Това е добре, но понякога може да бъде лошо.
Снифирането на параметри е свързано с оптимизатора на заявки, използващ стойността на предоставения параметър, за да разбере възможно най-добрия план за заявка. Един от многото възможности за избор и този, който е доста лесен за разбиране, е дали цялата таблица трябва да бъде сканирана, за да се получат стойностите, или дали ще бъде по-бързо с помощта на търсене на индекс. Ако стойността във вашия параметър е силно селективна, оптимизаторът вероятно ще изгради план за заявка с търсения и ако не е, заявката ще сканира вашата таблица.
След това планът на заявката се кешира и се използва повторно за последователни заявки, които имат различни стойности. Лошата част от подслушването на параметри е, когато кешираният план не е най-добрият избор за една от тези стойности.
Примерни данни:
create table T
(
ID int identity primary key,
Value int not null,
AnotherValue int null
);
create index IX_T_Value on T(Value);
insert into T(Value) values(1);
insert into T(Value)
select 2
from sys.all_objects;
T е таблица с няколко хиляди реда с неклъстериран индекс на Value. Има един ред, където стойността е 1 а останалото има стойност 2 .
Примерна заявка:
select *
from T
where Value = @Value;
Изборите, които оптимизаторът на заявки има тук, е или да извърши клъстерирано индексно сканиране и да провери клаузата where срещу всеки ред или да използва търсене на индекс, за да намери до редове, които съвпадат, и след това да направи Key Lookup, за да получи стойностите от колоните, поискани в списъка с колони.
Когато подушената стойност е 1 планът на заявката ще изглежда така:

И когато подушената стойност е 2 ще изглежда така:
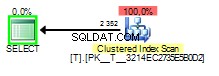
Лошата част от подслушването на параметри в този случай се случва, когато планът на заявката е изграден с подслушване на 1 но се изпълнява по-късно със стойността на 2 .
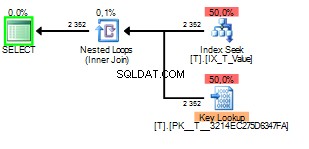
Можете да видите, че Key Lookup е изпълнено 2352 пъти. Очевидно сканирането би било по-добрият избор.
За да обобщя, бих казал, че подслушването на параметри е добро нещо, което трябва да се опитате да направите възможно най-често, като използвате параметри към вашите заявки. Понякога може да се обърка и в тези случаи най-вероятно се дължи на изкривени данни, които бъркат в статистическите ви данни.
Актуализация:
Ето една заявка срещу няколко dmv, които можете да използвате, за да намерите кои заявки са най-скъпи във вашата система. Променете към подреждане по клауза, за да използвате различни критерии за това, което търсите. Мисля, че TotalDuration е добро място за начало.
set transaction isolation level read uncommitted;
select top(10)
PlanCreated = qs.creation_time,
ObjectName = object_name(st.objectid),
QueryPlan = cast(qp.query_plan as xml),
QueryText = substring(st.text, 1 + (qs.statement_start_offset / 2), 1 + ((isnull(nullif(qs.statement_end_offset, -1), datalength(st.text)) - qs.statement_start_offset) / 2)),
ExecutionCount = qs.execution_count,
TotalRW = qs.total_logical_reads + qs.total_logical_writes,
AvgRW = (qs.total_logical_reads + qs.total_logical_writes) / qs.execution_count,
TotalDurationMS = qs.total_elapsed_time / 1000,
AvgDurationMS = qs.total_elapsed_time / qs.execution_count / 1000,
TotalCPUMS = qs.total_worker_time / 1000,
AvgCPUMS = qs.total_worker_time / qs.execution_count / 1000,
TotalCLRMS = qs.total_clr_time / 1000,
AvgCLRMS = qs.total_clr_time / qs.execution_count / 1000,
TotalRows = qs.total_rows,
AvgRows = qs.total_rows / qs.execution_count
from sys.dm_exec_query_stats as qs
cross apply sys.dm_exec_sql_text(qs.sql_handle) as st
cross apply sys.dm_exec_text_query_plan(qs.plan_handle, qs.statement_start_offset, qs.statement_end_offset) as qp
--order by ExecutionCount desc
--order by TotalRW desc
order by TotalDurationMS desc
--order by AvgDurationMS desc
;