an object-oriented language like Python, it’s often useful to think in terms of objects. It’s possible to map the results returned by SQL queries to objects, but doing so works against the grain of how the database works. Sticking with the scalar results provided by SQL works against the grain of how Python developers work. This problem is known as object-relational impedance mismatch.
The ORM provided by SQLAlchemy sits between the SQLite database and your Python program and transforms the data flow between the database engine and Python objects. SQLAlchemy allows you to think in terms of objects and still retain the powerful features of a database engine.
The Model
One of the fundamental elements to enable connecting SQLAlchemy to a database is creating a model . The model is a Python class defining the data mapping between the Python objects returned as a result of a database query and the underlying database tables.
The entity-relationship diagram displayed earlier shows boxes connected with arrows. The boxes are the tables built with the SQL commands and are what the Python classes will model. The arrows are the relationships between the tables.
The models are Python classes inheriting from an SQLAlchemy Base клас. The Base class provides the interface operations between instances of the model and the database table.
Below is the models.py file that creates the models to represent the author_book_publisher.db база данни:
1from sqlalchemy import Column, Integer, String, ForeignKey, Table
2from sqlalchemy.orm import relationship, backref
3from sqlalchemy.ext.declarative import declarative_base
4
5Base = declarative_base()
6
7author_publisher = Table(
8 "author_publisher",
9 Base.metadata,
10 Column("author_id", Integer, ForeignKey("author.author_id")),
11 Column("publisher_id", Integer, ForeignKey("publisher.publisher_id")),
12)
13
14book_publisher = Table(
15 "book_publisher",
16 Base.metadata,
17 Column("book_id", Integer, ForeignKey("book.book_id")),
18 Column("publisher_id", Integer, ForeignKey("publisher.publisher_id")),
19)
20
21class Author(Base):
22 __tablename__ = "author"
23 author_id = Column(Integer, primary_key=True)
24 first_name = Column(String)
25 last_name = Column(String)
26 books = relationship("Book", backref=backref("author"))
27 publishers = relationship(
28 "Publisher", secondary=author_publisher, back_populates="authors"
29 )
30
31class Book(Base):
32 __tablename__ = "book"
33 book_id = Column(Integer, primary_key=True)
34 author_id = Column(Integer, ForeignKey("author.author_id"))
35 title = Column(String)
36 publishers = relationship(
37 "Publisher", secondary=book_publisher, back_populates="books"
38 )
39
40class Publisher(Base):
41 __tablename__ = "publisher"
42 publisher_id = Column(Integer, primary_key=True)
43 name = Column(String)
44 authors = relationship(
45 "Author", secondary=author_publisher, back_populates="publishers"
46 )
47 books = relationship(
48 "Book", secondary=book_publisher, back_populates="publishers"
49 )
Here’s what’s going on in this module:
-
Line 1 imports the
Column,Integer,String,ForeignKey, andTableclasses from SQLAlchemy, which are used to help define the model attributes. -
Line 2 imports the
relationship()andbackrefobjects, which are used to create the relationships between objects. -
Line 3 imports the
declarative_baseobject, which connects the database engine to the SQLAlchemy functionality of the models. -
Line 5 creates the
Baseclass, which is what all models inherit from and how they get SQLAlchemy ORM functionality. -
Lines 7 to 12 create the
author_publisherassociation table model. -
Lines 14 to 19 create the
book_publisherassociation table model. -
Lines 21 to 29 define the
Authorclass model to theauthordatabase table. -
Lines 31 to 38 define the
Bookclass model to thebookdatabase table. -
Lines 40 to 49 define the
Publisherclass model to thepublisherdatabase table.
The description above shows the mapping of the five tables in the author_book_publisher.db database. But it glosses over some SQLAlchemy ORM features, including Table , ForeignKey , relationship() , and backref . Let’s get into those now.
Table Creates Associations
author_publisher and book_publisher are both instances of the Table class that create the many-to-many association tables used between the author and publisher tables and the book and publisher tables, respectively.
