Що се отнася до графичните планове за изпълнение, има само една икона за физическо сортиране в SQL Server:

Същата тази икона се използва за трите оператора за логично сортиране:Сортиране, Сортиране отгоре N и Отличен сорт:
Отивайки на ниво по-дълбоко, има четири различни реализации на Sort в машината за изпълнение (без да се брои партидно сортиране за оптимизирани циклични съединения, което не е пълно сортиране и така или иначе не се вижда в плановете). Ако използвате SQL Server 2014, броят на реализациите за сортиране на машината за изпълнение се увеличава до седем:
- CQScanSortNew
- CQScanTopSortNew
- CQScanIndexSortNew
- CQScanPartitionSortNew (само за SQL Server 2014)
- CQScanInMemSortNew
- In-Memory OLTP (Hekaton) компилирана процедура Top N Sort (само за SQL Server 2014)
- В паметта OLTP (Hekaton) компилирана процедура Общо сортиране (само за SQL Server 2014)
Тази статия разглежда тези реализации на сортиране и кога всяка от тях се използва в SQL Server. Част първа обхваща първите четири елемента в списъка.
1. CQScanSortNew
Това е най-общият клас за сортиране, използван, когато нито една от другите налични опции не е приложима. Общото сортиране използва предоставена памет за работно пространство, запазена точно преди да започне изпълнението на заявката. Тази субсидия е пропорционална на оценките за мощността и очакванията за средния размер на реда и не може да бъде увеличена след започване на изпълнението на заявката.
Изглежда, че текущата реализация използва разнообразие от вътрешно сортиране при сливане (може би бинарно сортиране при сливане), преминаване към външно сортиране чрез сливане (с множество проходи, ако е необходимо), ако запазената памет се окаже недостатъчна. Външното сортиране при сливане използва физически tempdb пространство за сортиране, което не се побира в паметта (известно като разлив на сортиране). Общото сортиране може също да бъде конфигурирано да прилага отличителност по време на операцията за сортиране.
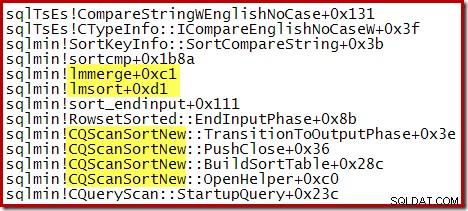
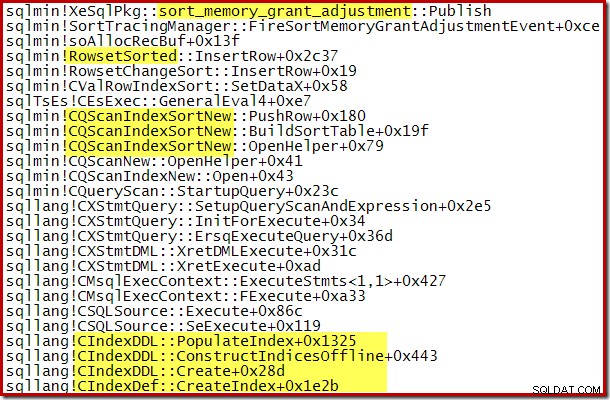
Следната частична трасировка на стека показва пример за CQScanSortNew низове за сортиране на клас с помощта на вътрешно сортиране при сливане:
В плановете за изпълнение, Сортирането предоставя информация за частта от общата предоставена памет на работното пространство на заявката, която е налична за Сортирането при четене на записи (фазата на входа), и фракцията, налична, когато сортираният изход се консумира от операторите на родителския план (фазата на изхода ).
Фракцията на предоставената памет е число между 0 и 1 (където 1 =100% от предоставената памет) и се вижда в SSMS чрез маркиране на Сортиране и гледане в прозореца Properties. Примерът по-долу е взет от заявка само с един оператор за сортиране, така че разполага с пълната памет на работното пространство на заявката, налична както по време на фазите на въвеждане, така и на изхода:
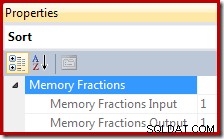
Фракциите на паметта отразяват факта, че по време на своята фаза на въвеждане, Sort трябва да сподели общата предоставена памет на заявката с едновременно изпълняващи се консумиращи памет оператори под него в плана за изпълнение. По същия начин, по време на изходната фаза, Sort трябва да споделя предоставената памет с едновременно изпълняващи се консумиращи памет оператори над нея в плана за изпълнение.
