Допълнение: SQL Server 2012 показва известна подобрена производителност в тази област, но изглежда не се справя с конкретните проблеми, отбелязани по-долу. Това очевидно трябва да бъде поправено в следващата основна версия след SQL Server 2012!
Вашият план показва, че единичните вмъквания използват параметризирани процедури (евентуално автоматично параметризирани), така че времето за анализ/компилиране за тях трябва да бъде минимално.
Мислех, че ще разгледам това малко повече, така че настройте цикъл (скрипт) и се опитах да коригирам броя на VALUES клаузи и записване на времето за компилиране.
След това разделих времето за компилиране на броя на редовете, за да получа средното време за компилиране на клауза. Резултатите са по-долу
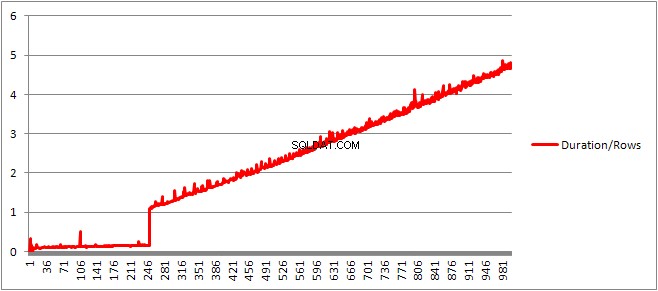
До 250 VALUES клаузите представят времето за компилиране / броя на клаузите има лека възходяща тенденция, но нищо твърде драматично.
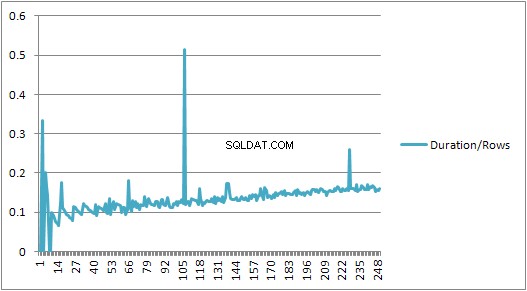
Но след това има внезапна промяна.
Този раздел от данните е показан по-долу.
+------+----------------+-------------+---------------+---------------+
| Rows | CachedPlanSize | CompileTime | CompileMemory | Duration/Rows |
+------+----------------+-------------+---------------+---------------+
| 245 | 528 | 41 | 2400 | 0.167346939 |
| 246 | 528 | 40 | 2416 | 0.162601626 |
| 247 | 528 | 38 | 2416 | 0.153846154 |
| 248 | 528 | 39 | 2432 | 0.157258065 |
| 249 | 528 | 39 | 2432 | 0.156626506 |
| 250 | 528 | 40 | 2448 | 0.16 |
| 251 | 400 | 273 | 3488 | 1.087649402 |
| 252 | 400 | 274 | 3496 | 1.087301587 |
| 253 | 400 | 282 | 3520 | 1.114624506 |
| 254 | 408 | 279 | 3544 | 1.098425197 |
| 255 | 408 | 290 | 3552 | 1.137254902 |
+------+----------------+-------------+---------------+---------------+
Размерът на кеширания план, който нараства линейно, внезапно спада, но CompileTime се увеличава 7 пъти и CompileMemory изстрелва нагоре. Това е точката на прекъсване между плана, който е автоматично параметризиран (с 1000 параметъра) до непараметризиран. След това изглежда става линейно по-малко ефективен (по отношение на броя на стойностните клаузи, обработени за дадено време).
Не знам защо това трябва да бъде. Вероятно, когато съставя план за конкретни буквални стойности, той трябва да извърши някаква дейност, която не се мащабира линейно (като сортиране).
Изглежда, че не влияе на размера на кеширания план за заявка, когато опитах заявка, състояща се изцяло от дублиращи се редове и нито едно не влияе на реда на изхода на таблицата с константи (и докато вмъквате в купа време, прекарано в сортиране така или иначе би било безсмислено, дори и да е така).
Освен това, ако към таблицата се добави клъстериран индекс, планът все още показва изрична стъпка за сортиране, така че изглежда не се сортира по време на компилиране, за да се избегне сортиране по време на изпълнение.

Опитах се да разгледам това в дебъгер, но публичните символи за моята версия на SQL Server 2008 изглежда не са налични, така че вместо това трябваше да погледна еквивалентния UNION ALL конструкция в SQL Server 2005.