The SQLAlchemy Table class creates a unique instance of an ORM mapped table within the database. The first parameter is the table name as defined in the database, and the second is Base.metadata , which provides the connection between the SQLAlchemy functionality and the database engine.
The rest of the parameters are instances of the Column class defining the table fields by name, their type, and in the example above, an instance of a ForeignKey .
ForeignKey Creates a Connection
The SQLAlchemy ForeignKey class defines a dependency between two Column fields in different tables. A ForeignKey is how you make SQLAlchemy aware of the relationships between tables. For example, this line from the author_publisher instance creation establishes a foreign key relationship:
Column("author_id", Integer, ForeignKey("author.author_id"))
The statement above tells SQLAlchemy that there’s a column in the author_publisher table named author_id . The type of that column is Integer , and author_id is a foreign key related to the primary key in the author таблица.
Having both author_id and publisher_id defined in the author_publisher Table instance creates the connection from the author table to the publisher table and vice versa, establishing a many-to-many relationship.
relationship() Establishes a Collection
Having a ForeignKey defines the existence of the relationship between tables but not the collection of books an author can have. Take a look at this line in the Author class definition:
books = relationship("Book", backref=backref("author"))
The code above defines a parent-child collection. The books attribute being plural (which is not a requirement, just a convention) is an indication that it’s a collection.
The first parameter to relationship() , the class name Book (which is not the table name book ), is the class to which the books attribute is related. The relationship informs SQLAlchemy that there’s a relationship between the Author and Book classes. SQLAlchemy will find the relationship in the Book class definition:
author_id = Column(Integer, ForeignKey("author.author_id"))
SQLAlchemy recognizes that this is the ForeignKey connection point between the two classes. You’ll get to the backref parameter in relationship() in a moment.
The other relationship in Author is to the Publisher клас. This is created with the following statement in the Author class definition:
publishers = relationship(
"Publisher", secondary=author_publisher, back_populates="authors"
)
Like books , the attribute publishers indicates a collection of publishers associated with an author. The first parameter, "Publisher" , informs SQLAlchemy what the related class is. The second and third parameters are secondary=author_publisher and back_populates="authors" :
-
secondarytells SQLAlchemy that the relationship to thePublisherclass is through a secondary table, which is theauthor_publisherassociation table created earlier inmodels.py. Thesecondaryparameter makes SQLAlchemy find thepublisher_idForeignKeydefined in theauthor_publisherassociation table. -
back_populatesis a convenience configuration telling SQLAlchemy that there’s a complementary collection in thePublisherclass calledauthors.
backref Mirrors Attributes
The backref parameter of the books collection relationship() creates an author attribute for each Book instance. This attribute refers to the parent Author that the Book instance is related to.
For example, if you executed the following Python code, then a Book instance would be returned from the SQLAlchemy query. The Book instance has attributes that can be used to print out information about the book:
book = session.query(Book).filter_by(Book.title == "The Stand").one_or_none()
print(f"Authors name: {book.author.first_name} {book.author.last_name}")
The existence of the author attribute in the Book above is because of the backref определение. A backref can be very handy to have when you need to refer to the parent and all you have is a child instance.
Queries Answer Questions
You can make a basic query like SELECT * FROM author; in SQLAlchemy like this:
results = session.query(Author).all()
The session is an SQLAlchemy object used to communicate with SQLite in the Python example programs. Here, you tell the session you want to execute a query against the Author model and return all records.
At this point, the advantages of using SQLAlchemy instead of plain SQL might not be obvious, especially considering the setup required to create the models representing the database. The results returned by the query is where the magic happens. Instead of getting back a list of lists of scalar data, you’ll get back a list of instances of Author objects with attributes matching the column names you defined.
The books and publishers collections maintained by SQLAlchemy create a hierarchical list of authors and the books they’ve written as well as the publishers who’ve published them.
Behind the scenes, SQLAlchemy turns the object and method calls into SQL statements to execute against the SQLite database engine. SQLAlchemy transforms the data returned by SQL queries into Python objects.
