Кратко резюме
- Ефективността на метода на подзаявките зависи от разпределението на данните.
- Ефективността на условното агрегиране не зависи от разпределението на данните.
Методът на подзаявките може да бъде по-бърз или по-бавен от условното агрегиране, зависи от разпределението на данните.
Естествено, ако таблицата има подходящ индекс, тогава подзаявките вероятно ще се възползват от него, тъй като индексът ще позволи да се сканира само съответната част от таблицата вместо пълното сканиране. Наличието на подходящ индекс е малко вероятно да е от полза за метода на условно агрегиране, тъй като така или иначе ще сканира пълния индекс. Единствената полза би била, ако индексът е по-тесен от таблицата и машината ще трябва да чете по-малко страници в паметта.
Като знаете това, можете да решите кой метод да изберете.
Първи тест
Направих по-голяма тестова таблица с 5M реда. В таблицата нямаше индекси. Измерих IO и CPU статистиката с помощта на SQL Sentry Plan Explorer. Използвах SQL Server 2014 SP1-CU7 (12.0.4459.0) Express 64-битов за тези тестове.
Всъщност оригиналните ви заявки се държаха, както описахте, т.е. подзаявките бяха по-бързи, въпреки че показанията бяха 3 пъти по-високи.
След няколко опита с таблица без индекс пренаписах вашия условен агрегат и добавих променливи, за да задържа стойността на DATEADD изрази.
Като цяло времето стана значително по-бързо.
След това замених SUM с COUNT и отново стана малко по-бързо.
В крайна сметка условното агрегиране стана почти толкова бързо, колкото и подзаявките.
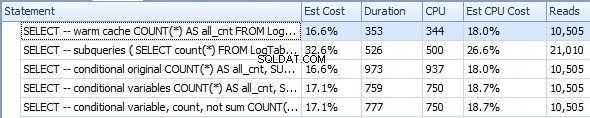
Загрейте кеша (CPU=375)
SELECT -- warm cache
COUNT(*) AS all_cnt
FROM LogTable
OPTION (RECOMPILE);
Подзаявки (CPU=1031)
SELECT -- subqueries
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-1,GETDATE())
) last_year_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-10,GETDATE())
) last_ten_year_cnt
OPTION (RECOMPILE);
Оригинално условно агрегиране (CPU=1641)
SELECT -- conditional original
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-1,GETDATE())
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-10,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Условно агрегиране с променливи (CPU=1078)
DECLARE @VarYear1 datetime = DATEADD(year,-1,GETDATE());
DECLARE @VarYear10 datetime = DATEADD(year,-10,GETDATE());
SELECT -- conditional variables
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > @VarYear1
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > @VarYear10
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Условно агрегиране с променливи и COUNT вместо SUM (CPU=1062)
SELECT -- conditional variable, count, not sum
COUNT(*) AS all_cnt,
COUNT(CASE WHEN datesent > @VarYear1
THEN 1 ELSE NULL END) AS last_year_cnt,
COUNT(CASE WHEN datesent > @VarYear10
THEN 1 ELSE NULL END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);

Въз основа на тези резултати предполагам, че CASE извика DATEADD за всеки ред, докато WHERE беше достатъчно умен, за да го изчисли веднъж. Плюс COUNT е малко по-ефективен от SUM .
В крайна сметка условното агрегиране е само малко по-бавно от подзаявките (1062 срещу 1031), може би защото WHERE е малко по-ефективен от CASE само по себе си и освен това WHERE филтрира доста редове, така че COUNT трябва да обработи по-малко редове.
На практика бих използвал условно агрегиране, защото смятам, че този брой четения е по-важен. Ако вашата маса е малка, за да се побере и да остане в буферния пул, тогава всяка заявка ще бъде бърза за крайния потребител. Но ако таблицата е по-голяма от наличната памет, тогава очаквам, че четенето от диск ще забави значително подзаявките.
