MySQL репликацията е най-често срещаното и широко използвано решение за висока наличност от огромни организации като Github, Twitter и Facebook. Въпреки че е лесно да се настрои, има предизвикателства, пред които се сблъскват при използването на това решение от поддръжката, включително надстройки на софтуера, отклоняване на данни или несъответствие на данните между възлите на репликата, промени в топологията, преминаване при отказ и възстановяване. Когато MySQL пусна версия 5.6, той донесе редица значителни подобрения, особено за репликацията, която включва глобални идентификатори на транзакции (GTID), контролни суми на събития, многонишкови подчинени и безопасни от срив подчинени/главни. Репликацията стана още по-добра с MySQL 5.7 и MySQL 8.0.
Репликацията позволява данни от един MySQL сървър (основния/главен) да бъдат репликирани на един или повече MySQL сървъри (репликата/подчинените). MySQL репликацията е много лесна за настройка и се използва за мащабиране на работните натоварвания за четене, осигуряване на висока наличност и географска резервираност и разтоварване на архивиране и аналитични задачи.
Репликация на MySQL в природата
Нека направим бърз преглед на това как MySQL репликацията работи в природата. MySQL репликацията е широка и има множество начини да я конфигурирате и как може да се използва. По подразбиране той използва асинхронна репликация, която работи, когато транзакцията е завършена в локалната среда. Няма гаранция, че някое събитие някога ще достигне до някой роб. Това е слабо свързана връзка главен-подчинен, където:
-
Основният не чака реплика.
-
Репликата определя колко да се чете и от коя точка в двоичния журнал.
-
Репликата може да бъде произволно зад master при четене или прилагане на промените.
Ако основният се срине, транзакциите, които е извършил, може да не са били предадени на реплика. Следователно, преминаването на отказ от първичен към най-усъвършенстваната реплика в този случай може да доведе до преминаване към желания първичен, при който всъщност липсват транзакции спрямо предишния сървър.
Асинхронната репликация осигурява по-ниска латентност при запис, тъй като записът се потвърждава локално от главен, преди да бъде записан в подчинени. Той е чудесен за мащабиране на четене, тъй като добавянето на повече реплики не влияе на забавянето на репликацията. Добрите случаи на използване на асинхронна репликация включват внедряване на реплики за четене за мащабиране на четене, архивно копие на живо за възстановяване след бедствие и анализи/отчитане.
Полусинхронна репликация на MySQL
MySQL също поддържа полусинхронна репликация, при която главният не потвърждава транзакциите на клиента, докато поне един подчинен не е копирал промяната в своя регистрационен файл на релето и не го е прехвърлил на диск. За да активирате полусинхронна репликация, са необходими допълнителни стъпки за инсталиране на плъгини и трябва да бъдат активирани на определените главни и подчинени възли на MySQL.
Полусинхронният изглежда е добро и практично решение за много случаи, когато високата наличност и липсата на загуба на данни са важни. Но трябва да имате предвид, че полусинхронното има влияние върху производителността поради допълнителното двупосочно пътуване и не предоставя силни гаранции срещу загуба на данни. Когато комитът се върне успешно, се знае, че данните съществуват на поне две места (на главен и поне един подчинен). Ако главният извърши, но възникне срив, докато главният чака потвърждение от подчинен, възможно е транзакцията да не е достигнала до нито един подчинен. Това не е толкова голям проблем, тъй като в този случай ангажиментът няма да бъде върнат в приложението. Задачата на приложението е да опита отново транзакцията в бъдеще. Това, което е от съществено значение, което трябва да се има предвид, е, че когато главният се провали и робът е повишен, старият господар не може да се присъедини към веригата за репликация. При някои обстоятелства това може да доведе до конфликти с данните за подчинените, т.е. когато главният се срине, след като ведомото е получило събитието за двоичен журнал, но преди главният да получи потвърждението от подчинения). По този начин единственият безопасен начин е да изхвърлите данните на стария главен файл и да ги предоставите от нулата, като използвате данните от новоповишения главен код.