With SQLAlchemy, you can perform the more complex aggregation query shown earlier for the list of authors and the number of books they’ve written like this:
author_book_totals = (
session.query(
Author.first_name,
Author.last_name,
func.count(Book.title).label("book_total")
)
.join(Book)
.group_by(Author.last_name)
.order_by(desc("book_total"))
.all()
)
The query above gets the author’s first and last name, along with a count of the number of books that the author has written. The aggregating count used by the group_by clause is based on the author’s last name. Finally, the results are sorted in descending order based on the aggregated and aliased book_total .
Example Program
The example program examples/example_2/main.py has the same functionality as examples/example_1/main.py but uses SQLAlchemy exclusively to interface with the author_book_publisher.db SQLite database. The program is broken up into the main() function and the functions it calls:
1def main():
2 """Main entry point of program"""
3 # Connect to the database using SQLAlchemy
4 with resources.path(
5 "project.data", "author_book_publisher.db"
6 ) as sqlite_filepath:
7 engine = create_engine(f"sqlite:///{sqlite_filepath}")
8 Session = sessionmaker()
9 Session.configure(bind=engine)
10 session = Session()
11
12 # Get the number of books printed by each publisher
13 books_by_publisher = get_books_by_publishers(session, ascending=False)
14 for row in books_by_publisher:
15 print(f"Publisher: {row.name}, total books: {row.total_books}")
16 print()
17
18 # Get the number of authors each publisher publishes
19 authors_by_publisher = get_authors_by_publishers(session)
20 for row in authors_by_publisher:
21 print(f"Publisher: {row.name}, total authors: {row.total_authors}")
22 print()
23
24 # Output hierarchical author data
25 authors = get_authors(session)
26 output_author_hierarchy(authors)
27
28 # Add a new book
29 add_new_book(
30 session,
31 author_name="Stephen King",
32 book_title="The Stand",
33 publisher_name="Random House",
34 )
35 # Output the updated hierarchical author data
36 authors = get_authors(session)
37 output_author_hierarchy(authors)
This program is a modified version of examples/example_1/main.py . Let’s go over the differences:
-
Lines 4 to 7 first initialize the
sqlite_filepathvariable to the database file path. Then they create theenginevariable to communicate with SQLite and theauthor_book_publisher.dbdatabase file, which is SQLAlchemy’s access point to the database. -
Line 8 creates the
Sessionclass from the SQLAlchemy’ssessionmaker(). -
Line 9 binds the
Sessionto the engine created in line 8. -
Line 10 creates the
sessioninstance, which is used by the program to communicate with SQLAlchemy.
The rest of the function is similar, except for the replacement of data with session as the first parameter to all the functions called by main() .
get_books_by_publisher() has been refactored to use SQLAlchemy and the models you defined earlier to get the data requested:
1def get_books_by_publishers(session, ascending=True):
2 """Get a list of publishers and the number of books they've published"""
3 if not isinstance(ascending, bool):
4 raise ValueError(f"Sorting value invalid: {ascending}")
5
6 direction = asc if ascending else desc
7
8 return (
9 session.query(
10 Publisher.name, func.count(Book.title).label("total_books")
11 )
12 .join(Publisher.books)
13 .group_by(Publisher.name)
14 .order_by(direction("total_books"))
15 )
Here’s what the new function, get_books_by_publishers() , is doing:
-
Line 6 creates the
directionvariable and sets it equal to the SQLAlchemydescorascfunction depending on the value of theascendingпараметър. -
Lines 9 to 11 query the
Publishertable for data to return, which in this case arePublisher.nameand the aggregate total ofBookobjects associated with an author, aliased tototal_books. -
Line 12 joins to the
Publisher.booksколекция. -
Line 13 aggregates the book counts by the
Publisher.nameattribute. -
Line 14 sorts the output by the book counts according to the operator defined by
direction. -
Line 15 closes the object, executes the query, and returns the results to the caller.
