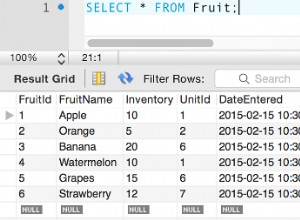
Ако използвате SQL Server, можете да използвате израз за изтриване от обща таблица:
with cte as (
select row_number() over(partition by SICComb, NameComb order by Col1) as row_num
from Table1
)
delete
from cte
where row_num > 1
Тук всички редове ще бъдат номерирани, получавате собствена последователност за всяка уникална комбинация от SICComb + NameComb . Можете да изберете кои редове искате да изтриете, като изберете order by вътре в over клауза.