Здравей,
Използването на Index в базата данни на SQL Server се случва в среди, които изискват най-голяма производителност, скорост и спестяване на памет.
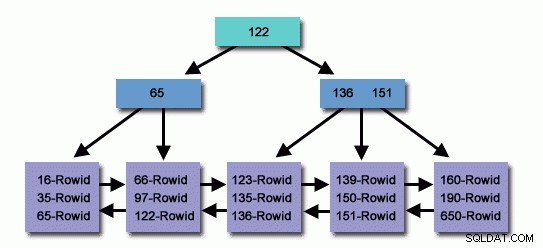
В таблица с милиони или милиарди записи можем да използваме индекс , за да четем по-малко записи и да търсим по-малко, за да намерим свързан запис.
Прецизно създаден индекс, милиони записи в базата данни, които сме търсили за много кратко време, за да донесем записа за удобство на обаждащия се, като в същото време по-малко четем записа чрез достигане на целевия запис, ние използваме ресурсите на операционната система ефективно.
Трябва да създадете индекс за предимно заявки само за четене в таблица. Ако операциите Delete,update са нещо повече от заявки само за четене, не трябва да създавате индекс на тази таблица.
Можете да разгледате препоръката за липсващ индекс на SQL Server със следния скрипт. Можете да създадете липсващ индекс, но трябва да наблюдавате тези индекси. Ако не са полезни, трябва да ги пуснете.
SELECT MID.[statement] AS ObjectName
,MID.equality_columns AS EqualityColumns
,MID.inequality_columns AS InequalityColms
,MID.included_columns AS IncludedColumns
,MIGS.last_user_seek AS LastUserSeek
,MIGS.avg_total_user_cost
* MIGS.avg_user_impact
* (MIGS.user_seeks + MIGS.user_scans) AS Impact
,N'CREATE NONCLUSTERED INDEX <TYPE_Index_Name> ' +
N'ON ' + MID.[statement] +
N' (' + MID.equality_columns
+ ISNULL(', ' + MID.inequality_columns, N'') +
N') ' + ISNULL(N'INCLUDE (' + MID.included_columns + N');', ';')
AS CreateStatement
FROM sys.dm_db_missing_index_group_stats AS MIGS
INNER JOIN sys.dm_db_missing_index_groups AS MIG
ON MIGS.group_handle = MIG.index_group_handle
INNER JOIN sys.dm_db_missing_index_details AS MID
ON MIG.index_handle = MID.index_handle
WHERE database_id = DB_ID()
AND MIGS.last_user_seek >= DATEDIFF(month, GetDate(), -1)
ORDER BY Impact DESC;