All the above code expresses what is wanted rather than how it’s to be retrieved. Now instead of using SQL to describe what’s wanted, you’re using Python objects and methods. What’s returned is a list of Python objects instead of a list of tuples of data.
get_authors_by_publisher() has also been modified to work exclusively with SQLAlchemy. Its functionality is very similar to the previous function, so a function description is omitted:
def get_authors_by_publishers(session, ascending=True):
"""Get a list of publishers and the number of authors they've published"""
if not isinstance(ascending, bool):
raise ValueError(f"Sorting value invalid: {ascending}")
direction = asc if ascending else desc
return (
session.query(
Publisher.name,
func.count(Author.first_name).label("total_authors"),
)
.join(Publisher.authors)
.group_by(Publisher.name)
.order_by(direction("total_authors"))
)
get_authors() has been added to get a list of authors sorted by their last names. The result of this query is a list of Author objects containing a collection of books. The Author objects already contain hierarchical data, so the results don’t have to be reformatted:
def get_authors(session):
"""Get a list of author objects sorted by last name"""
return session.query(Author).order_by(Author.last_name).all()
Like its previous version, add_new_book() is relatively complex but straightforward to understand. It determines if a book with the same title, author, and publisher exists in the database already.
If the search query finds an exact match, then the function returns. If no book matches the exact search criteria, then it searches to see if the author has written a book using the passed in title. This code exists to prevent duplicate books from being created in the database.
If no matching book exists, and the author hasn’t written one with the same title, then a new book is created. The function then retrieves or creates an author and publisher. Once instances of the Book , Author and Publisher exist, the relationships between them are created, and the resulting information is saved to the database:
1def add_new_book(session, author_name, book_title, publisher_name):
2 """Adds a new book to the system"""
3 # Get the author's first and last names
4 first_name, _, last_name = author_name.partition(" ")
5
6 # Check if book exists
7 book = (
8 session.query(Book)
9 .join(Author)
10 .filter(Book.title == book_title)
11 .filter(
12 and_(
13 Author.first_name == first_name, Author.last_name == last_name
14 )
15 )
16 .filter(Book.publishers.any(Publisher.name == publisher_name))
17 .one_or_none()
18 )
19 # Does the book by the author and publisher already exist?
20 if book is not None:
21 return
22
23 # Get the book by the author
24 book = (
25 session.query(Book)
26 .join(Author)
27 .filter(Book.title == book_title)
28 .filter(
29 and_(
30 Author.first_name == first_name, Author.last_name == last_name
31 )
32 )
33 .one_or_none()
34 )
35 # Create the new book if needed
36 if book is None:
37 book = Book(title=book_title)
38
39 # Get the author
40 author = (
41 session.query(Author)
42 .filter(
43 and_(
44 Author.first_name == first_name, Author.last_name == last_name
45 )
46 )
47 .one_or_none()
48 )
49 # Do we need to create the author?
50 if author is None:
51 author = Author(first_name=first_name, last_name=last_name)
52 session.add(author)
53
54 # Get the publisher
55 publisher = (
56 session.query(Publisher)
57 .filter(Publisher.name == publisher_name)
58 .one_or_none()
59 )
60 # Do we need to create the publisher?
61 if publisher is None:
62 publisher = Publisher(name=publisher_name)
63 session.add(publisher)
64
65 # Initialize the book relationships
66 book.author = author
67 book.publishers.append(publisher)
68 session.add(book)
69
70 # Commit to the database
71 session.commit()
The code above is relatively long. Let’s break the functionality down to manageable sections:
-
Lines 7 to 18 set the
bookvariable to an instance of aBookif a book with the same title, author, and publisher is found. Otherwise, they setbooktoNone. -
Lines 20 and 21 determine if the book already exists and return if it does.
