Тези тестове (база данни AdventureWorks2008R2) показват какво се случва:
SET NOCOUNT ON;
SET STATISTICS IO ON;
PRINT 'Test #1';
SELECT p.BusinessEntityID, p.LastName
FROM Person.Person p
WHERE p.LastName LIKE '%be%';
PRINT 'Test #2';
DECLARE @Pattern NVARCHAR(50);
SET @Pattern=N'%be%';
SELECT p.BusinessEntityID, p.LastName
FROM Person.Person p
WHERE p.LastName LIKE @Pattern;
SET STATISTICS IO OFF;
SET NOCOUNT OFF;
Резултати:
Test #1
Table 'Person'. Scan count 1, logical reads 106
Test #2
Table 'Person'. Scan count 1, logical reads 106
Резултатите от SET STATISTICS IO показва, че LIO са сищите .Но плановете за изпълнение са доста различни: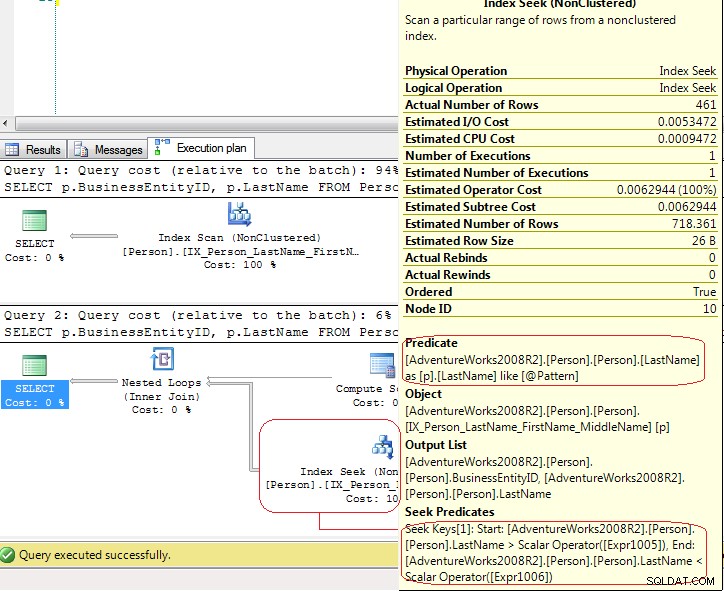
В първия тест SQL Server използва Index Scan изрично, но във втория тест SQL Server използва Index Seek което е Index Seek - range scan . В последния случай SQL Server използва Compute Scalar оператор за генериране на тези стойности
[Expr1005] = Scalar Operator(LikeRangeStart([@Pattern])),
[Expr1006] = Scalar Operator(LikeRangeEnd([@Pattern])),
[Expr1007] = Scalar Operator(LikeRangeInfo([@Pattern]))
и Index Seek оператор използва Seek Predicate (оптимизирано) за range scan (LastName > LikeRangeStart AND LastName < LikeRangeEnd ) плюс друг неоптимизиран Predicate (LastName LIKE @pattern ).
Моят отговор:това не е „истинско“ Index Seek . Това е Index Seek - range scan което в този случай има същата производителност като Index Scan .
Моля, вижте също разликата между Index Seek и Index Scan (подобен дебат):И така...търсене ли е или сканиране?
.
Редактиране 1: Планът за изпълнение за OPTION(RECOMPILE) (вижте препоръката на Aaron, моля) показва също и Index Scan (вместо Index Seek ):