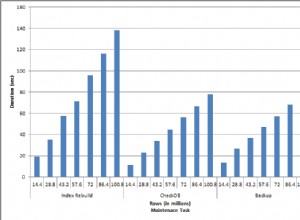
Този отговор се фокусира главно върху операциите „избиране“ срещу актуализиране/създаване/изтриване. Мисля, че е по-рядко да се актуализират повече от един или няколко записа наведнъж и затова също мисля, че „select“ е мястото, където обикновено се появяват тесните места. Това каза, че трябва да знаете своето приложение (профил). Най-доброто място за фокусиране на времето за оптимизация е почти винаги на ниво база данни в самите заявки, а не на клиентския код. Клиентският код е само водопровод:той не е основната сила на вашето приложение. Въпреки това, тъй като водопроводът има тенденция да се използва повторно в много различни приложения, аз симпатизирам на желанието да го приближа възможно най-близо до оптималното и затова имам какво да кажа как да изградя този код.
Имам общ метод за избор на заявки/процедури в моя слой данни, който изглежда нещо подобно:
private static IEnumerable<IDataRecord> Retrieve(string sql, Action<SqlParameterCollection> addParameters)
{
//ConnectionString is a private static property in the data layer
// You can implement it to read from a config file or elsewhere
using (var cn = new SqlConnection(ConnectionString))
using (var cmd = new SqlCommand(sql, cn))
{
addParameters(cmd.Parameters);
cn.Open();
using (var rdr = cmd.ExecuteReader())
{
while (rdr.Read())
yield return rdr;
rdr.Close();
}
}
}
И това ми позволява да пиша публични методи на слоя данни, които използват анонимни методи за добавяне на параметрите. Показаният код работи с .Net 2.0+, но може да бъде написан дори по-кратко с .Net 3.5:
public IEnumerable<IDataRecord> GetFooChildrenByParentID(int ParentID)
{
//I could easily use a stored procedure name instead of a full sql query
return Retrieve(
@"SELECT c.*
FROM [ParentTable] p
INNER JOIN [ChildTable] c ON c.ParentID = f.ID
WHERE f.ID= @ParentID", delegate(SqlParameterCollection p)
{
p.Add("@ParentID", SqlDbType.Int).Value = ParentID;
}
);
}
Ще спра дотук, за да мога да ви насоча отново към кода точно по-горе, който използва анонимния метод за създаване на параметри.
Това е много изчистен код, тъй като поставя дефиницията на заявката и създаването на параметър на едно и също място, като същевременно ви позволява да абстрахирате стандартната връзка с базата данни/код за повикване до някъде, по-използваема отново. Не мисля, че тази техника е обхваната от някоя от точките във вашия въпрос, а също така е доста бърза. Мисля, че това покрива същността на въпроса ви.
Искам обаче да продължа, за да обясня как всичко това се вписва заедно. Останалото е доста просто, но също така е лесно да хвърлите това в списък или подобно и да объркате нещата, в крайна сметка да навреди на производителността. Така че продължавайки напред, бизнес слоят използва фабрика, за да преведе резултатите от заявката в обекти (c# 3.0 или по-нова версия):
public class Foo
{
//various normal properties and methods go here
public static Foo FooFactory(IDataRecord record)
{
return new Foo
{
Property1 = record[0],
Property2 = record[1]
//...
};
}
}
Вместо те да живеят в техния клас, можете също да ги групирате заедно в статичен клас, специално предназначен да задържи фабричните методи.
Трябва да направя една промяна в оригиналния метод за извличане. Този метод "добива" един и същ обект отново и отново и това не винаги работи толкова добре. Това, което искаме да направим по различен начин, за да работи, е да принудим копие на обекта, представен от текущия запис, така че когато четецът мутира за следващия запис, ние работим с чисти данни. Изчаках след показването на фабричния метод, за да можем да го използваме в крайния код. Новият метод за извличане изглежда така:
private static IEnumerable<T> Retrieve(Func<IDataRecord, T> factory,
string sql, Action<SqlParameterCollection> addParameters)
{
//ConnectionString is a private static property in the data layer
// You can implement it to read from a config file or elsewhere
using (var cn = new SqlConnection(ConnectionString))
using (var cmd = new SqlCommand(sql, cn))
{
addParameters(cmd.Parameters);
cn.Open();
using (var rdr = cmd.ExecuteReader())
{
while (rdr.Read())
yield return factory(rdr);
rdr.Close();
}
}
}
И сега бихме нарекли този нов метод Retrieve() така:
public IEnumerable<Foo> GetFooChildrenByParentID(int ParentID)
{
//I could easily use a stored procedure name instead of a full sql query
return Retrieve(Foo.FooFactory,
@"SELECT c.*
FROM [ParentTable] p
INNER JOIN [ChildTable] c ON c.ParentID = f.ID
WHERE f.ID= @ParentID", delegate(SqlParameterCollection p)
{
p.Add("@ParentID", SqlDbType.Int).Value = ParentID;
}
);
}
Очевидно този последен метод може да бъде разширен, за да включи всяка необходима допълнителна бизнес логика. Освен това се оказва, че този код е изключително бърз, защото се възползва от функциите за мързелива оценка на IEnumerable. Недостатъкът е, че има тенденция да създава много краткотрайни обекти и това може да навреди на транзакционната ефективност, за която сте попитали. За да заобиколя това, понякога нарушавам доброто n-ниво и предавам обектите IDataRecord директно към нивото на презентация и избягвам ненужното създаване на обекти за записи, които просто са обвързани с контрола на мрежата веднага.
Кодът за актуализиране/създаване е подобен, с тази разлика, че обикновено променяте само един запис в даден момент, а не много.
Или мога да ви спестя четенето на тази дълга публикация и просто да ви кажа да използвате Entity Framework;)