Неправилно използване на формата за репликация
След MySQL 5.7.7, двоичният формат на регистрационния файл по подразбиране или променливата binlog_format използва ROW, който беше STATEMENT преди 5.7.7. Различните формати на репликация съответстват на метода, използван за записване на събитията в двоичен журнал на източника. Репликацията работи, защото събитията, записани в двоичния дневник, се четат от източника и след това се обработват в репликата. Събитията се записват в двоичния дневник в различни формати на репликация според типа на събитието. Незнанието със сигурност какво да използвате може да бъде проблем. MySQL има три формата на методи за репликация:STATEMENT, ROW и MIXED.
-
Форматът за репликация, базиран на STATEMENT (SBR) е точно това, което е – репликационен поток от всяко изпълнение на оператор на главния, който ще бъде възпроизведен на подчинения възел. По подразбиране традиционната (асинхронна) репликация на MySQL не изпълнява паралелно реплицираните транзакции към подчинените. Това означава, че редът на изразите в потока за репликация може да не е 100% същият. Също така, повторното възпроизвеждане на оператор може да даде различни резултати, когато не се изпълнява едновременно, както когато се изпълнява от източника. Това води до непоследователно състояние спрямо първичния елемент и неговите реплика(и). Това не беше проблем в продължение на много години, тъй като не много работеха с MySQL с много едновременни нишки. Въпреки това, при съвременните многопроцесорни архитектури това всъщност стана много вероятно при нормално ежедневно натоварване.
-
Форматът за репликация на ROW предоставя решения, които липсват на SBR. Когато се използва формат за регистриране на базата на редове репликация (RBR), източникът записва събития в двоичния дневник, които показват как се променят отделните редове в таблицата. Репликацията от източник към репликата работи чрез копиране на събитията, представляващи промените в редовете на таблицата, към репликата. Това означава, че могат да се генерират повече данни, което засяга дисковото пространство в репликата и засяга мрежовия трафик и дисковия I/O. Помислете дали даден израз променя много редове, да кажем, че с оператор UPDATE RBR записва повече данни в двоичния дневник дори за изрази, които се връщат назад. Изпълнението на моментни снимки в даден момент също може да отнеме повече време. Възможно е да се появят проблеми с паралелността, като се има предвид времето за заключване, необходимо за записване на големи парчета данни в двоичния дневник.
-
Тогава има метод между тези два; репликация в смесен режим. Този тип репликация винаги ще репликира изрази, освен когато заявката съдържа функцията UUID(), тригери, съхранени процедури, UDF и няколко други изключения. Смесеният режим няма да реши проблема с отклонението на данните и, заедно с репликацията, базирана на изрази, трябва да се избягва.
Планирате ли да имате настройка за няколко главни?
Кръговата репликация (известна още като топология на пръстена) е известна и често срещана настройка за MySQL репликация. Използва се за стартиране на настройка с няколко главни (вижте изображението по-долу) и често е необходимо, ако имате среда с множество центрове за данни. Тъй като приложението не може да изчака главният център в другия център за данни да потвърди записите, се предпочита локален главен. Обикновено отместването на автоматично увеличение се използва за предотвратяване на сблъсъци на данни между главните. Общоприето решение е да се накарат двама главни да извършват запис помежду си по този начин.
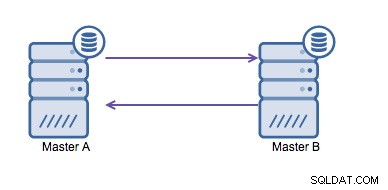
Ако обаче трябва да пишете в няколко центъра за данни в една и съща база данни , в крайна сметка получавате множество господари, които трябва да запишат своите данни един на друг. Преди MySQL 5.7.6 нямаше метод за извършване на репликация от тип мрежа, така че алтернативата би била да се използва репликация с кръгов пръстен.