-
Lines 24 to 37 set the
bookvariable to an instance of aBookif a book with the same title and author is found. Otherwise, they create a newBookinstance. -
Lines 40 to 52 set the
authorvariable to an existing author, if found, or create a newAuthorinstance based on the passed-in author name. -
Lines 55 to 63 set the
publishervariable to an existing publisher, if found, or create a newPublisherinstance based on the passed-in publisher name. -
Line 66 sets the
book.authorinstance to theauthorinstance. This creates the relationship between the author and the book, which SQLAlchemy will create in the database when the session is committed. -
Line 67 adds the
publisherinstance to thebook.publishersколекция. This creates the many-to-many relationship between thebookandpublisherмаси. SQLAlchemy will create references in the tables as well as in thebook_publisherassociation table that connects the two. -
Line 68 adds the
Bookinstance to the session, making it part of the session’s unit of work. -
Line 71 commits all the creations and updates to the database.
There are a few things to take note of here. First, there’s is no mention of the author_publisher or book_publisher association tables in either the queries or the creations and updates. Because of the work you did in models.py setting up the relationships, SQLAlchemy can handle connecting objects together and keeping those tables in sync during creations and updates.
Second, all the creations and updates happen within the context of the session обект. None of that activity is touching the database. Only when the session.commit() statement executes does the session then go through its unit of work and commit that work to the database.
For example, if a new Book instance is created (as in line 37 above), then the book has its attributes initialized except for the book_id primary key and author_id foreign key. Because no database activity has happened yet, the book_id is unknown, and nothing was done in the instantiation of book to give it an author_id .
When session.commit() is executed, one of the things it will do is insert book into the database, at which point the database will create the book_id primary key. The session will then initialize the book.book_id value with the primary key value created by the database engine.
session.commit() is also aware of the insertion of the Book instance in the author.books колекция. The author object’s author_id primary key will be added to the Book instance appended to the author.books collection as the author_id foreign key.
Providing Access to Multiple Users
To this point, you’ve seen how to use pandas, SQLite, and SQLAlchemy to access the same data in different ways. For the relatively straightforward use case of the author, book, and publisher data, it could still be a toss-up whether you should use a database.
One deciding factor when choosing between using a flat file or a database is data and relationship complexity. If the data for each entity is complicated and contains many relationships between the entities, then creating and maintaining it in a flat file might become more difficult.
Another factor to consider is whether you want to share the data between multiple users. The solution to this problem might be as simple as using a sneakernet to physically move data between users. Moving data files around this way has the advantage of ease of use, but the data can quickly get out of sync when changes are made.
The problem of keeping the data consistent for all users becomes even more difficult if the users are remote and want to access the data across networks. Even when you’re limited to a single language like Python and using pandas to access the data, network file locking isn’t sufficient to ensure the data doesn’t get corrupted.
Providing the data through a server application and a user interface alleviates this problem. The server is the only application that needs file-level access to the database. By using a database, the server can take advantage of SQL to access the data using a consistent interface no matter what programming language the server uses.
The last example program demonstrates this by providing a web application and user interface to the Chinook sample SQLite database. Peter Stark generously maintains the Chinook database as part of the SQLite Tutorial site. If you’d like to learn more about SQLite and SQL in general, then the site is a great resource.
The Chinook database provides artist, music, and playlist information along the lines of a simplified Spotify. The database is part of the example code project in the project/data folder.
Using Flask With Python, SQLite, and SQLAlchemy
The examples/example_3/chinook_server.py program creates a Flask application that you can interact with using a browser. The application makes use of the following technologies:
-
Flask Blueprint is part of Flask and provides a good way to follow the separation of concerns design principle and create distinct modules to contain functionality.
-
Flask SQLAlchemy is an extension for Flask that adds support for SQLAlchemy in your web applications.
-
Flask_Bootstrap4 packages the Bootstrap front-end tool kit, integrating it with your Flask web applications.
-
Flask_WTF extends Flask with WTForms, giving your web applications a useful way to generate and validate web forms.
-
python_dotenv is a Python module that an application uses to read environment variables from a file and keep sensitive information out of program code.
