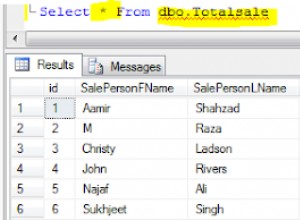
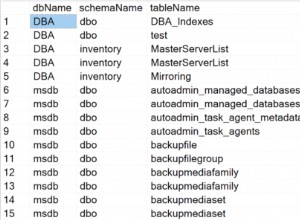
Опитайте това:
;with cte as
(select *,
coalesce(row_index - (lag(row_index) over (order by event)),1) diff
from tbl
),
cte2 as
(select *,
(select max(diff)
from cte c
where c.row_index <= d.row_index
) minri
from cte d
)
select event, row_index, minri,
dense_rank() over (order by minri) rn
from cte2
- Първият CTE получава разликите с помощта на
lagфункция (достъпна от SQL Server 2012 нататък). - Следващият CTE изчислява, когато разликата надвиши 1 и присвоява всички записи след тази точка на „група“, докато бъде намерена следващата разлика <> 1. Това е ключовата стъпка в групирането.
- Последната стъпка е да използвате
dense_rankвърху индикатора, изчислен в предишната стъпка, за да получите необходимите номера на редовете.
Това решение има ограничение в това, че ще се провали, ако разликите не са във възходящ ред, т.е. ако имате още две стойности в примерните данни като 52 и 53, ще ги класифицира в група 3, вместо да създава нова група.
Актуализация :Подходът по-долу може да преодолее горното ограничение:
;with cte as
(select *,
coalesce(row_index - (lag(row_index) over (order by event)),1) diff
from tbl)
,cte2 as
(select *,
diff - coalesce(diff - (lag(diff) over (order by event)),0) tmp
from cte d)
select event,row_index,
1 + sum(case when tmp >= diff then 0 else 1 end) over (order by event) risum
from cte2
Отново първата стъпка остава същата. Но в стъпка 2 ние проверяваме само за преход към различна стойност на разликата между последователни стойности, вместо да използваме функция min/max. След това класирането използва условна сума, за да присвои група за всяка стойност в оригиналните данни.
Това може допълнително да се опрости до:
select event, row_index,
sum(case when diff <= 1 then 0 else 1 end) over (order by event) as rb
from
(select *,
row_index - (lag(row_index) over (order by event)) diff
from tbl
) s