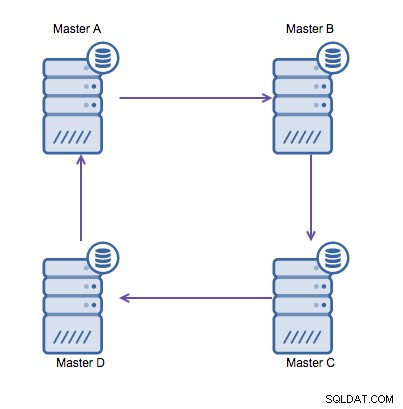
Репликацията на пръстен в MySQL е проблематична поради следните причини:забавяне, висока наличност и дрейф на данни. Записването на някои данни на сървър А ще отнеме три скока, за да се окаже на сървър D (чрез сървър B и C). Тъй като (традиционната) MySQL репликация е еднонишкова, всяка продължителна заявка в репликацията може да спре целия пръстен. Освен това, ако някой от сървърите се повреди, пръстенът ще бъде счупен и в момента никакъв софтуер за отказване не може да поправи структури на пръстена. Тогава може да възникне отклонение на данните, когато данните се записват на сървър A и се променят едновременно на сървър C или D.
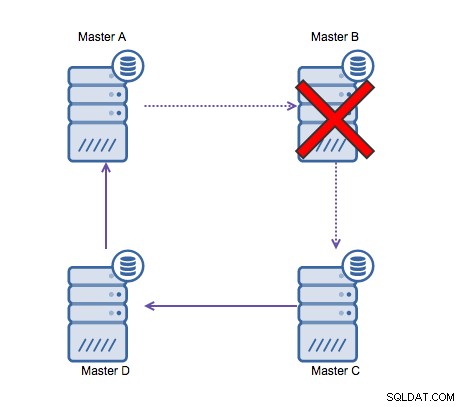
По принцип кръговата репликация не е подходяща за MySQL и трябва да бъде избягват на всяка цена. Тъй като е проектиран с оглед на това, Galera Cluster би бил добра алтернатива за писане в множество центрове за данни.
Отлагане на вашата репликация с големи актуализации
Различните пакетни задачи за домакинство често изпълняват различни задачи, вариращи от почистване на стари данни до изчисляване на средни стойности на „харесвания“, извлечени от друг източник. Това означава, че заданието ще създаде много активност на базата данни на определени интервали и най-вероятно ще запише много данни обратно в базата данни. Естествено, това означава, че активността в репликационния поток ще се увеличи еднакво.
Репликацията, базирана на оператори, ще репликира точните заявки, използвани в пакетните задания, така че ако обработката на заявката отне половин час на главния, подчинената нишка ще бъде спряна поне за същото количество време. Това означава, че никакви други данни не могат да се репликират и подчинените възли ще започнат да изостават от главния. Ако това надхвърли прага на вашия инструмент за отказване или прокси сървър, той може да изхвърли тези подчинени възли от наличните сървъри в клъстера. Ако използвате репликация, базирана на изрази, можете да предотвратите това, като разбиете данните за заданието си на по-малки партиди.
Сега може да мислите, че базираната на ред репликация не е засегната от това, тъй като тя ще репликира информацията за реда вместо заявката. Това отчасти е вярно, тъй като при промени в DDL репликацията се връща обратно към формат, базиран на изрази. Също така, голям брой CRUD (Създаване, Четене, Актуализиране, Изтриване) операции ще повлияят на потока за репликация. В повечето случаи това все още е еднонишкова операция и по този начин всяка транзакция ще чака предишната да бъде възпроизведена чрез репликация. Това означава, че ако имате висока степен на едновременност на главната, подчинената може да спре при претоварване на транзакции по време на репликация.
За да заобиколите това, MariaDB и MySQL предлагат паралелна репликация. Реализацията може да се различава в зависимост от доставчика и версията. MySQL 5.6 предлага паралелна репликация, стига заявките да са разделени от схемата. MariaDB 10.0 и MySQL 5.7 могат да обработват паралелна репликация в схеми, но имат други граници. Изпълнението на заявки чрез паралелни подчинени нишки може да ускори вашия репликационен поток, ако пишете тежко. В противен случай би било по-добре да се придържате към традиционната еднонишкова репликация.