Though not necessary for this example, a .env file holds the environment variables for the application. The .env file exists to contain sensitive information like passwords, which you should keep out of your code files. However, the content of the project .env file is shown below since it doesn’t contain any sensitive data:
SECRET_KEY = "you-will-never-guess"
SQLALCHEMY_TRACK_MODIFICATIONS = False
SQLAlCHEMY_ECHO = False
DEBUG = True
The example application is fairly large, and only some of it is relevant to this tutorial. For this reason, examining and learning from the code is left as an exercise for the reader. That said, you can take a look at an animated screen capture of the application below, followed by the HTML that renders the home page and the Python Flask route that provides the dynamic data.
Here’s the application in action, navigating through various menus and features:
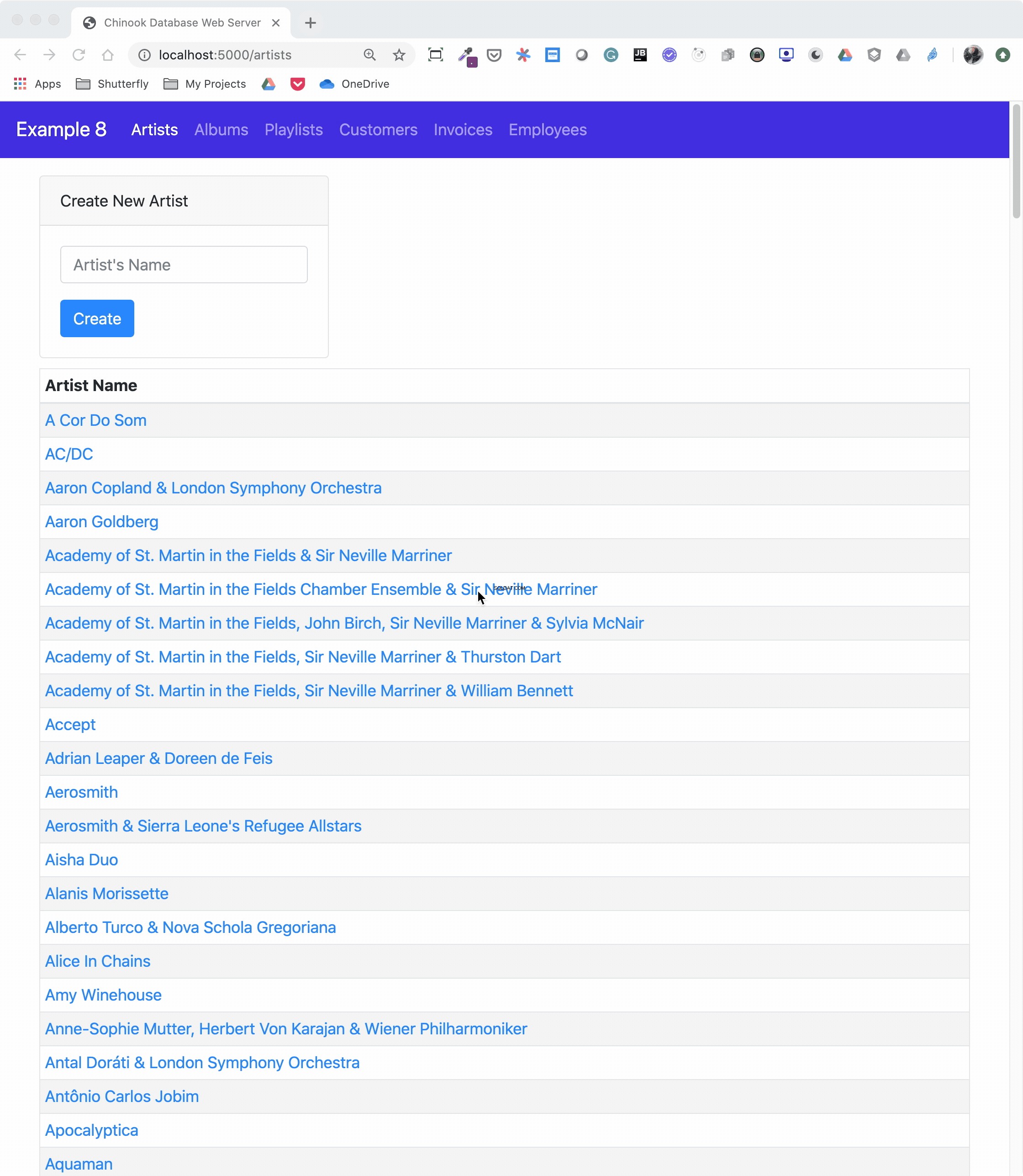
The animated screen capture starts on the application home page, styled using Bootstrap 4. The page displays the artists in the database, sorted in ascending order. The remainder of the screen capture presents the results of clicking on the displayed links or navigating around the application from the top-level menu.
