Съхранение на ~3.5TB данни и вмъкване на около 1K/sec 24x7, както и заявка с неуточнена скорост, е възможно със SQL Server, но има още въпроси:
- какво изискване за наличност имате за това? 99,999% време на работа или 95% са достатъчни?
- какво изискване за надеждност имате? Липсата на вложка струва ли ви 1 милион долара?
- какво изискване за възстановяване имате? Ако загубите един ден данни, има ли значение?
- какво изискване за последователност имате? Трябва ли да се гарантира, че записът ще бъде видим при следващото четене?
Ако имате нужда от всички тези изисквания, които подчертах, натоварването, което предлагате, ще струва милиони хардуер и лицензиране на релационна система, всяка система, без значение какви трикове опитате (шардиране, разделяне и т.н.). Системата nosql, по самата им дефиниция, не отговаря на всички тези изисквания.
Така че очевидно вече сте облекчили някои от тези изисквания. Има хубаво визуално ръководство, сравняващо предложенията на nosql въз основа на парадигмата „изберете 2 от 3“ във Визуално ръководство за NoSQL системи:
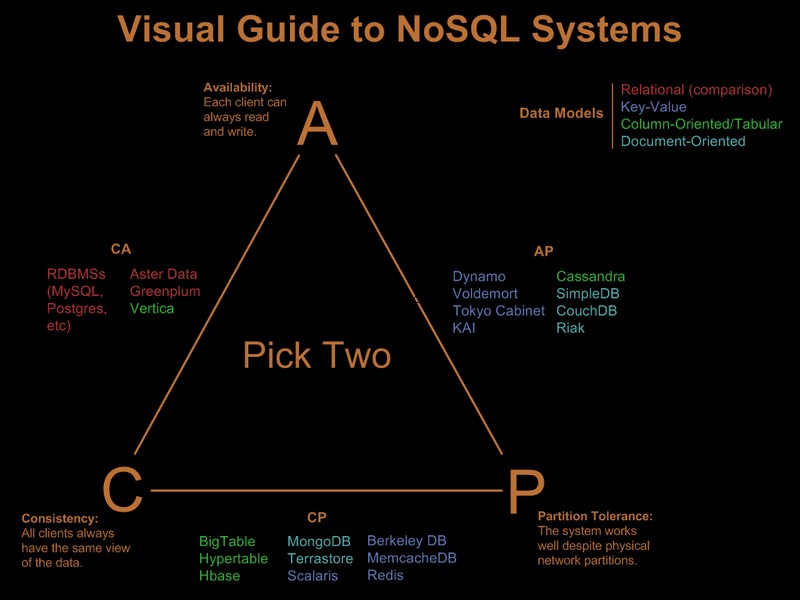
След актуализация на OP коментар
С SQL Server това би било директно изпълнение:
- единична клъстерирана таблица (GUID, време) ключ. Да, ще се фрагментира, но фрагментацията засяга четенето напред, а четенето напред са необходими само за сканиране със значителен обхват. Тъй като заявите само за конкретен GUID и период от време, фрагментацията няма да има голямо значение. Да, това е широк ключ, така че страниците без листа ще имат лоша плътност на ключовете. Да, това ще доведе до лош фактор на запълване. И да, може да възникне разделяне на страници. Въпреки тези проблеми, предвид изискванията, все още е най-добрият клъстерен ключов избор.
- разделете таблицата по време, за да можете да приложите ефективно изтриване на записи с изтекъл срок чрез автоматичен плъзгащ се прозорец. Допълнете това с възстановяване на онлайн индексния дял от последния месец, за да премахнете лошия фактор на запълване и фрагментацията, въведени от клъстерирането на GUID.
- активирайте компресирането на страници. Тъй като клъстерираните ключови групи са първо по GUID, всички записи на GUID ще бъдат един до друг, което дава добър шанс на компресирането на страници за разгръщане на компресия на речника.
- Ще ви трябва бърз път за IO за регистрационния файл. Интересувате се от висока пропускателна способност, а не от ниска латентност, за да може регистрационният файл да бъде в крак с 1K вмъквания/сек, така че премахването е задължително.
Разделянето на дялове и компресирането на страници изискват SQL Server Enterprise Edition, те няма да работят в Standard Edition и и двете са доста важни, за да отговорят на изискванията.
Като странична забележка, ако записите идват от ферма за уеб сървъри от предния край, бих поставил Express на всеки уеб сървър и вместо INSERT на задния край, бих SEND информацията към задния край, като се използва локална връзка/транзакция на Express, разположен съвместно с уеб сървъра. Това дава много по-добра история за наличност на решението.
Ето как бих го направил в SQL Server. Добрата новина е, че проблемите, с които ще се сблъскате, са добре разбрани и решенията са известни. това не означава непременно, че това е по-добро от това, което бихте могли да постигнете с Cassandra, BigTable или Dynamo. Ще позволя на някой, който е по-компетентен в нещата без sql, да аргументира техния случай.
Имайте предвид, че никога не съм споменавал модела на програмиране, поддръжката на .Net и други подобни. Честно казано мисля, че те са без значение при големи разгръщания. Те правят огромна разлика в процеса на разработка, но след като бъдат внедрени, няма значение колко бърза е била разработката, ако режийните разходи на ORM убиват производителността :)