Обработка на вашата промяна на схемата или DDL
След издаването на 5.7, управлението на промяната на схемата или промяната на DDL (език за дефиниране на данни) в MySQL се подобри много. До MySQL 8.0 поддържаните алгоритми за DDL промени са COPY и INPLACE.
-
КОПИРАНЕ:Този алгоритъм създава нова временна таблица с променената схема. След като мигрира напълно данните към новата временна таблица, тя разменя и пуска старата таблица.
-
INPLACE:Този алгоритъм изпълнява операции на място с оригиналната таблица и избягва копирането и повторното изграждане на таблицата, когато е възможно.
-
МОМЕНТАЛНО:Този алгоритъм е въведен от MySQL 8.0, но все още има ограничения.
В MySQL 8.0 беше въведен алгоритъмът INSTANT, който прави незабавни и на място промени в таблицата за добавяне на колони и позволява едновременно DML с подобрена отзивчивост и наличност в натоварени производствени среди. Това помага да се избегнат огромни забавяния и спирания в репликата, които обикновено са били големи проблеми от гледна точка на приложението, което води до извличане на остарели данни, тъй като показанията в подчинения все още не са актуализирани поради изоставане.
Въпреки че това е обещаващо подобрение, все още има ограничения с тях и понякога не е възможно да се приложат тези алгоритми INSTANT и INPLACE. Например, за алгоритмите INSTANT и INPLACE промяната на типа данни на колона също е обичайна задача на DBA, особено от гледна точка на разработването на приложения поради промяна на данните. Тези случаи са неизбежни; по този начин не можете да продължите с алгоритъма COPY, тъй като това заключва таблицата, причинявайки закъснения в подчинения. Той също така оказва влияние върху основния/главния сървър по време на това изпълнение, тъй като натрупва входящи транзакции, които също препращат към засегнатата таблица. Не можете да извършите директна промяна на ALTER или схема на натоварен сървър, тъй като това съпътства прекъсване или е възможно да повреди вашата база данни, ако загубите търпение, особено ако целевата таблица е огромна.
Вярно е, че извършването на промени в схемата при работеща производствена настройка винаги е предизвикателна задача. Често използвано решение е първо да се приложи промяната на схемата към подчинените възли. Това работи добре за репликация, базирана на изрази, но това може да работи само до известна степен за репликация, базирана на ред. Репликацията, базирана на редове, позволява да съществуват допълнителни колони в края на таблицата, така че стига да може да записва първите колони, ще бъде добре. Първо, приложете промяната към всички подчинени устройства, след това превключете на един от подчинените и след това приложете промяната към главния и го прикачете като подчинен. Ако промяната ви включва вмъкване на колона в средата или премахване на колона, това ще работи с репликация, базирана на редове.
Има налични инструменти, които могат да извършват промени в онлайн схемите по-надеждно. Промяната на Percona Online Schema (известна като pt-osc) и gh-ost от Schlomi Noach са често използвани от администраторите на база данни. Тези инструменти се справят ефективно с промените в схемата чрез групиране на засегнатите редове в парчета и тези парчета могат да бъдат конфигурирани съответно в зависимост от това колко искате да групирате.
Ако ще прескочите с pt-osc, този инструмент ще създаде сенчеста таблица с новата структура на таблицата, ще вмъкне нови данни чрез тригери и данни за запълване на заден план. След като приключи създаването на новата таблица, тя просто ще замени старата с новата таблица в транзакция. Това не работи във всички случаи, особено ако съществуващата ви таблица вече има тригери.