Here’s the Jinja2 HTML template that generates the home page of the application:
1{% extends "base.html" %}
2
3{% block content %}
4<div class="container-fluid">
5 <div class="m-4">
6 <div class="card" style="width: 18rem;">
7 <div class="card-header">Create New Artist</div>
8 <div class="card-body">
9 <form method="POST" action="{{url_for('artists_bp.artists')}}">
10 {{ form.csrf_token }}
11 {{ render_field(form.name, placeholder=form.name.label.text) }}
12 <button type="submit" class="btn btn-primary">Create</button>
13 </form>
14 </div>
15 </div>
16 <table class="table table-striped table-bordered table-hover table-sm">
17 <caption>List of Artists</caption>
18 <thead>
19 <tr>
20 <th>Artist Name</th>
21 </tr>
22 </thead>
23 <tbody>
24 {% for artist in artists %}
25 <tr>
26 <td>
27 <a href="{{url_for('albums_bp.albums', artist_id=artist.artist_id)}}">
28 {{ artist.name }}
29 </a>
30 </td>
31 </tr>
32 {% endfor %}
33 </tbody>
34 </table>
35 </div>
36</div>
37{% endblock %}
Here’s what’s going on in this Jinja2 template code:
-
Line 1 uses Jinja2 template inheritance to build this template from the
base.htmltemplate. Thebase.htmltemplate contains all the HTML5 boilerplate code as well as the Bootstrap navigation bar consistent across all pages of the site. -
Lines 3 to 37 contain the block content of the page, which is incorporated into the Jinja2 macro of the same name in the
base.htmlbase template. -
Lines 9 to 13 render the form to create a new artist. This uses the features of Flask-WTF to generate the form.
-
Lines 24 to 32 create a
forloop that renders the table of artist names. -
Lines 27 to 29 render the artist name as a link to the artist’s album page showing the songs associated with a particular artist.
Here’s the Python route that renders the page:
1from flask import Blueprint, render_template, redirect, url_for
2from flask_wtf import FlaskForm
3from wtforms import StringField
4from wtforms.validators import InputRequired, ValidationError
5from app import db
6from app.models import Artist
7
8# Set up the blueprint
9artists_bp = Blueprint(
10 "artists_bp", __name__, template_folder="templates", static_folder="static"
11)
12
13def does_artist_exist(form, field):
14 artist = (
15 db.session.query(Artist)
16 .filter(Artist.name == field.data)
17 .one_or_none()
18 )
19 if artist is not None:
20 raise ValidationError("Artist already exists", field.data)
21
22class CreateArtistForm(FlaskForm):
23 name = StringField(
24 label="Artist's Name", validators=[InputRequired(), does_artist_exist]
25 )
26
27@artists_bp.route("/")
28@artists_bp.route("/artists", methods=["GET", "POST"])
29def artists():
30 form = CreateArtistForm()
31
32 # Is the form valid?
33 if form.validate_on_submit():
34 # Create new artist
35 artist = Artist(name=form.name.data)
36 db.session.add(artist)
37 db.session.commit()
38 return redirect(url_for("artists_bp.artists"))
39
40 artists = db.session.query(Artist).order_by(Artist.name).all()
41 return render_template("artists.html", artists=artists, form=form,)
Let’s go over what the above code is doing:
-
Lines 1 to 6 import all the modules necessary to render the page and initialize forms with data from the database.
-
Lines 9 to 11 create the blueprint for the artists page.