Процесорът на заявки е достатъчно интелигентен, за да знае, че някои оператори блокират (стоп и тръгване), ефективно маркирайки границите, където предоставената памет може да бъде рециклирана и използвана повторно. При паралелни планове частта за предоставяне на памет, достъпна за общо сортиране, се разделя равномерно между нишките и не може да бъде балансирана по време на изпълнение в случай на изкривяване (често срещана причина за разливане в планове за паралелно сортиране).
SQL Server 2012 и по-нови включват допълнителна информация за минималното предоставяне на памет за работно пространство, необходимо за инициализиране на оператори на план, консумиращи памет, и желаното предоставяне на памет („идеалното“ количество памет, което се оценява като необходимо за завършване на цялата операция в паметта). В плана за изпълнение след изпълнение („действително“) има и нова информация за всякакви закъснения при придобиване на предоставената памет, максималния обем действително използвана памет и как резервацията на паметта е била разпределена между NUMA възли.
Всички следните примери на AdventureWorks използват CQScanSortNew общ сорт:
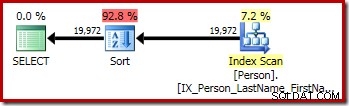
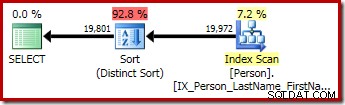
-- Обикновено сортиране (CQScanSortNew)SELECT P.FirstName, P.MiddleName, P.LastNameFROM Person.Person КАТО PORDER BY P.FirstName, P.MiddleName, P.LastName; -- Различно сортиране (също CQScanSortNew) ИЗБЕРЕТЕ ДИСТАНЦИОННО P.FirstName, P.MiddleName, P.LastNameFROM Person.Person КАТО PORDER BY P.FirstName, P.MiddleName, P.LastName; -- Същата заявка, изразена с помощта на GROUP BY-- План за изпълнение на същия различен сорт (CQScanSortNew)SELECT P.FirstName, P.MiddleName, P.LastNameFROM Person.Person КАТО PGROUP BY P.FirstName, P.MiddleName, P.Lastby.FistName , P.MiddleName, P.Lastname;
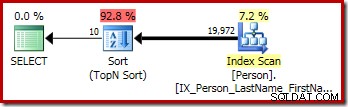
Първата заявка (неразличимо сортиране) произвежда следния план за изпълнение:
Втората и третата (еквивалентни) заявки произвеждат този план:
CQScanSortNew може да се използва както за логическо общо сортиране, така и за логическо различно сортиране.
2. CQScanTopSortNew
CQScanTopSortNew е подклас на CQScanSortNew използва се за прилагане на Top N Sort (както подсказва името). CQScanTopSortNew делегира голяма част от основната работа на CQScanSortNew , но променя подробното поведение по различни начини, в зависимост от стойността на N.
За N> 100, CQScanTopSortNew по същество е просто обикновен CQScanSortNew сортиране, което автоматично спира да произвежда сортирани редове след N реда. За N <=100, CQScanTopSortNew запазва само текущите най-добри резултати по време на операцията за сортиране и следи най-ниската ключова стойност, която в момента отговаря на изискванията.
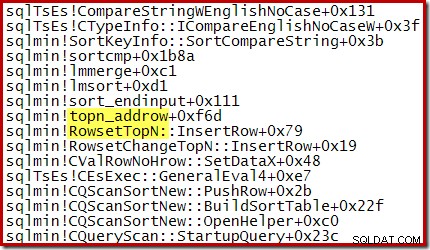
Например, по време на оптимизирано Топ N сортиране (където N <=100) стекът от повиквания включва RowsetTopN докато с общото сортиране в раздел 1 видяхме RowsetSorted :
За топ N сортиране, където N> 100, стекът от повиквания на същия етап на изпълнение е същият като общото сортиране, видяно по-рано:
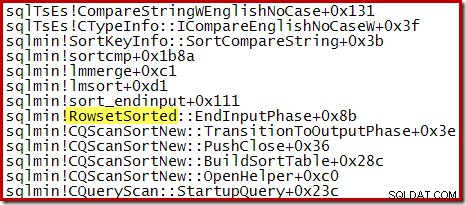
Забележете, че CQScanTopSortNew името на класа не се появява в нито една от тези трасирания на стека. Това се дължи просто на начина на работа на подкласовете. В други моменти по време на изпълнението на тези заявки, CQScanTopSortNew методите (например Open, GetRow и CreateTopNTable) се появяват изрично в стека от извиквания. Като пример, следното е взето на по-късен етап от изпълнението на заявката и показва CQScanTopSortNew име на клас:
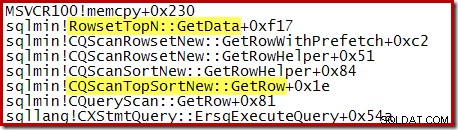
Топ N сортиране и оптимизатор на заявки
Оптимизаторът на заявки не знае нищо за Top N Sort, който е само оператор на машина за изпълнение. Когато оптимизаторът създаде изходно дърво с физически топ оператор непосредствено над (неразличимо) физическо сортиране, пренаписването след оптимизация може да свие двете физически операции в един оператор Top N Sort. Дори в случая N> 100, това представлява спестяване при преминаване на редове итеративно между изход за сортиране и вход отгоре.