Типично проследяване на стека е по-долу
sqlservr.exe!FastDBCSToUnicode() + 0xac bytes
sqlservr.exe!nls_sqlhilo() + 0x35 bytes
sqlservr.exe!CXVariant::CmpCompareStr() + 0x2b bytes
sqlservr.exe!CXVariantPerformCompare<167,167>::Compare() + 0x18 bytes
sqlservr.exe!CXVariant::CmpCompare() + 0x11f67d bytes
sqlservr.exe!CConstraintItvl::PcnstrItvlUnion() + 0xe2 bytes
sqlservr.exe!CConstraintProp::PcnstrUnion() + 0x35e bytes
sqlservr.exe!CLogOp_BaseSetOp::PcnstrDerive() + 0x11a bytes
sqlservr.exe!CLogOpArg::PcnstrDeriveHandler() + 0x18f bytes
sqlservr.exe!CLogOpArg::DeriveGroupProperties() + 0xa9 bytes
sqlservr.exe!COpArg::DeriveNormalizedGroupProperties() + 0x40 bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x18a bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x146 bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x146 bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x146 bytes
sqlservr.exe!CQuery::PqoBuild() + 0x3cb bytes
sqlservr.exe!CStmtQuery::InitQuery() + 0x167 bytes
sqlservr.exe!CStmtDML::InitNormal() + 0xf0 bytes
sqlservr.exe!CStmtDML::Init() + 0x1b bytes
sqlservr.exe!CCompPlan::FCompileStep() + 0x176 bytes
sqlservr.exe!CSQLSource::FCompile() + 0x741 bytes
sqlservr.exe!CSQLSource::FCompWrapper() + 0x922be bytes
sqlservr.exe!CSQLSource::Transform() + 0x120431 bytes
sqlservr.exe!CSQLSource::Compile() + 0x2ff bytes
Така че като изключим имената в трасирането на стека, изглежда, че прекарва много време в сравняване на низове.
Тази KB статия показва, че DeriveNormalizedGroupProperties се свързва с това, което се наричаше етап на нормализиране на обработката на заявки
Този етап сега се нарича обвързване или алгебризиране и взема изхода на дървото за синтактичен анализ на израза от предишния етап на синтактичен анализ и извежда алгебризирано дърво на изрази (дърво на процесора на заявки), за да премине напред към оптимизация (тривиална оптимизация на план в този случай) [ref].
Опитах още един експеримент (скрипт), който трябваше да стартирам отново оригиналния тест, но разглеждах три различни случая.
- низове за собствено и фамилно име с дължина 10 знака без дубликати.
- низове за собствено и фамилно име с дължина 50 знака без дубликати.
- низове за собствено и фамилно име с дължина 10 знака с всички дубликати.
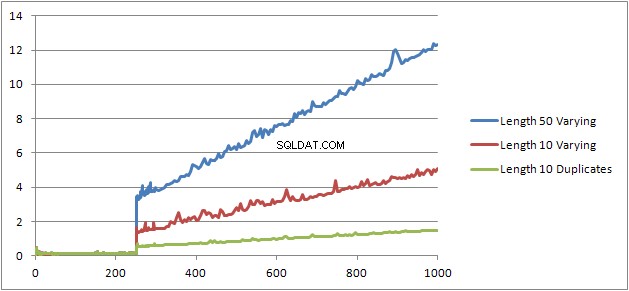
Ясно се вижда, че колкото по-дълги са струните, толкова по-лоши стават нещата и обратното, колкото повече дубликати, толкова по-добри стават нещата. Както беше споменато по-горе, дубликатите не влияят на размера на кеширания план, така че предполагам, че трябва да има процес на идентификация на дублирания при конструирането на самото алгебризирано дърво на изрази.
Редактиране
Едно място, където се използва тази информация, е показано от @Lieven тук
SELECT *
FROM (VALUES ('Lieven1', 1),
('Lieven2', 2),
('Lieven3', 3))Test (name, ID)
ORDER BY name, 1/ (ID - ID)
Тъй като по време на компилиране може да определи, че Name колоната няма дубликати, тя пропуска подреждането по вторичния 1/ (ID - ID) израз по време на изпълнение (сортирането в плана има само един ORDER BY колона) и не се повдига грешка при деление на нула. Ако към таблицата се добавят дубликати, тогава операторът за сортиране показва два реда по колони и се появява очакваната грешка.