-
Lines 13 to 20 create a custom validator function for the Flask-WTF forms to make sure a request to create a new artist doesn’t conflict with an already existing artist.
-
Lines 22 to 25 create the form class to handle the artist form rendered in the browser and provide validation of the form field inputs.
-
Lines 27 to 28 connect two routes to the
artists()function they decorate. -
Line 30 creates an instance of the
CreateArtistForm()клас. -
Line 33 determines if the page was requested through the HTTP methods GET or POST (submit). If it was a POST, then it also validates the fields of the form and informs the user if the fields are invalid.
-
Lines 35 to 37 create a new artist object, add it to the SQLAlchemy session, and commit the artist object to the database, persisting it.
-
Line 38 redirects back to the artists page, which will be rerendered with the newly created artist.
-
Line 40 runs an SQLAlchemy query to get all the artists in the database and sort them by
Artist.name. -
Line 41 renders the artists page if the HTTP request method was a GET.
You can see that a great deal of functionality is created by a reasonably small amount of code.
Creating a REST API Server
You can also create a web server providing a REST API. This kind of server offers URL endpoints responding with data, often in JSON format. A server providing REST API endpoints can be used by JavaScript single-page web applications through the use of AJAX HTTP requests.
Flask is an excellent tool for creating REST applications. For a multi-part series of tutorials about using Flask, Connexion, and SQLAlchemy to create REST applications, check out Python REST APIs With Flask, Connexion, and SQLAlchemy.
If you’re a fan of Django and are interested in creating REST APIs, then check out Django Rest Framework – An Introduction and Create a Super Basic REST API with Django Tastypie.
Забележка: It’s reasonable to ask if SQLite is the right choice as the database backend to a web application. The SQLite website states that SQLite is a good choice for sites that serve around 100,000 hits per day. If your site gets more daily hits, the first thing to say is congratulations!
Beyond that, if you’ve implemented your website with SQLAlchemy, then it’s possible to move the data from SQLite to another database such as MySQL or PostgreSQL. For a comparison of SQLite, MySQL, and PostgreSQL that will help you make decisions about which one will serve your application best, check out Introduction to Python SQL Libraries.
It’s well worth considering SQLite for your Python application, no matter what it is. Using a database gives your application versatility, and it might create surprising opportunities to add additional features.
Заключение
You’ve covered a lot of ground in this tutorial about databases, SQLite, SQL, and SQLAlchemy! You’ve used these tools to move data contained in flat files to an SQLite database, access the data with SQL and SQLAlchemy, and provide that data through a web server.
In this tutorial, you’ve learned:
- Why an SQLite database can be a compelling alternative to flat-file data storage
- How to normalize data to reduce data redundancy and increase data integrity
- How to use SQLAlchemy to work with databases in an object-oriented manner
- How to build a web application to serve a database to multiple users
Working with databases is a powerful abstraction for working with data that adds significant functionality to your Python programs and allows you to ask interesting questions of your data.
You can get all of the code and data you saw in this tutorial at the link below:
Download the sample code: Click here to get the code you’ll use to learn about data management with SQLite and SQLAlchemy in this tutorial.
Further Reading
This tutorial is an introduction to using databases, SQL, and SQLAlchemy, but there’s much more to learn about these subjects. These are powerful, sophisticated tools that no single tutorial can cover adequately. Here are some resources for additional information to expand your skills:
-
If your application will expose the database to users, then avoiding SQL injection attacks is an important skill. For more information, check out Preventing SQL Injection Attacks With Python.
-
Providing web access to a database is common in web-based single-page applications. To learn how, check out Python REST APIs With Flask, Connexion, and SQLAlchemy – Part 2.
-
Preparing for data engineering job interviews gives you a leg up in your career. To get started, check out Data Engineer Interview Questions With Python.
-
Migrating data and being able to roll back using Flask with Postgres and SQLAlchemy is an integral part of the Software Development Life Cycle (SDLC). You can learn more about it by checking out Flask by Example – Setting up Postgres, SQLAlchemy, and Alembic.