Втори тест
От друга страна, филтрирането на редовете възможно най-рано също е важно.
Ето една малка вариация на теста, която го демонстрира. Тук зададох прага на GETDATE() + 100 години, за да се уверя, че няма редове да отговарят на критериите за филтриране.
Загрейте кеша (CPU=344)
SELECT -- warm cache
COUNT(*) AS all_cnt
FROM LogTable
OPTION (RECOMPILE);
Подзаявки (CPU=500)
SELECT -- subqueries
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,100,GETDATE())
) last_year_cnt
OPTION (RECOMPILE);
Оригинално условно агрегиране (CPU=937)
SELECT -- conditional original
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,100,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Условно агрегиране с променливи (CPU=750)
DECLARE @VarYear100 datetime = DATEADD(year,100,GETDATE());
SELECT -- conditional variables
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > @VarYear100
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Условно агрегиране с променливи и COUNT вместо SUM (CPU=750)
SELECT -- conditional variable, count, not sum
COUNT(*) AS all_cnt,
COUNT(CASE WHEN datesent > @VarYear100
THEN 1 ELSE NULL END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
По-долу е даден план с подзаявки. Можете да видите, че 0 реда влязоха в Stream Aggregate във втората подзаявка, като всички те бяха филтрирани на стъпката за сканиране на таблицата.
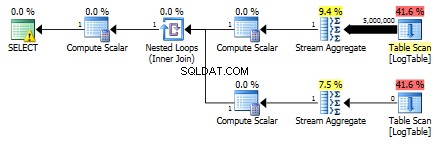
В резултат на това подзаявките отново са по-бързи.
Трети тест
Тук промених критериите за филтриране на предишния тест:всички > бяха заменени с < . В резултат на това условният COUNT преброи всички редове вместо нито един. Изненада, изненада! Заявката за условно агрегиране отне същите 750 ms, докато подзаявките станаха 813 вместо 500.

Ето плана за подзаявки:
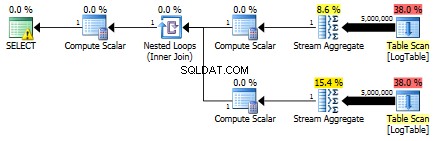
Бихте ли ми дали пример, където условното агрегиране по-специално превъзхожда решението на подзаявката?
Ето го. Производителността на метода на подзаявките зависи от разпределението на данните. Производителността на условното агрегиране не зависи от разпределението на данните.
Методът на подзаявките може да бъде по-бърз или по-бавен от условното агрегиране, зависи от разпределението на данните.
Като знаете това, можете да решите кой метод да изберете.
Подробности за бонуса
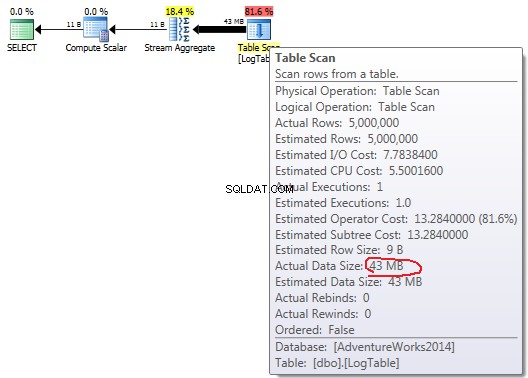
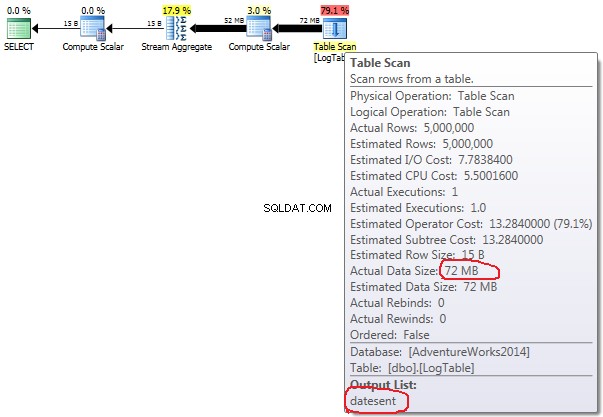
Ако задържите курсора на мишката над Table Scan оператор можете да видите Actual Data Size в различни варианти.