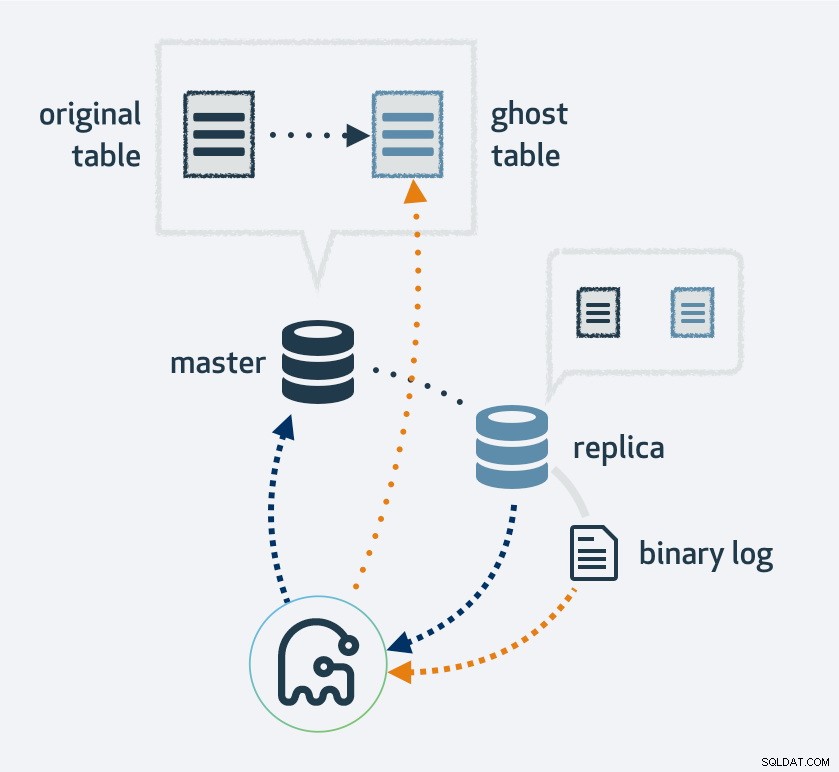
Използването на gh-ost първо ще направи копие на съществуващото оформление на таблицата, променете таблицата към новото оформление и след това свържете процеса като MySQL реплика. Той ще използва репликационния поток, за да намери нови редове, които са били вмъкнати в оригиналната таблица и в същото време запълва таблицата. След като приключи запълването, оригиналната и новата таблици ще се сменят. Естествено, всички операции към новата таблица ще завършат в репликационния поток; по този начин на всяка реплика миграцията се случва едновременно.
Таблици с памет и репликация
Докато сме по темата за DDL, често срещан проблем е създаването на таблици с памет. Таблиците с памет са непостоянни таблици, структурата им остава, но губят данните си след рестарт на MySQL. Когато създавате нова таблица с памет както на главен, така и на подчинен, те ще имат празна таблица, която ще работи перфектно. След като някоя от тях бъде рестартирана, таблицата ще бъде изпразнена и ще възникнат грешки при репликация.
Репликацията, базирана на ред, ще се прекъсне, след като данните в подчинения възел върне различни резултати, а базираната на изрази репликация ще прекъсне, след като се опита да вмъкне данни, които вече съществуват. За таблици с памет това е често прекъсване на репликацията. Поправката е лесна:направете ново копие на данните, променете двигателя на InnoDB и вече трябва да е безопасен за репликация.
Задаване на read_only={True|1}
Разбира се, това е възможен случай, когато използвате топология на пръстена и ние не насърчаваме използването на топология на пръстена, ако е възможно. По-рано описахме, че липсата на същите данни в подчинените възли може да наруши репликацията. Често това се причинява от нещо (или някой), който променя данните на подчинения възел, но не и на главния възел. След като данните на главния възел се променят, това ще бъде репликирано на подчинения, където не може да приложи промяната и това причинява прекъсване на репликацията. Това може също да доведе до повреда на данните на ниво клъстер, особено ако подчинения е бил повишен или е претърпял отказ поради срив. Това може да бъде катастрофа.
