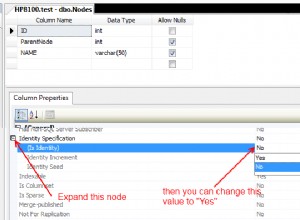
Две решения, и двете наистина за промяна на проблема в по-лесен. Обикновено бих предпочел T1 решение, ако налагането на промяна на потребителите е приемливо:
create table dbo.T1 (
Lft int not null,
Rgt int not null,
constraint CK_T1 CHECK (Lft < Rgt),
constraint UQ_T1 UNIQUE (Lft,Rgt)
)
go
create table dbo.T2 (
Lft int not null,
Rgt int not null
)
go
create view dbo.T2_DRI
with schemabinding
as
select
CASE WHEN Lft<Rgt THEN Lft ELSE Rgt END as Lft,
CASE WHEN Lft<Rgt THEN Rgt ELSE Lft END as Rgt
from dbo.T2
go
create unique clustered index IX_T2_DRI on dbo.T2_DRI(Lft,Rgt)
go
И в двата случая нито T1 нито T2 може да съдържа дублирани стойности в Lft,Rgt двойки.