Следната заявка използва няколко недокументирани флага за проследяване, за да покаже изхода на оптимизатора и пренаписването след оптимизация в действие:
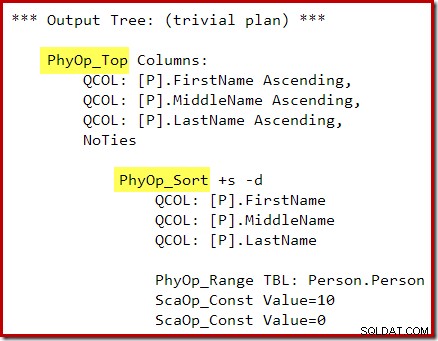
ИЗБЕРЕТЕ TOP (10) P.FirstName, P.MiddleName, P.LastNameFROM Person.Person КАТО PORDER BY P.FirstName, P.MiddleName, P.LastNameOPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERY52);>Изходното дърво на оптимизатора показва отделни физически оператори Top и Sort:
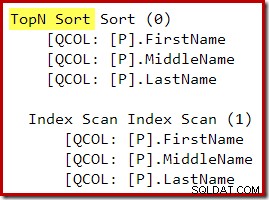
След пренаписването след оптимизация, Top и Sort са свити в един Top N Sort:
Графичният план за изпълнение на T-SQL заявката по-горе показва единичния оператор Top N Sort:
Разрушаване на пренаписването на най-добрия N сорт
Пренаписването на Top N Sort след оптимизация може да свие само съседно Top N Sort в Top N Sort. Добавянето на DISTINCT (или еквивалентната клауза GROUP BY) към заявката по-горе ще предотврати пренаписването на Top N Sort:
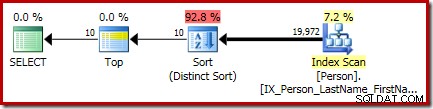
ИЗБЕРЕТЕ DISTINCT TOP (10) P.FirstName, P.MiddleName, P.LastNameFROM Person.Person КАТО PORDER BY P.FirstName, P.MiddleName, P.LastName;Окончателният план за изпълнение на тази заявка включва отделни оператори Top и Sort (Distinct Sort):
Сортирането там е общият CQScanSortNew клас, работещ в различен режим, както се вижда в раздел 1 по-рано.
Втори начин за предотвратяване на пренаписването към Top N Sort е да се въведе един или повече допълнителни оператори между Top и Sort. Например:
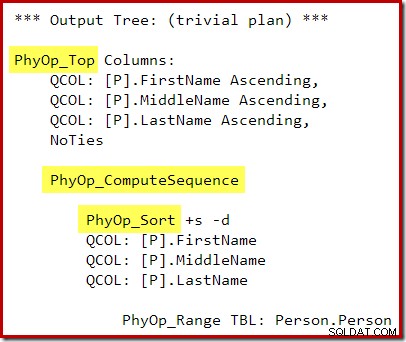
ИЗБЕРЕТЕ ТОП (10) P.FirstName, P.MiddleName, P.LastName, rn =RANK() НАД (ПОРЪЧКА ПО P.FirstName)FROM Person.Person AS PORDER BY P.FirstName, P.MiddleName, P. Фамилия;Изходът на оптимизатора на заявки сега има операция между Top и Sort, така че сортиране Top N не се генерира по време на фазата на пренаписване след оптимизация:
Планът за изпълнение е:
Изчислителната последователност (реализирана като два сегмента и проект за последователност) между Top и Sort предотвратява срива на Top и Sort до един оператор Top N Sort. От този план, разбира се, пак ще се получават правилни резултати, но изпълнението може да бъде малко по-малко ефективно, отколкото би могло да бъде с комбинирания оператор Top N Sort.