Лесна превенция за това е да се уверите, че read_only и super_read_only (само на> 5.6) са зададени в ON или 1. Може би сте разбрали как тези две променливи се различават и как се отразява, ако деактивирате или активирате тях. Когато super_read_only (от MySQL 5.7.8) е деактивиран, root потребителят може да предотврати всякакви промени в целта или репликата. Така че, когато и двете са деактивирани, това ще забрани на никого да прави промени в данните, с изключение на репликацията. Повечето мениджъри на отказ, като ClusterControl, задават този флаг автоматично, за да попречат на потребителите да пишат в използвания главен код по време на отказ. Някои от тях дори запазват това след отказ.
Активиране на GTID
При репликацията на MySQL стартирането на подчинения от правилната позиция в двоичните регистрационни файлове е от съществено значение. Получаването на тази позиция може да стане, когато правите резервно копие (xtrabackup и mysqldump поддържат това) или когато сте спрели да работите на възел, на който правите копие. Стартирането на репликация с командата CHANGE MASTER TO би изглеждало така:
mysql> CHANGE MASTER TO MASTER_HOST='x.x.x.x',
MASTER_USER='replication_user',
MASTER_PASSWORD='password',
MASTER_LOG_FILE='master-bin.00001',
MASTER_LOG_POS=4;Започването на репликация на грешното място може да има катастрофални последици:данните може да бъдат записани двойно или да не се актуализират. Това причинява отклонение на данните между главния и подчинения възел.
Освен това, прехвърлянето на главен към подчинен включва намиране на правилната позиция и смяна на главната на подходящия хост. MySQL не запазва двоичните регистрационни файлове и позиции от своя главен файл, а вместо това създава свои собствени двоични регистрационни файлове и позиции. Това може да се превърне в сериозен проблем за повторното подравняване на подчинен възел към новия главен. Точната позиция на главното устройство при отказ трябва да се намери на новия главен обект и след това всички подчинени устройства могат да бъдат пренасочени.
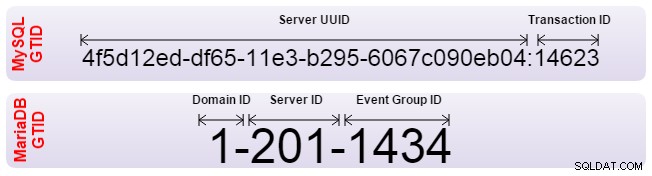
И Oracle MySQL, и MariaDB са внедрили глобалния идентификатор на транзакция (GTID) за реши този проблем. GTID позволяват автоматично подравняване на подчинените и сървърът сам определя коя е правилната позиция. И двете обаче са приложили GTID по различен начин и следователно са несъвместими. Ако трябва да настроите репликация от един към друг, репликацията трябва да бъде настроена с традиционно позициониране на двоичен журнал. Освен това вашият софтуер за преодоляване на срив трябва да бъде наясно, че не използва GTID.
Подчинен, безопасен при срив
Безопасен при срив означава, че дори ако подчинената MySQL/OS се срине, можете да възстановите подчинената и да продължите репликацията, без да възстановявате MySQL бази данни на подчинената. За да накарате подчинените устройства да работят с безопасност при срив, трябва да използвате само механизма за съхранение на InnoDB, а в 5.6 трябва да зададете relay_log_info_repository=TABLE и relay_log_recovery=1.
Заключение
Практиката наистина прави перфектни, но без подходящо обучение и познаване на тези жизненоважни техники, това може да бъде обезпокоително или да доведе до бедствие. Тези практики обикновено се спазват от експерти по MySQL и се адаптират от големите индустрии като част от ежедневната им рутинна работа при администриране на MySQL репликацията в сървърите на производствените бази данни.
Ако искате да прочетете повече за MySQL репликацията, вижте този урок за MySQL репликация за висока наличност.
За повече актуализации относно решенията за управление на бази данни и най-добрите практики за вашите бази данни с отворен код, последвайте ни в Twitter и LinkedIn и се абонирайте за нашия бюлетин.