- Прост
COUNT(*):
- Условно агрегиране:
- Подзаявка в тест 2:
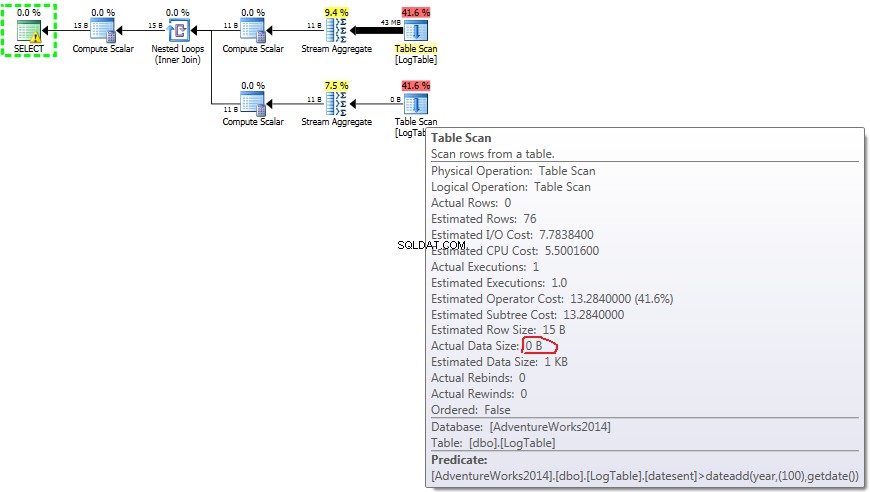
- Подзаявка в тест 3:
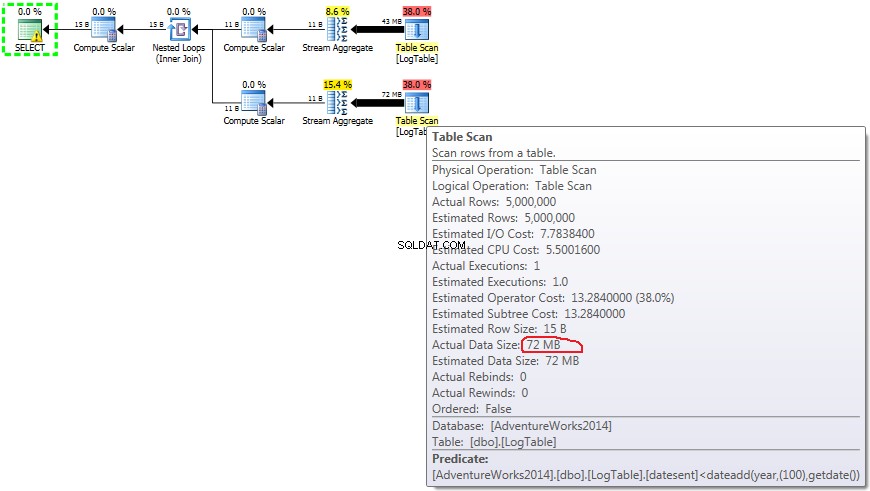
Сега става ясно, че разликата в производителността вероятно е причинена от разликата в количеството данни, които преминават през плана.
В случай на обикновен COUNT(*) няма Output list (не са необходими стойности на колони) и размерът на данните е най-малкият (43MB).
В случай на условно агрегиране тази сума не се променя между тестове 2 и 3, тя винаги е 72MB. Output list има една колона datesent .
В случай на подзаявки тази сумаве промяна в зависимост от разпределението на данните.