3. CQScanIndexSortNew
CQScanIndexSortNew се използва само за сортиране в планове за изграждане на DDL индекс. Той използва повторно някои от общите средства за сортиране, които вече сме виждали, но добавя специфични оптимизации за вмъкване на индекс. Това е и единственият клас за сортиране, който може динамично да изисква повече памет след като изпълнението е започнало.
Оценката на кардиналността често е точна за план за изграждане на индекс, тъй като общият брой редове в таблицата обикновено е известно количество. Това не означава, че предоставянето на памет за сортиране на планове за изграждане на индекс винаги ще бъде точни; просто го прави малко по-лесен за демонстрация. Така че, следният пример използва недокументирано, но доста добре известно разширение на командата UPDATE STATISTICS, за да заблуди оптимизатора да мисли, че таблицата, върху която изграждаме индекс, има само един ред:
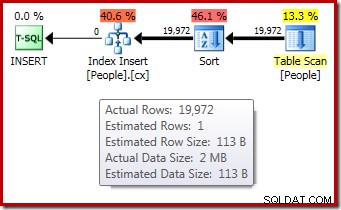
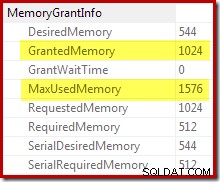
-- Тестова таблицаCREATE TABLE dbo.People( FirstName dbo.Name NOT NULL, LastName dbo.Name NOT NULL);GO-- Копиране на редове от Person.PersonINSERT dbo.People WITH (TABLOCKX)( First Name, LastName)SELECT P .FirstName, P.LastNameFROM Person.Person AS P;GO-- Представете си, че таблицата има само 1 ред и 1 страница АКТУАЛИЗИРАНЕ НА СТАТИСТИКА dbo. Хора С РЕДОВЕ РЕДОВЕ =1, PAGECOUNT =1;GO-- План за изграждане на индекс СЪЗДАВАНЕ НА КЛУСТРИРАН ИНДЕКС cxON dbo.Peo (Фамилия, Име);GO-- Подредете DROP TABLE dbo.People;Планът за изпълнение след изпълнение („действително“) за изграждането на индекса не показва предупреждение за разлято сортиране (когато се изпълнява на SQL Server 2012 или по-нова версия), въпреки оценката за 1 ред и 19 972 реда действително сортирани:
Потвърждението, че първоначалното предоставяне на памет е било динамично разширено, идва от разглеждането на свойствата на коренния итератор. Първоначално на заявката бяха предоставени 1024KB памет, но в крайна сметка изразходва 1576KB:
Динамичното увеличение на предоставената памет може също да бъде проследено с помощта на разширение на събитието на канала за отстраняване на грешки sort_memory_grant_adjustment. Това събитие се генерира всеки път, когато разпределението на паметта се увеличава динамично. Ако това събитие се наблюдава, можем да заснемем проследяване на стека, когато е публикувано, или чрез разширени събития (с някаква неудобна конфигурация и флаг за проследяване) или от прикачен дебъгер, както е по-долу:
Динамичното разширяване на предоставянето на памет може също да помогне при планове за изграждане на паралелни индекси, където разпределението на редовете между нишките е неравномерно. Количеството памет, което може да се консумира по този начин, обаче не е неограничено. SQL Server проверява всеки път, когато е необходимо разширение, за да види дали заявката е разумна предвид наличните ресурси към този момент.
Известна представа за този процес може да се получи чрез активиране на недокументиран флаг за проследяване 1504, заедно с 3604 (за извеждане на съобщение към конзолата) или 3605 (извеждане в регистъра за грешки на SQL Server). Ако планът за изграждане на индекса е паралелен, само 3605 е ефективен, тъй като паралелните работници не могат да изпращат съобщения за проследяване между нишките към конзолата.
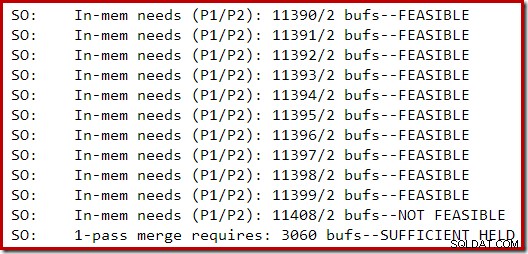
Следната секция на изхода за проследяване беше уловена при изграждане на умерено голям индекс на екземпляр на SQL Server 2014 с ограничена памет:
Разширяването на паметта за сортирането продължи, докато заявката беше счетена за неосъществима, като в този момент беше определено, че вече има достатъчно памет за завършване на разливането на сортиране с едно преминаване.
4. CQScanPartitionSortNew
Това име на клас може да подсказва, че този тип сортиране се използва за данни от разделени таблици или при изграждане на индекси върху разделени таблици, но нито едно от тях всъщност не е така. Сортирането на разделени данни използва CQScanSortNew или CQScanTopSortNew като нормално; сортирането на редове за вмъкване в разделен индекс обикновено използва CQScanIndexSortNew както се вижда в раздел 3.
CQScanPartitionSortNew class class присъства само в SQL Server 2014. Използва се само при сортиране на редове по идентификатор на дял, преди вмъкване в разделен клъстериран индекс на columnstore . Имайте предвид, че се използва само за разделен клъстериран columnstore; обикновените (неразделени) клъстерни планове за вмъкване на columnstore не се възползват от сортиране.
Вмъкванията в разделен клъстериран индекс на columnstore не винаги ще включват сортиране. Това е базирано на разходите решение, което зависи от очаквания брой редове, които трябва да бъдат вмъкнати. Ако оптимизаторът прецени, че си струва да сортира вмъкванията по дял, за да оптимизира I/O, операторът за вмъкване на columnstore ще има DMLRequestSort свойството, зададено на true, и CQScanPartitionSortNew сортирането може да се появи в плана за изпълнение.
Демонстрацията в този раздел използва постоянна таблица с последователни номера. Ако нямате един от тях, следният скрипт може да се използва за създаване на такъв:
-- Генератор на редове на Itzik Ben-Gan С L0 AS (ИЗБЕРЕТЕ 1 КАТО c UNION ALL SELECT 1), L1 AS (ИЗБЕРЕТЕ 1 КАТО c ОТ L0 КАТО КРЪСТО СЪЕДИНЕТЕ L0 AS B), L2 AS (ИЗБЕРЕТЕ 1 КАТО c ОТ L1 КАТО КРЪСТО СЪЕДИНЕНИЕ L1 КАТО B), L3 AS (ИЗБЕРЕТЕ 1 КАТО c ОТ L2 КАТО КРЪСТО СЪЕДИНЕНИЕ L2 КАТО B), L4 AS (ИЗБЕРЕТЕ 1 КАТО c ОТ L3 КАТО КРЪСТО СЪЕДИНЕНИЕ L3 КАТО B), L5 AS (ИЗБЕРЕТЕ 1 AS c ОТ L4 КАТО КРЪСТО ПРИСЪЕДИНЯВАНЕ L4 AS B), Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM L5)SELECT -- Тип на целевата колона цяло число NOT NULL ISNULL(CONVERT(integer, N.n), 0) КАТО nINTO dbo.NumbersFROM Nums AS NWHERE N.n >=1AND N.n <=1000000OPTION (MAXDOP 1);GOALTER TABLE dbo.NumbersADD ОГРАНИЧЕНИЕ PK_Numbers_nPRIMARY KEY nWILUSTE MAX (PRIMARY DBnWINF) =100);Самата демонстрация включва създаване на разделена клъстерирана индексирана таблица на columnstore и вмъкване на достатъчно редове (от таблицата Numbers по-горе), за да убеди оптимизатора да използва сортиране на дялове с предварително вмъкване:
СЪЗДАВАНЕ НА ФУНКЦИЯ НА PARTITION PF (цяло число) КАТО ДИАПАЗОН ПРАВО ЗА СТОЙНОСТИ (1000, 2000, 3000);GOCREATE PARTITION SCHEME PSAS PARTITION PFALL TO ([PRIMARY]);GO-- A partitioned heapboCREATE TABLEl ind. NULL, col2 integer NOT NULL DEFAULT ABS(КОНТРОЛНА СУМА(NEWID())), col3 integer NOT NULL DEFAULT ABS(CHECKSUM(NEWID())))ON PS (col1);GO-- Преобразуване на купчина в разделена клъстерирана columnstore СЪЗДАВАНЕ НА CLUSTERED COLUMNS ccsiON dbo.PartitionedON PS (col1);GO-- Добавяне на редове към разделената клъстерирана таблица columnstore INSERT dbo.Partitioned (col1)ИЗБЕРЕТЕ N.nFROM dbo.Числа КАТО НИГДЕ N.n МЕЖДУ 1 И 4000;Планът за изпълнение на вмъкването показва сортирането, използвано, за да се гарантира, че редовете пристигат в клъстерирания итератор за вмъкване на columnstore в реда на идентификатор на дял:
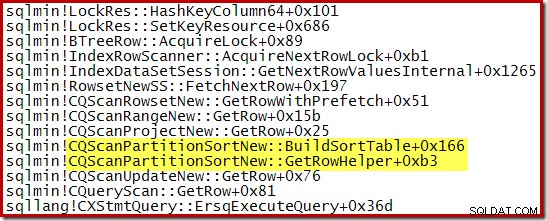
Стек от повиквания, заловен, докато CQScanPartitionSortNew сортирането е в ход е показано по-долу:
Има още нещо интересно в този клас. Сортирането обикновено консумира целия си вход в извикването на метода Open. След сортиране те връщат контрола на своя родителски оператор. По-късно сортирането започва да произвежда сортирани изходни редове един по един по обичайния начин чрез извиквания GetRow. CQScanPartitionSortNew е различно, както можете да видите в стека от повиквания по-горе:Той не консумира своя вход по време на своя Open метод – той изчаква, докато GetRow бъде извикан от неговия родител за първи път.
Не всяко сортиране на идентификатор на дял, което се появява в план за изпълнение, вмъкващ редове в разделен клъстериран индекс на хранилището на колони, ще бъде CQScanPartitionSortNew вид. Ако сортирането се появи непосредствено вдясно от оператора за вмъкване на индекс на columnstore, шансовете са много добри, че е CQScanPartitionSortNew сортиране.
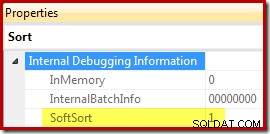
И накрая, CQScanPartitionSortNew е един от само двата класа за сортиране, който задава свойството Soft Sort, което се показва, когато свойствата на плана за изпълнение на оператора за сортиране се генерират с активиран недокументиран флаг за проследяване 8666:
Значението на „мек сорт“ в този контекст е неясно. То се проследява като свойство в рамката на оптимизатора на заявки и изглежда вероятно да е свързано с оптимизирани вмъквания на разделени данни, но определянето на какво точно означава това изисква по-нататъшно проучване. Междувременно това свойство може да се използва, за да се заключи, че сортирането е реализирано с CQScanPartitionSortNew без прикачване на дебъгер. Значението на флага на свойството InMemory, показан по-горе, ще бъде разгледано в част 2. То не посочете дали е извършено редовно сортиране в паметта или не.
Резюме на част първа


- CQScanSortNew е общият клас за сортиране, използван, когато не е приложима друга опция. Изглежда, че използва разнообразие от вътрешно сортиране при сливане в паметта, преминавайки към външно сортиране при сливане с помощта на tempdb ако предоставеното работно пространство на паметта се окаже недостатъчно. Този клас може да се използва за Общо сортиране и Различно сортиране.
- CQScanTopSortNew прилага Top N Sort. Когато N <=100, се извършва вътрешно сортиране в паметта и никога не се прелива към tempdb . Само текущите топ n елемента се запазват в паметта по време на сортирането. За N> 100 CQScanTopSortNew е еквивалентен на CQScanSortNew сортиране, което автоматично спира след извеждане на N реда. Сортиране N> 100 може да се прехвърли към tempdb ако е необходимо.
- Най-добрият N сорт, който се вижда в плановете за изпълнение, е пренаписване след оптимизация след заявка. Ако оптимизаторът на заявки създаде изходно дърво със съседно горно и неразличимо сортиране, това пренаписване може да свие двата физически оператора в един оператор за сортиране от най-висок клас.
- CQScanIndexSortNew се използва само в DDL планове за изграждане на индекси. Това е единственият стандартен клас за сортиране, който може динамично да придобие повече памет по време на изпълнение. Сортовете за изграждане на индекси все още могат да се разлеят на диск при някои обстоятелства, включително когато SQL Server реши, че заявеното увеличение на паметта не е съвместимо с текущото работно натоварване.
- CQScanPartitionSortNew присъства само в SQL Server 2014 и се използва само за оптимизиране на вмъквания към разделен клъстериран индекс на columnstore. Предоставя „меко сортиране“.
Втората част на тази статия ще разгледа CQScanInMemSortNew , и двата вградени в паметта OLTP компилирани нативно сортирани съхранени процедури.